AI
LiT: Zero-Shot Transfer with Locked-image text Tuning [5]
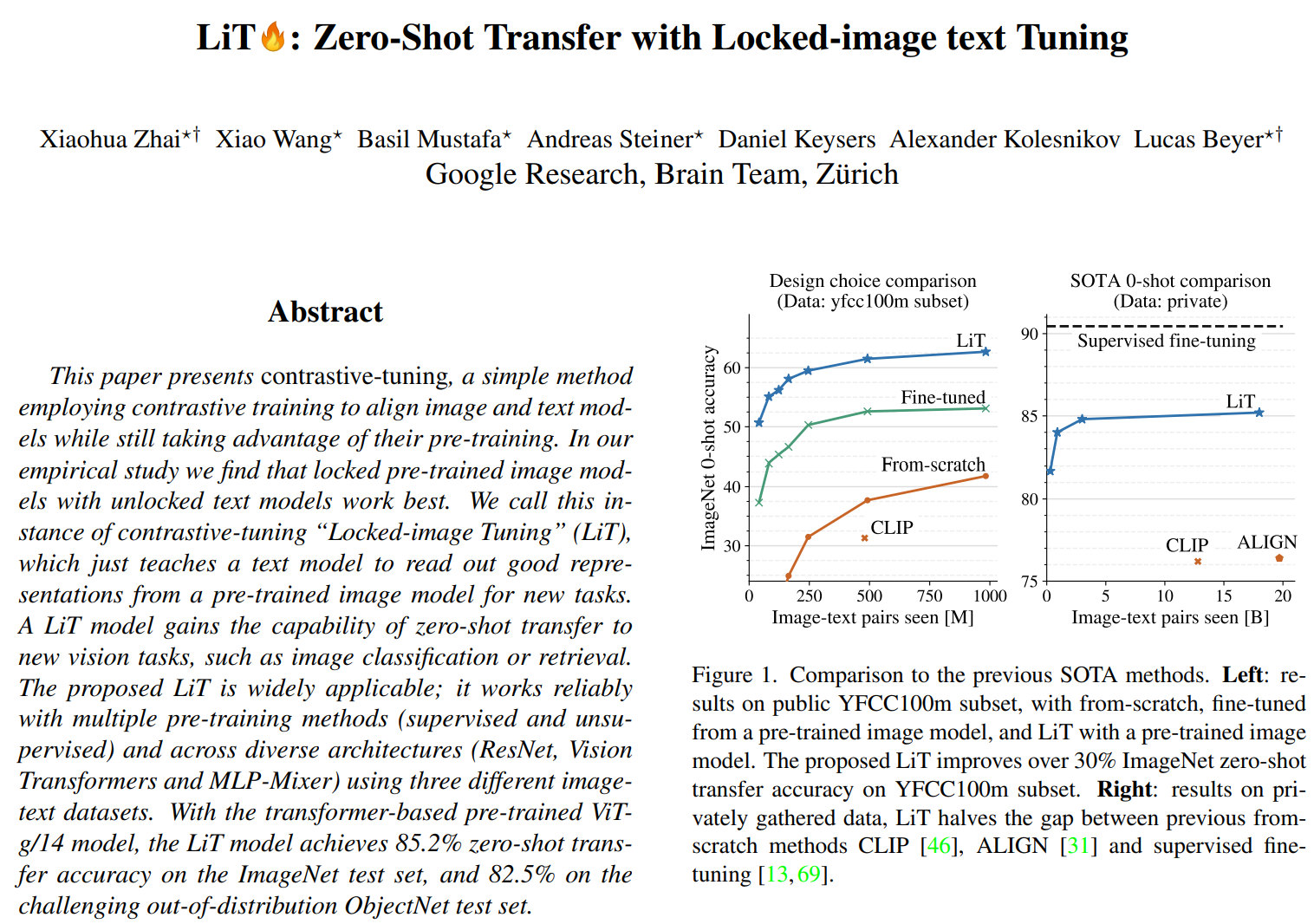
이 논문은 constrastive-tuning이라는 간단한 방법을 활용한다. constrastive(대조적인) training을 통해서 이미지와 텍스트 모델을 학습하여 pre-training의 장점을 갖는다. Locked pre-trined 이미지 모델과 unlocked 텍스트 이미지 모델을 함께 쓰는 것이 가장 효과적이다. 이러한 기법을 contrastive-tuning의 Locked-image Tuning(LiT)라 한다. 이 기법은 텍스트 모델에게 pre-trained 이미지 모델에서 좋은 표현을 읽어 와서 새로운 작업에 활용하도록 가르친다. LiT 모델은
zero-shot transfer능력을 새로운 vision 태스크(classification, retrieval)에서 얻게 된다. 제안된 LiT는 넓게 쓰일 수 있고, 다중(multiple) pre-training methods(supuervised, unsupervised)와 across diverse architecture(ResNet, ViT, MLP-Mixer)에서 3개의 다른 이미지-텍스트 데이터셋에서 실험해 신뢰성을 얻었다.

Locked / Unlocked
주요 아이이디어는 pre-trained 강한 이미지 모델을 image tower로 사용하면서 image-text 데이터를 이용하는 text tower를 튜닝하는 것이다. 아래 그림은 학습할 떄 두 tower의 모습을 모여준다.
- L (locked weights, a initialized from pre-trained model)
- U (unlocked/trainable weights, initialized from a pre-trained model)
- u (unlocked/trainable weights, randomly initialized).
Constrastive pre-training
이미지 콜렉션(collections)은 free-form 텍스트 묘사/표현(descriptions)와 짝지어져 visual model을 학습하는데 강력한 자원역할을한다. 주요 이점은 유한하게 사전정의된 카테고리에 제한되지 않고, open-ended 자연어를 통해 이미지를 묘사할 수 있다. 결과적으로, 이 데이터로부터 학습한 이 모델은 zero-shot learner의 역할을 하게 되어 광범위한 태스크를 학습할 수 있다.
핵심 개념은 이미지와 텍스트 임베딩 모델이 같은 dimestioninality로 표현을 만든다. 이 두 표현은 constrative loss를 학습하고, 상응하는 이미지와 텍스트 짝이 비슷한 임베딩과 상응하지 않는 짝은 구분되도록 임베딩 시킨다.
Reference
[1] Alexey Dosovitskiy, et al, An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR, 2021.
[2] Ilya Tolstikhin, et al, MLP-Mixer: An all-MLP Architecture for Vision, CVPR, 2021.
[3] Andreas Steiner, et al, How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers, CVPR, 2022.
[4] Xiangning Chen, et al, When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations, CVPR, 2022.
[5] Xiaohua Zhai, et al, LiT: Zero-Shot Transfer with Locked-image text Tuning, CVPR, 2022.
[6] Juntang Zhuang, Surrogate Gap Minimization Improves Sharpness-Aware Training, ICLR, 2022.
