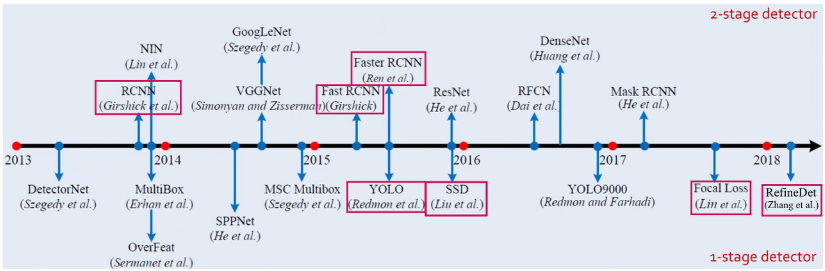
Object Detection
Object Detection이란 이미지나 영상에서 여러 개의 객체를 찾아내고, 각 객체의 위치와 클래스를 예측하는 기술을 의미한다.
기존의 Classification 문제는 하나의 Object에 대해 분류를 수행하며, Spatial Localization(이미지에서 특정 객체의 Bounding Box 좌표를 예측하는 과정)가 필요하지 않다.
Object Detection은 기존의 Classification과 달리 여러 개 객체를 탐지할 수 있으며, 객체가 어디에 있는지 Bounding Box를 탐지하고, Bounding Box 안의 객체가 무엇인지 Classification을 수행하고, 분류한 객체에 대한 Confidence Score를 구한다.

이러한 Object Detection은 Proposal-based model(Two-stage model)과 Proposal-free model(One-stage model)로 구분된다.
Proposal-based model은 후보 영역(Region Proposal)들을 명시적으로 만들고, 2차적으로 후보 박스들을 분류하는 모델을 의미한다. R-CNN 계열 모델(Fast R-CNN, Faster R-CNN)처럼 Region Proposal을 먼저 찾은 후 분류하는 방식을 지니는 모델들이 이에 해당한다.
Proposal-free model은 별도의 Region Proposal 과정 없이, 이미지를 한 번만 처리하여 객체를 탐지하는 방식을 의미한다. YOLO, SSD와 같은 모델들이 이에 해당한다.
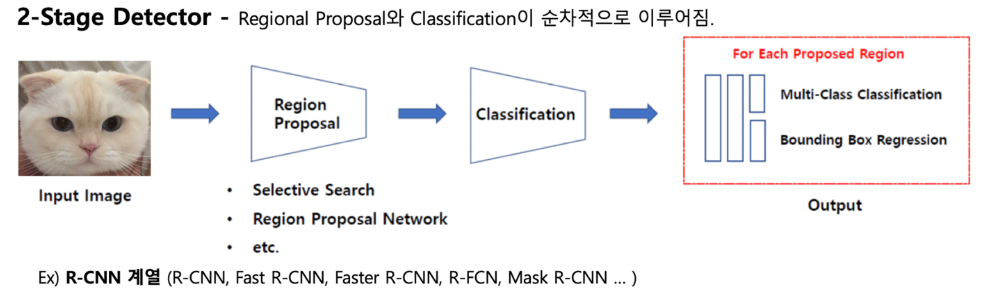
Proposal-based model (Two-stage model)
Proposal-based 모델은 객체를 탐지하기 위해 먼저 Region Proposal 단계에서 객체가 있을 가능성이 높은 후보 영역을 찾고, 이후 Classification 단계에서 후보 영역을 정제하여 최종적으로 객체를 분류한다.
