Segmentation
Segmentation이란, Bounding box를 구하는 것에 만족하지 않고 픽셀 레벨에서 어디까지 객체에 해당하는지 예측하는 것을 의미한다.
Semantic Segmentation과 Instance Segmentation으로 구분되며, Sementic Segmentation은 의미적으로 무엇에 해당하는지만 분류하고, Instance Segmentation은 여러 마리 강아지가 있으면 각 객체를 다른 객체로 인식하는 것까지의 과정을 포함한다.
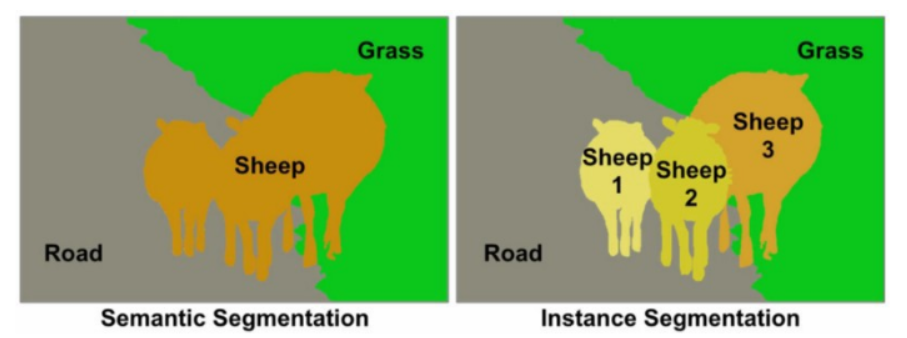
Sementic Segmentation
Fully Convolutional Network (FCN)
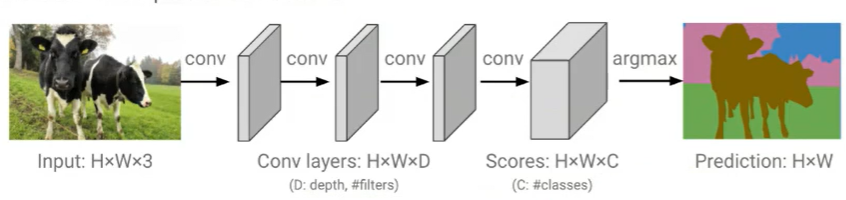
Fully Convolutional Network는 Classification에서 성능을 검증 받은 기존의 네트워크(ex. AlexNet, VGGNet, GoogLeNet)를 이용하되, 네트워크의 마지막에 FC Layer를 삽입하지 않고, Convolution Layer로 대체하는 모델을 의미한다.
FC Layer를 사용하면 고정된 크기의 입력을 받아야 하고, 모든 노드들이 서로 곱해진 후 더해지는 연결 때문에 위치 정보가 손실되는 문제가 존재하기 때문에 이를 해결하고자 FC Layer를 없애자는 아이디어에서 시작한 것이 FCN이다.
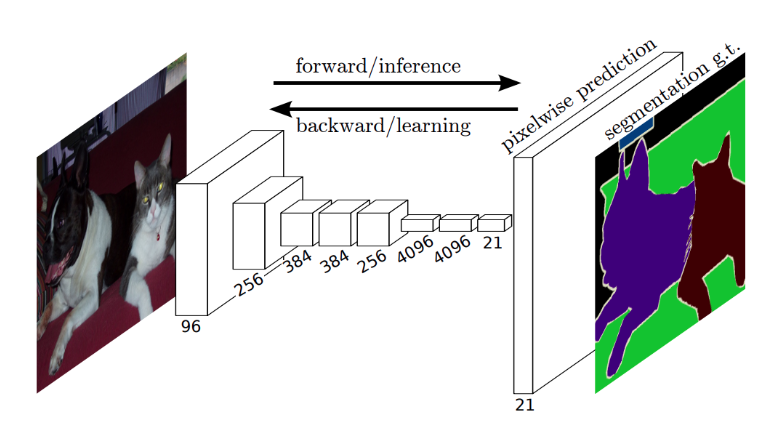
아래의 그림을 보면, FC Layer를 포함한 구조에선 출력이 정답 카테고리별 확률을 나타내며 위치 정보가 존재하지 않는 반면에, FC layer를 Convolution Layer로 변경한 구조에선 고양이가 있어야 하는 곳에 위치 정보가 남아있는 heatmap이 출력으로 나타나는 것을 확인할 수 있다.
