자연어를 컴퓨터에게 이해시키기 위해선 '단어의 의미'를 먼저 이해시켜야 한다.
시소러스를 활용한 기법
- 시소러스 : 유의어 사전으로, 동의어나 유의어가 한 그룹으로 분류됨. (ex) WordNet
- '상위와 하위', '전체와 부분' 등 세세한 관계까지 정의해 두기도 함.
- 모든 단어에 대한 유의어 집합을 만들고, 단어들의 관계를 그래프로 표현해 컴퓨터에게 단어 사이 관계 학습 (단어 네트워크)
- 시소러스는 단어의 의미 변화를 사람이 수작업으로 레이블링해야 하므로 시대 변화에 대응하기 어렵고, 단어의 미묘한 차이를 표현할 수 없다는 단점이 존재한다.
통계 기반 기법
- Corpus(대량의 텍스트 데이터)를 활용함.
- 사람의 지식으로 가득한 Corpus에서 자동으로, 효율적으로 핵심을 추출하는 것을 목표로 함.
단어의 분산 표현
- 단어를 고정 길이의 밀집 벡터(0이 아닌 실수인 벡터)로 표현해 단어의 의미를 정확하게 파악하는 벡터로 표현하는 것
분포 가설
- 단어의 의미는 주변 단어에 의해 형성된다는 가설
- 단어 자체에는 의미가 없고, 그 단어가 사용된 맥락이 의미를 형성하는 것임.
- 맥락 : 특정 단어를 중심에 둔 그 주변 단어
- 맥락의 크기(주변 단어를 몇 개나 포함할지) = 윈도우 크기
- 이때, 맥락의 크기는 좌우가 동수가 아닐 수 있다.
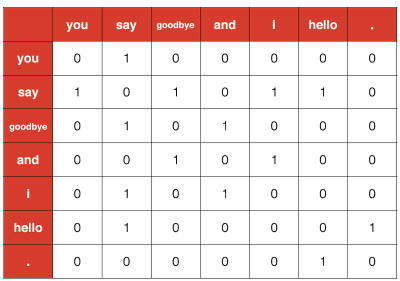
동시 발생 행렬
- 통계 기반 기법 : 어떤 단어에 주목했을 때, 그 주변에 어떤 단어가 몇 번이나 등장하는지를 세어 집계하는 방법
- 모든 단어에 대해 동시 발생하는 단어를 표에 정리하며, 표의 각 행은 해당 단어를 표현한 벡터가 됨.
- 표가 행렬의 형태를 띤다는 뜻에서 동시 발생 행렬이라고 함.
벡터 간 유사도
- 단어 벡터의 유사도를 나타낼 때는 코사인 유사도(두 벡터가 가리키는 방향이 얼마나 비슷한가)를 자주 이용함.
- 두 벡터의 방향이 완전히 같다면 코사인 유사도=1, else -1
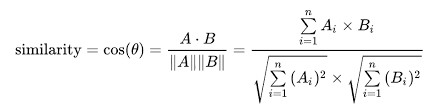
통계 기반 기법 개선
상호 정보량
-
동시 발생 행렬의 원소는 두 단어가 동시에 발생한 횟수를 나타내지만, 이는 그리 좋은 특징이 아님 (ex) "the"와 "car"의 동시 발생 횟수만 본다면, "car"는 "drive"보다 "the"의 관련성이 훨씬 더 강하다고 나올 수 있음.
-
점별 상호정보량(PMI) : 위의 문제를 해결하기 위해 사용하는 척도로, 이 값이 높을수록 관련성이 높음.
- P(x) : 단어 x가 코퍼스에 등장할 확률
- P(x, y) : 단어 x, y가 동시발생할 확률
- 단어가 단독으로 출현하는 횟수가 고려되므로 위의 문제를 해결함.
- 두 단어의 동시 발생 횟수가 0이면 음의 무한대가 된다는 단점이 존재해 실제 구현 시엔 양의 상호정보량(PPMI)를 사용함.
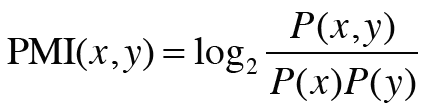
-
PPMI에도 여전히 코퍼스의 어휘 수 증가에 따라 각 단어 벡터의 차원수가 증가한다는 문제점이 존재함.
차원 감소
- 벡터의 차원을 줄이는 방법으로, 단순히 줄이기만 하는 게 아닌, 중요 정보를 유지한 채로 줄이는 것이 중요함.
- 차원 감소의 핵심은 희소벡터에서 데이터의 분포를 고려해 중요한 축을 찾아내 더 적은 차원으로 다시 표현하는 것으로, 차원 감소의 결과는 밀집 벡터로 변환됨. (변환된 벡터로 본질적인 차이를 구별할 수 있어야 함)
- 특잇값분해(SVD) : 임의의 행렬을 세 행렬의 곱으로 분해함. (차원 감소의 방법 중 하나)
- 이때, U와 V는 직교행렬, S는 대각행렬임.
- 특잇값 : 해당 축의 중요도
- 중요도가 낮은 원소(특잇값이 작은 원소)를 깎아내는 방법 = SVD에 의한 차원 감소

얼렁뚱땅 바보 학부생...