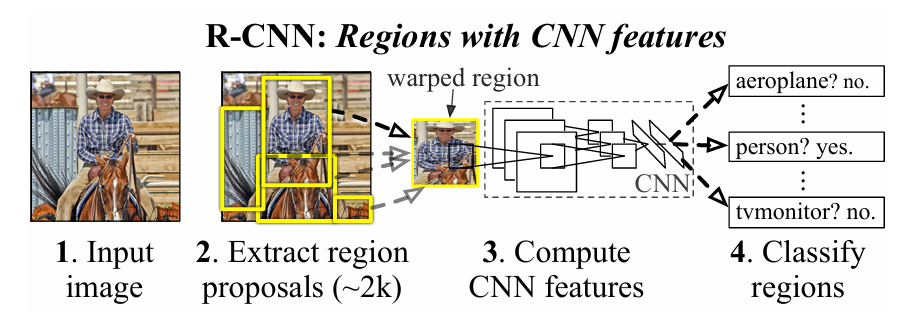
R-CNN (Regions with CNN features)
① Stage 1 : Region proposal
- off-shelf model을 활용해 객체가 있을 가능성이 높은 후보 영역을 찾는다. (약 2000개 가량의 후보 영역 추출)
- Selective search, EdgeBoxes, MCG 등
- 추출된 각 영역을 Crop, 동일한 사이즈로 Resize
-> Classification이나 Regression을 하기 위해선 고정된 길이의 벡터로 만들어 주어야 하기 때문
② Stage 2 : Object recognition
- Crop & Resize된 이미지가 CNN의 Input으로 입력됨.
- CNN 모델을 통해 feature를 추출하고, 클래스를 맞추는 Classifier과 물체의 위치를 맞추는 Regression 진행
장점
- 딥러닝을 사용한 최초의 detection 모델
- 기존의 sliding window 방식처럼 모든 영역에 CNN을 적용하는 게 아니라, Region Proposal 방식을 도입하여 의미 있는 영역만 골라 CNN을 적용했기 때문에 기존의 brute-force 방법보다 비용이 상당히 줄어듦.
단점
- image에서 추출된 Region이 모두 CNN을 거쳐야 하기 때문에 시간과 비용 문제 발생
- Region Proposal 자체의 계산 비용이 상당히 많이 듦.
Fast R-CNN
① Stage 1 : Region proposal
- 기존의 R-CNN과 동일
② Stage 2 : Object recognition
- 이미지를 Crop하지 않고, 전체 이미지를 CNN 모델을 통해 한 번만 처리하여 Feature Map를 추출하고, ROI Pooling을 사용해 Region Proposal 단계에서의 후보 영역을 Feature Map 상에서 선택하고, Classification & Regression 진행
- Feature를 원본 이미지에서 Crop하는 것이 아니라 Feature Map단에서 추출하기에 CNN 수행 횟수가 감소함.
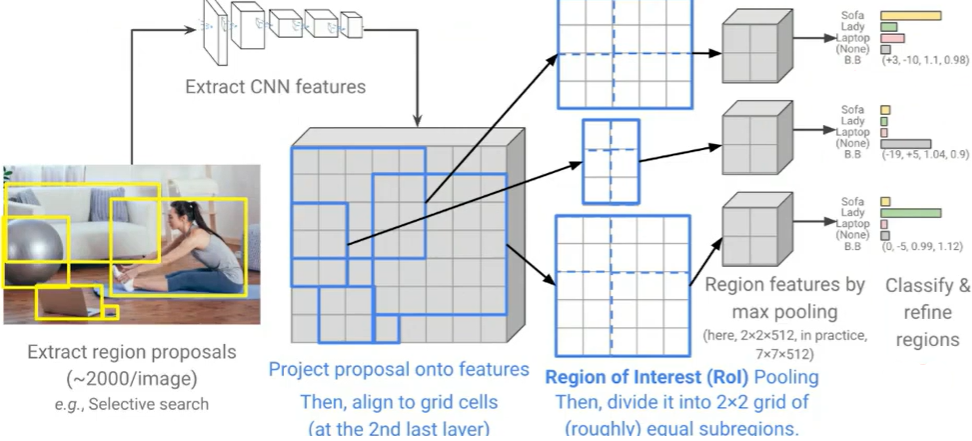
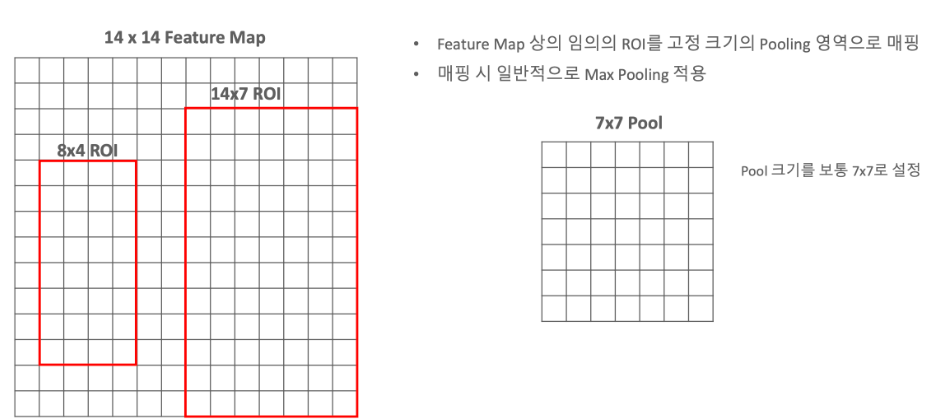
ROI Pooling이란?