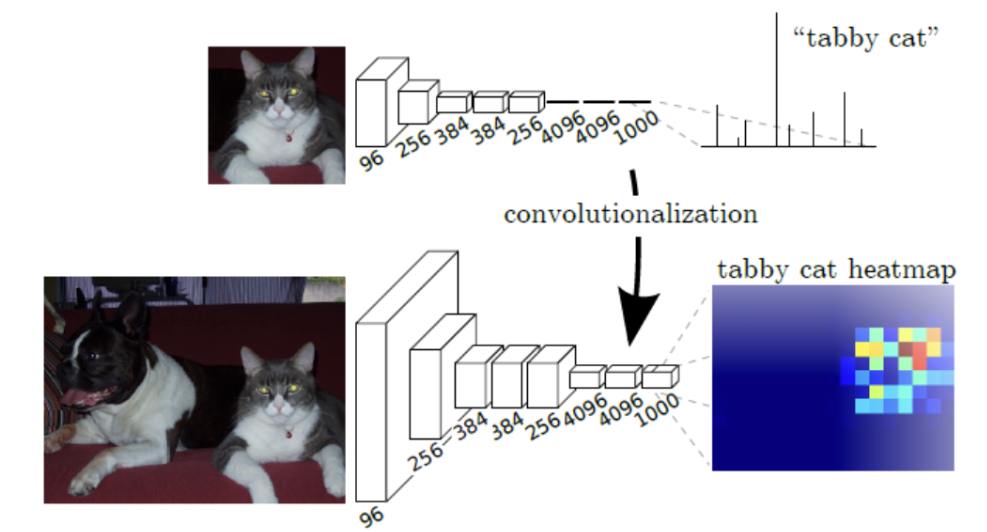
FCN의 끝은 1x1의 kernel size와 class 개수 만큼의 channel을 지닌 컨볼루션 계층으로 구성된다. 이렇게 예측된 Feature map의 size를 input size와 맞추기 위해 upsampling하여 Segmentation 결과를 얻는다.
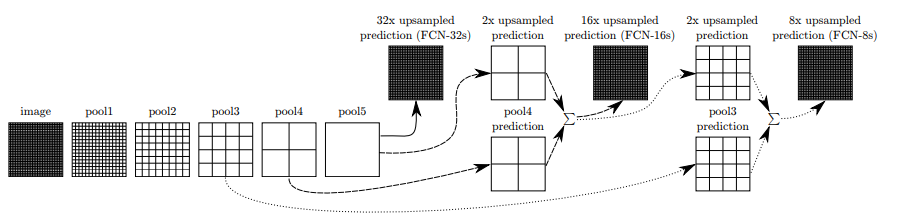
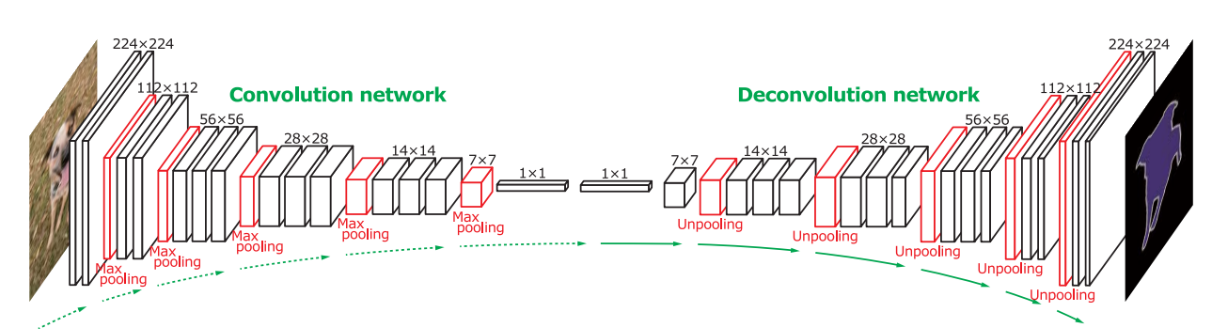
아래 그림을 보면, 입력 이미지는 pool5까지 점진적으로 다운샘플링되면서 특징을 추출한다. 이후, pool5의 Feature Map을 32배 업샘플링하여 예측을 수행하는 것이 FCN-32s이다. 하지만 이 방법은 공간적 정보가 손실될 가능성이 크다.
이를 보완하기 위해 pool5의 Feature Map을 2배 업샘플링한 후, pool4의 정보를 결합(skip connection)하여 16배 업샘플링하는 방식이 FCN-16s이다.