-> 이미지 내의 RoI에서 고정된 크기의 Feature Map을 추출하는 과정으로, RoI를 고정된 수의 구역으로 분할하고, 각 구역에서 Max Pooling을 추출하여 고정된 크기의 작은 Feature Map을 생성한다.
(ex) 14x7의 ROI에 대해 7x7의 결과를 내는 ROI Pooling을 해야 한다면, 2x1마다 Max Pooling 수행
- 만약 나누어 떨어지지 않는다면, 좌표를 정수 단위로 반올림하여 근사적으로 셀을 할당함.
장점
- 기존 R-CNN보다 정확도 향상
- Training 시간이 8~18배 빨라지고, Inference 시간은 80~213배 빨라짐.
- 메모리 사용량 감소
단점
- Region Proposal 단계는 여전히 R-CNN과 동일 → 속도 한계 (Region Proposal 단계가 CPU 상에서 동작하기 때문에 네트워크 병목 현상 발생)
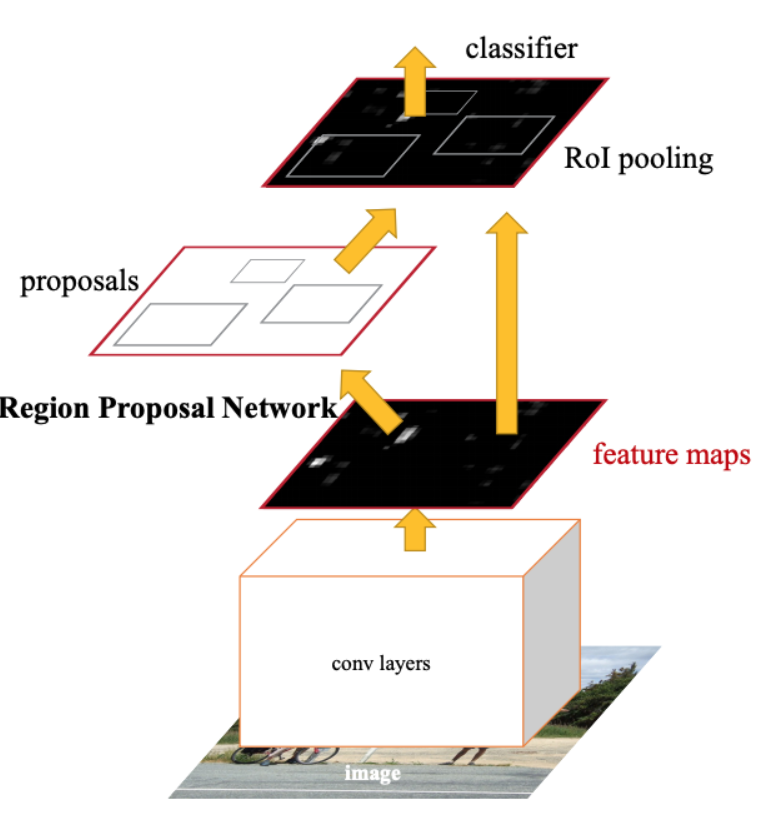
Faster R-CNN
- Convolutional Feature Map을 Region Proposal에도 공유함.
- 기존 conv layer에 추가적인 layer를 쌓아 Region proposal을 만들고 regression, objectness score를 계산함.
① Stage 1 : Training RPN (Region Proposal Network)
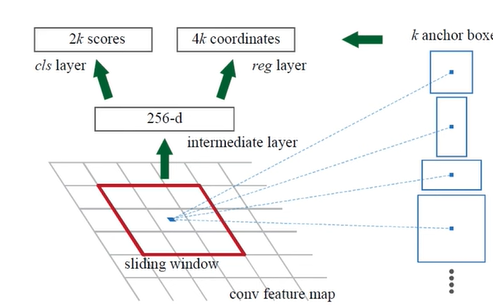
- RPN(Region Proposal Network)을 도입해 anchor를 자동으로 생성함.
RPN은 CNN을 통과시켜 얻은 Feature Map에서 직접 각 위치에 대해 다양한 크기와 비율의 Anchor Box를 설정한 뒤, Bounding Box를 조정하여 Region Proposal을 예측하는 방식이다.
- 3x3 sliding window를 적용하는 동시에, 각 window의 중심으로 anchor를 배치하며, 각 anchor마다 scale*ratio의 k개 anchor box를 생성해 input 이미지에 projection한다.
- 생성한 anchor box에 대해 IoU를 구해 Positive, Negetive, Invalid로 라벨을 구분한다.
- 결과는 anchor box 모두에 대해 레이블링을 한 vector
- Positive anchor에 한해, 해당하는 ground truth의 bounding box offset을 라벨링
- 결과적으로 Objectness Labeling과 Bbox offset Labeling이 생성됨.
② Stage 2 : Same as Fast R-CNN
- RPN이 생성한 Region Proposal을 Feature Map에서 선택해 가져오고, 이를 기반으로 RoI Pooling을 수행함.
- RoI Pooling 결과를 FC Layer에 입력 -> 객체 클래스와 Bounding Box 좌표를 출력함.
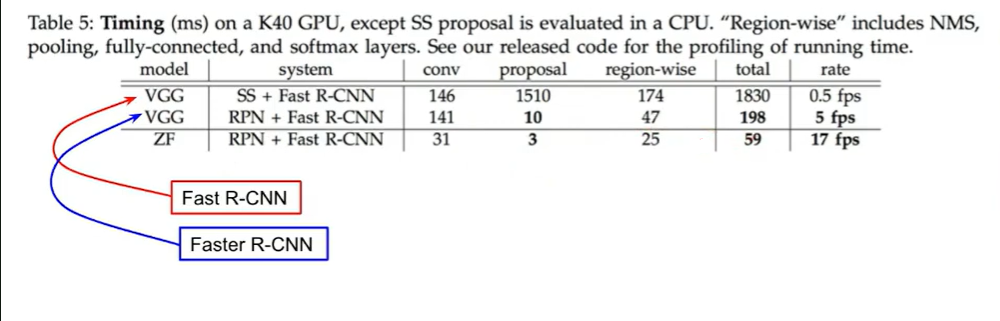
Faster R-CNN의 속도를 살펴보면, 딥한 모델을 사용했음에도 속도가 빠른 것을 확인할 수 있다.
Proposal-free model (One-stage model)
Proposal-free 모델은 객체 탐지를 단순화하기 위해 Region Proposal 없이 한 번의 처리로 Bounding Box와 Class를 예측한다.
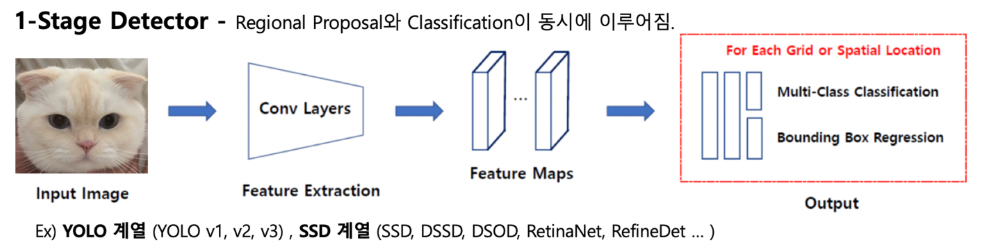
YOLO (You Only Look One)
YOLO는 Object Detection을 One-stage로 수행하는 대표적인 모델로, Detection을 regression한 문제로 접근한다.