마지막으로, pool5의 Feature Map을 2배 업샘플링한 후 pool4의 정보를 결합, 다시 2배 업샘플링하여 pool3의 정보를 추가 결합한 뒤, 8배 업샘플링하여 최종 예측을 수행하는 것이 FCN-8s이다. 이처럼 여러 단계의 Skip Connection을 활용하면 더 세밀한 공간 정보를 보존할 수 있으며, FCN의 성능을 점진적으로 향상시킬 수 있다.
다만, 이러한 FCN은 큰 Object의 경우 전체가 아니라 일부분만 정답으로 예측하여 같은 Object여도 다른 Object로 예측하고, 작은 Object의 경우 아예 무시하는 문제와, Object의 디테일한 모습이 사라지는 문제가 존재했으며, 이는 고정된 Receptive Field와 단순한 Deconvolution 때문에 발생한다.

Deconvolution (Transpose Convolution, Transposed Convolution)
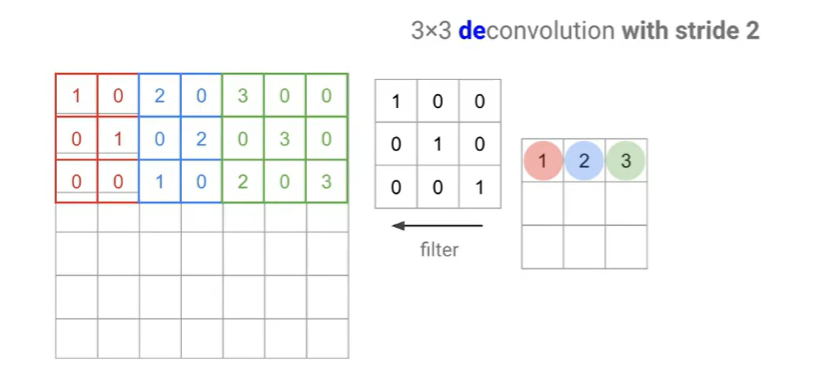
- Convolution 연산의 반대 개념으로, 작은 Feature Map을 큰 Feature Map으로 변환하는 것을 의미함.
- 커널을 이동하면서 출력 픽셀을 겹쳐서 합산하는 과정을 거쳐 upsampling을 수행함.
- 만약 겹치는 부분이 있다면 합산하여 표현
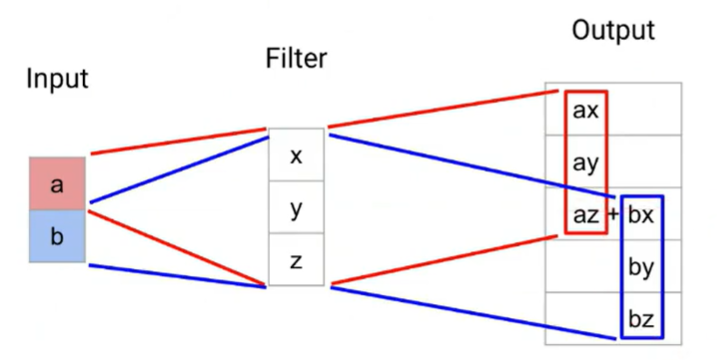
Deconvolution Network
- CNN의 역연산을 수행해 입력 이미지를 복원하는 모델로, 업샘플링을 위한 Deconvolution(Transpose Convolution) 연산을 기반으로 동작함.
- CNN은 입력 이미지를 Feature Map으로 변환하면서 다운샘플링되며, DeconvNet은 CNN의 역연산을 수행하여 다운샘플링된 Feature Map을 원본 크기로 복원함.
- 시작과 끝은 같은 dimension을 유지함.
- 중간에 줄였다가 다시 확대되는 형태를 지님. (대칭 형태)
- 인코더는 VGG16에서 마지막 FC Layer를 제거한 형태이며, 하나의 Conv은 Convolution → BatchNorm → ReLU 구조를 지님.
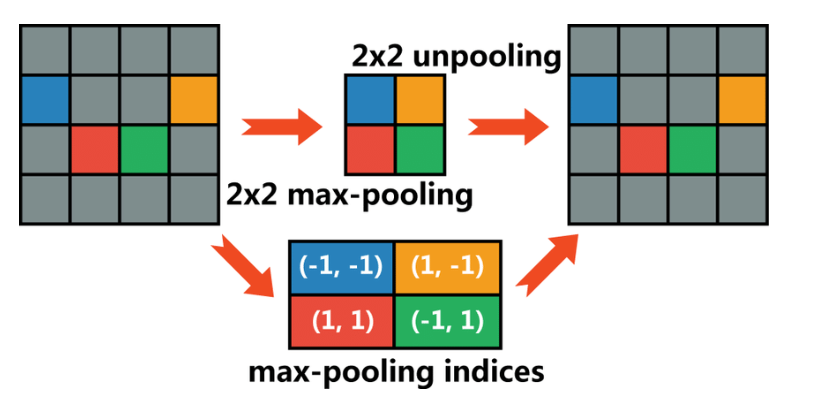
- Max Pooling 시 많은 정보를 소실한다는 단점을 극복하기 위해 Pooling 시 지워진 경계의 위치 정보를 저장했다가 Unpooling 시 이를 활용하고, 이를 기반으로 업샘플링을 진행함.
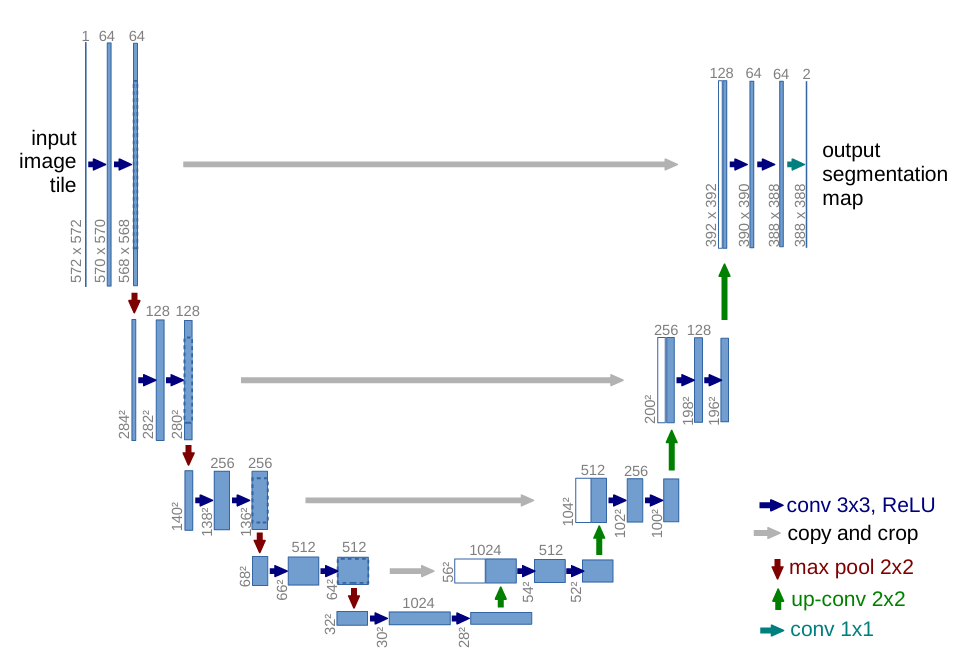
U-Net
- FCN을 기반으로 하되, 정교한 세그멘테이션을 위해 업샘플링 과정에서 Skip Connection을 활용함.
- 인코더 (Contracting path)
- conv 사이즈 줄이는 과정에서 이미지의 context를 포착 (전형적인 CNN 아키텍처 형태를 따름)
- 3*3 컨볼루션(패딩되지 않은 컨볼루션)의 반복 적용
- 각 단계 이후엔 ReLU, 2*2 Max Pooling 연산을 진행하며, 각 다운 샘플링 단계에선 채널 수를 두 배로 늘림.
- 디코더 (Expanding path)
- Feature Map을 upsampling하고, 인코더에서 포착한 Feature Map과 Skip connection을 통해 결합
- input, output 크기가 다름.
Overlapping Tile Strategy
- U-Net은 입력 이미지 크기에 제한이 없는데, 만약 이미지가 너무 크다면 메모리 문제로 이미지를 패치 단위로 분리해야 함.
- 이를 해결하기 위해 이미지를 타일 단위로 나누어 처리하되, 타일 간에 겹치는 부분이 존재하도록 이미지를 분할하여 연결시킴.