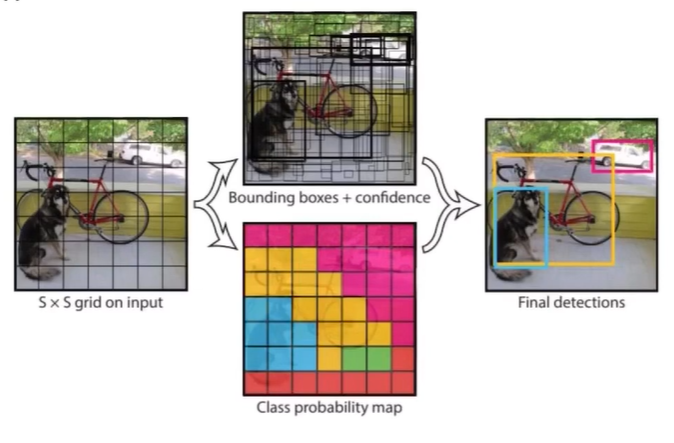
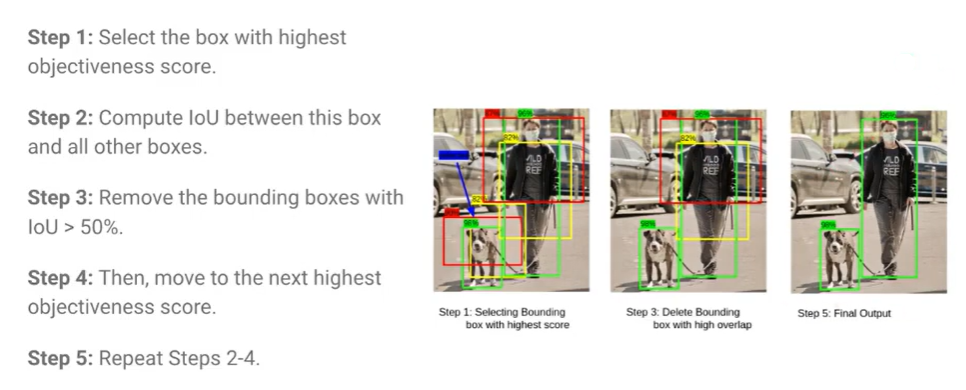
입력 이미지를 S × S 그리드로 나누고, 각 center에 들어가는 칸이 그 객체를 담당한다고 가정한다. 이후, 이미지를 통해 Bounding Box 좌표와 클래스 확률을 동시에 예측하고, NMS(Non-Maximum Suppression)을 사용해 가장 Confidence Score가 높은 박스를 남기고, 중복되는 박스를 모두 제거해 최종 탐지 결과를 도출한다.
- Unified Detection
- input 이미지를 S*S 그리드로 나누고, Bounding box regression과 Class probability map 계산이 병렬적으로 수행됨.