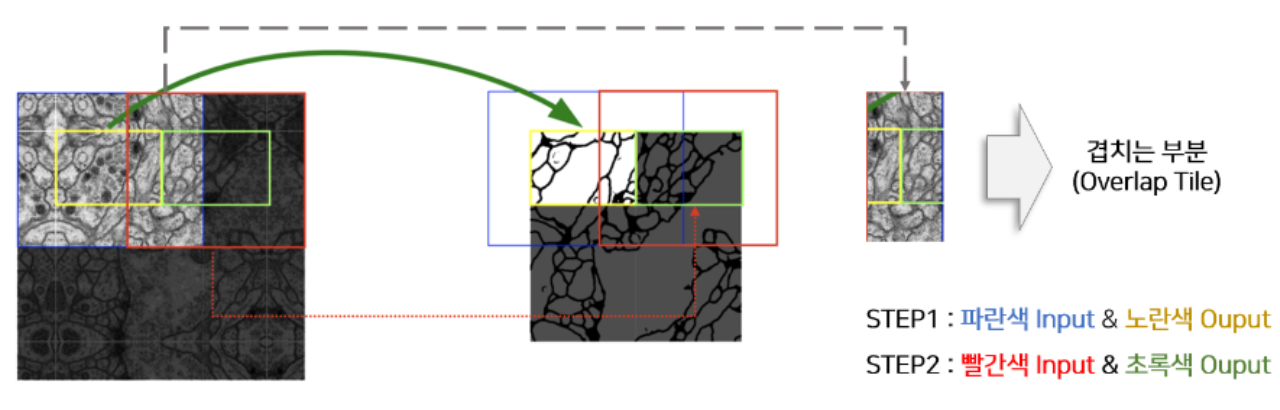
Mirroring Padding
- U-Net에선 Zero Padding 대신 Mirroring Padding을 사용하여 경계를 반사해 패딩을 추가함.
- 즉, 이미지의 가장자리 픽셀을 복사하여 패딩을 채우는 방식을 사용함.
Instance Segmentation
- Instance Segmentation = Object Detection + Sementic Segmentation
Mask R-CNN
Instance Segmentation은 모든 객체들에 대한 정확한 Detection과 Segmentation이 이루어져야 하기에 어려움이 존재했으나, Mask R-CNN은 Faster R-CNN에 Small FCN으로 구성된 Mask branch를 추가한 단순하고 빠른 아키텍처로 Instance Segmentation에 대해 좋은 성능을 보였으며, 픽셀 단위의 Segmentation을 위해 RoI Pooling을 RoIAlign으로 대체해 공간 정보를 보존할 수 있도록 했다.
- Mask R-CNN = Faster R-CNN + mask branch
- 각 RoI에 대해 픽셀 단위 Segmentation mask를 예측하는 branch를 추가함.
- 이때, mask branch는 classification, bounding box regression branch와 독립적이며, small FCN으로 구성됨.
- Fast R-CNN은 픽셀 단위의 Segmentation을 위해 설계되지 않았으므로, 이를 해결하기 위해 RoIAlign을 사용함.
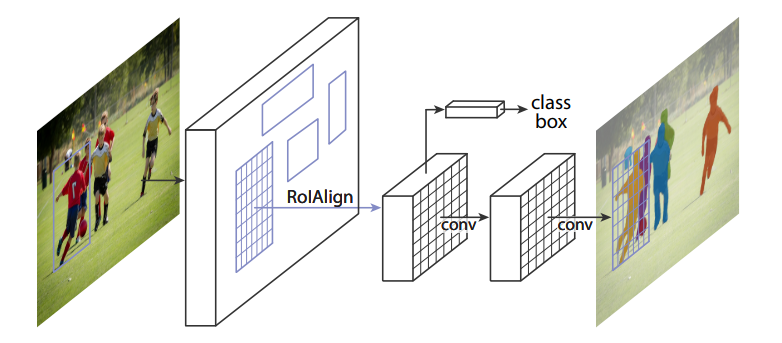
- 아래의 구조를 보면, Classification과 BBox를 예측하는 기존의 Faster R-CNN에 Mask Branch가 병렬적으로 연결된 것을 확인할 수 있다.
- 이러한 Mask Branch는 FCN 기반 CNN을 적용하며, Bounding Box 내부에서 픽셀 단위로 객체를 분할하기 위해 존재한다.