-
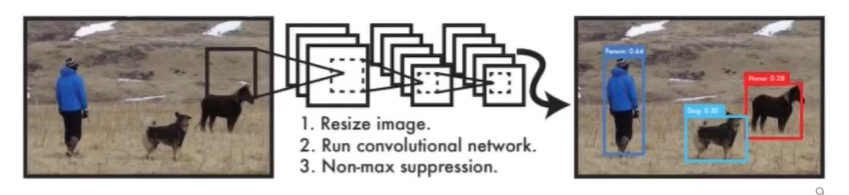
YOLO 모델의 inference 방식
-
NMS(Non-Maximum Suppression)
-
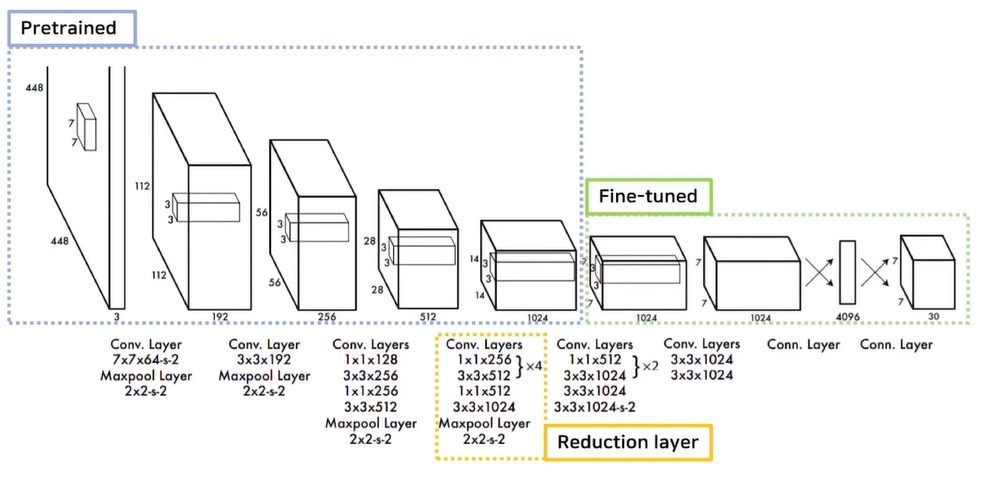
YOLO 네트워크 구조
SSD (Single Shot Detection)
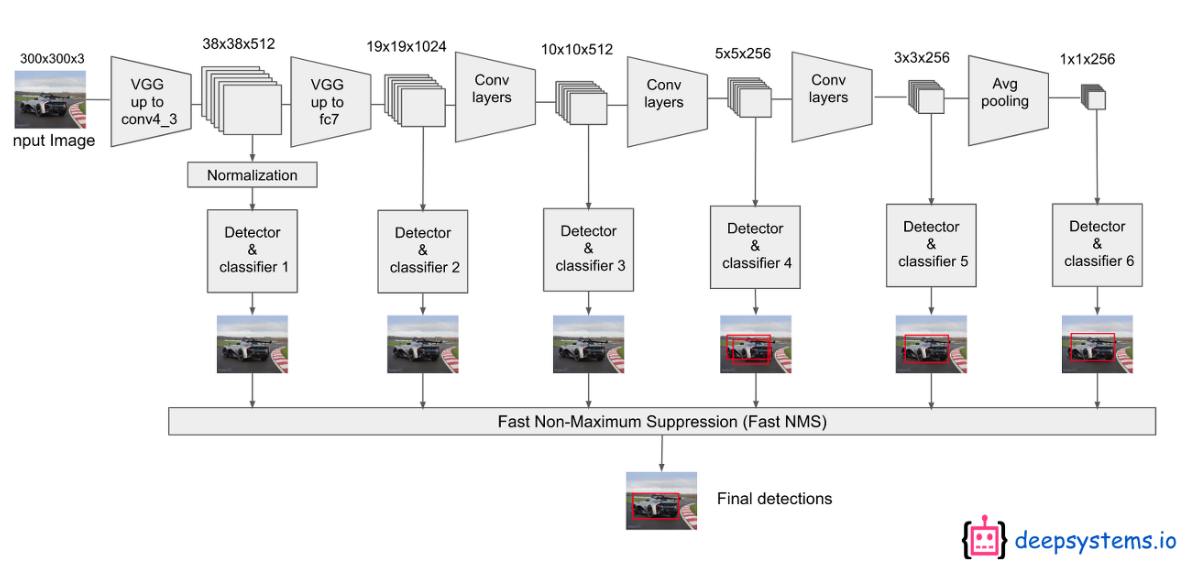
SSD는 YOLO와 비슷하지만, CNN을 통해 만들어진 Feature Map의 scale을 조절해 크기가 다른 객체를 잡아낼 수 있도록 했다. 작은 객체는 앞 Feature Map을 통해, 큰 객체는 뒤의 Feature Map을 통해 물체를 탐지할 수 있도록 하여 성능을 개선했다.