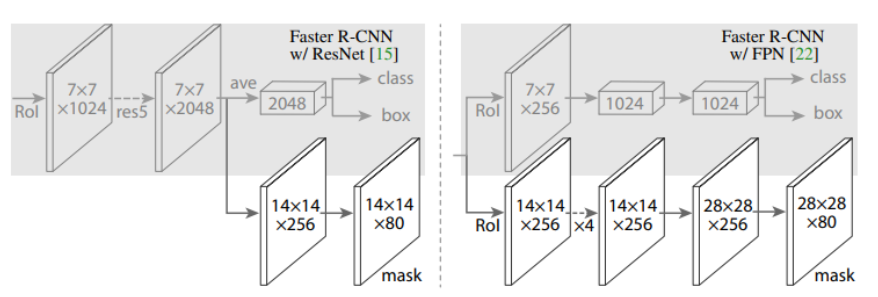
RoIAlign
기존의 ROI Pooling은 반올림으로 인해 위치 정보에 혼란이 올 수 있어 픽셀 단위로 segmentation을 진행해야 하는 마스크를 예측하는 task에서 부정적인 효과를 가져온다.
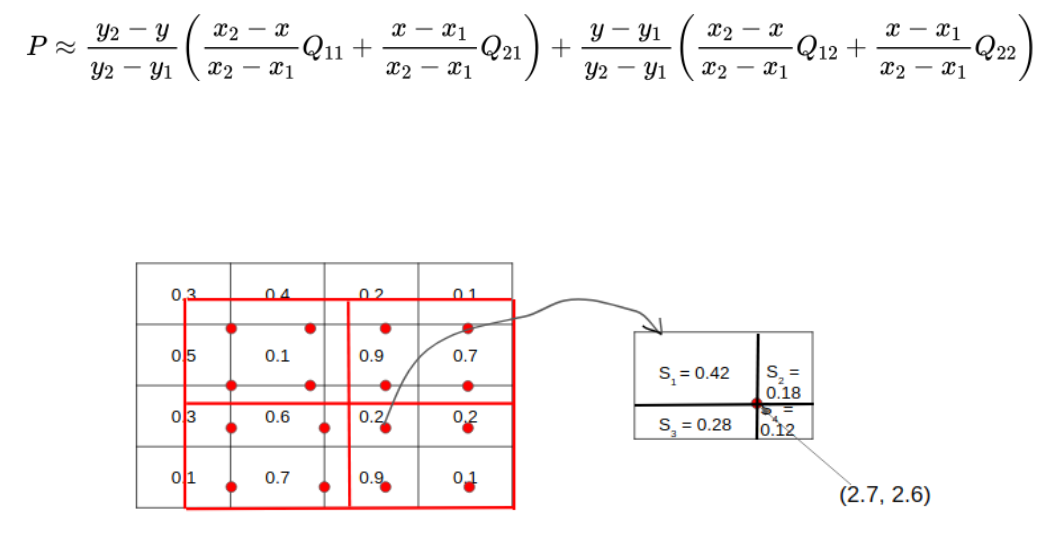
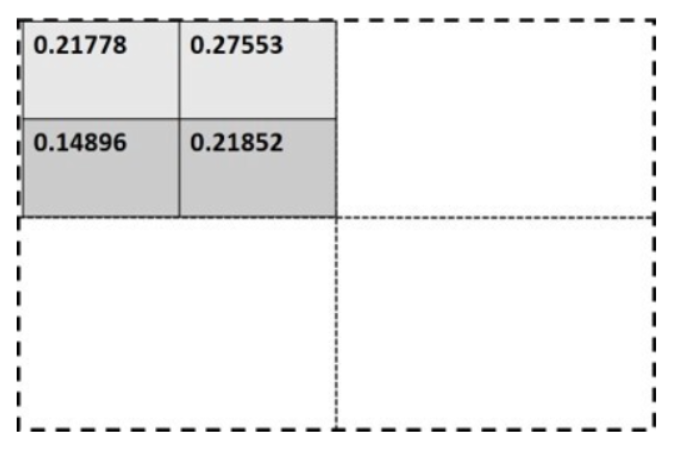
이런 문제를 Mask R-CNN에선 ROI Pooling을 RoIAlign으로 대체하여 해결한다. 이는 나눠진 각 그리드에 대해 sample point를 잡고, 포인트 하나를 기준으로 가까운 그리드 셀 4개에 대해 선형 보간법(Bilinear Interpolation)을 적용하여 Feature Map을 계산하는 것이다.
이 과정을 모든 sample point에 대해 진행하면, 하나의 영역에 4개의 값이 생겨나는데, 여기서 max 또는 average pooling을 사용해 output을 얻어낸다.
이렇게 반올림하지 않고도 RoI 처리를 고정된 사이즈의 Feature Map으로 생성하는 것을 RoIAlign이라고 한다.