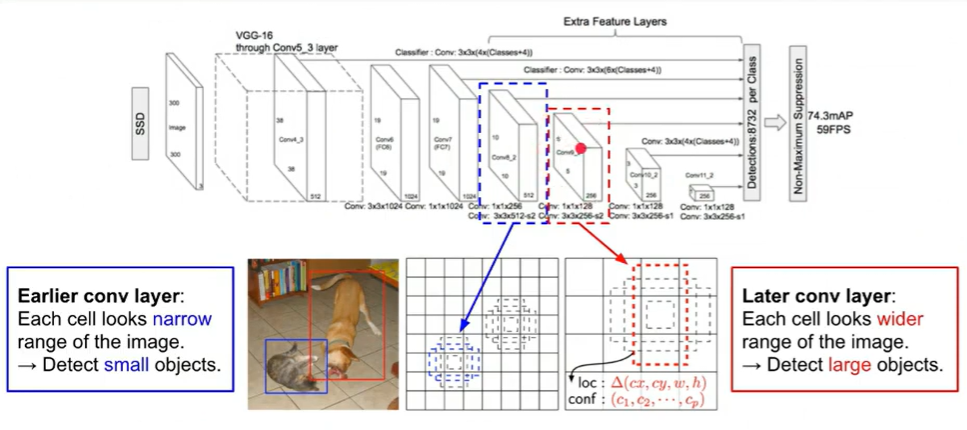
- 이때 각 Feature Map에서 여러 크기의 디폴트 박스를 활용해 다양한 크기의 물체를 인식한다.
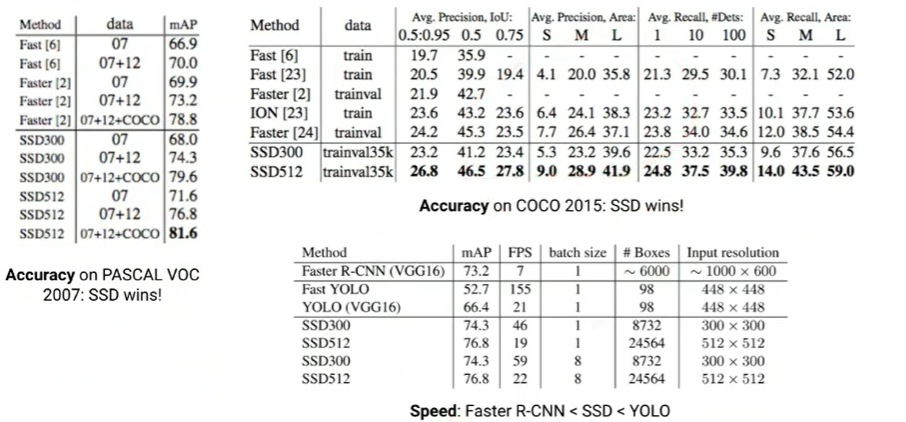
아래의 사진에서도 볼 수 있듯, YOLO는 속도에 치중된, SSD는 성능에 치중된 모델이다.
DETR
DETR은 CNN 기반의 기존 Object Detection 방식과 달리, Transformer 아키텍처를 활용한 모델로, Hand-design component(Anchor, NMS)를 모두 없애고 End-to-End 방식으로 학습한다.
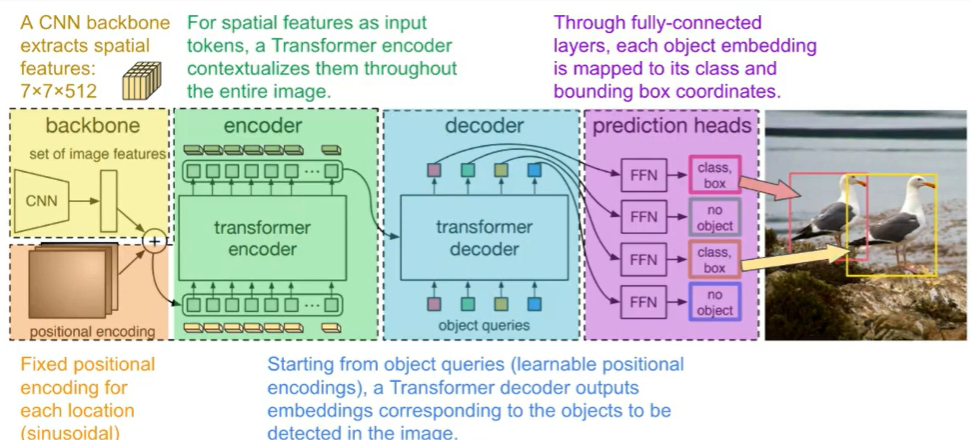
이러한 DETR은 별도의 Region Proposal 없이 End-to-End로 학습이 가능하며, 객체 간의 관계를 이해하는 데 강점이 있지만, 학습 속도가 느리고 small object detection 성능이 떨어진다는 단점이 있다.
