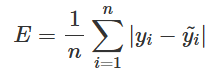
Loss Function
신경망 학습은 최적의 매개변수 값을 찾는 과정으로, 이 과정에서 손실 함수가 사용된다. 손실 함수를 사용하면, 예측값과 실제값 사이의 차이(loss)가 최소가 되는 방향으로 학습시키면서 최적의 매개변수를 찾아낼 수 있기 때문이다.
대표적인 손실 함수엔 Mean Squared Error(MSE)와 Cross Entropy Error(CEE)가 있으며, 일반적으로 MSE는 회귀 문제에, Cross Entorpy는 분류 문제에 사용되는 것으로 알려져 있다.
이렇게 대충 이해하고 넘어갈 수도 있지만, 이렇게 얕게 이해하고 넘어가는 것보다 어떤 이유에서 이런 말이 나오는지 알아보는 것도 중요하기 때문에 오늘은 왜 연속적인 분포를 갖는 데이터(ex. 회귀 문제)엔 MSE를 사용하는 것이 좋은지, 이산적인 분포를 지니는 데이터(ex. 분류 문제)엔 왜 CEE를 사용하는 것이 좋은지 그 이유에 대해 알아볼 것이다.
Mean Squared Error (MSE)
MSE는 실제값과 예측값 사이의 차이(loss)를 제곱한 값으로, 아래와 같은 식으로 정의된다.
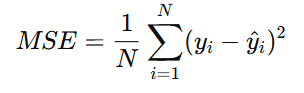
MSE는 오차 값을 제곱하므로 음수 값의 영향을 받지 않고, 큰 오차에 더 많은 패널티를 줄 수 있다. 또한, 오차값이 상대적으로 크게 반영된다는 특징이 있다.
이처럼 MSE는 예측 값과 실제 값 사이의 연속적인 수치 차이를 직접적으로 다루는 데 적합하며, 이러한 차이에 민감하다는 특성이 있어 오차가 큰 예측값을 빠르게 수정하도록 유도할 수 있다는 장점이 있다. 손실 함수를 사용하는 목적은 예측값과 실제값 차이(loss)가 최소가 되는 값을 찾는 것이 목표인데, 이를 통해 가중치를 업데이트하면 보다 더 빠르게 목표에 도달할 수 있다.
따라서, MSE는 회귀와 같이 연속적인 숫자 값을 예측하는 문제(ex. 집값/기온/매출 예측)에 적합하다.
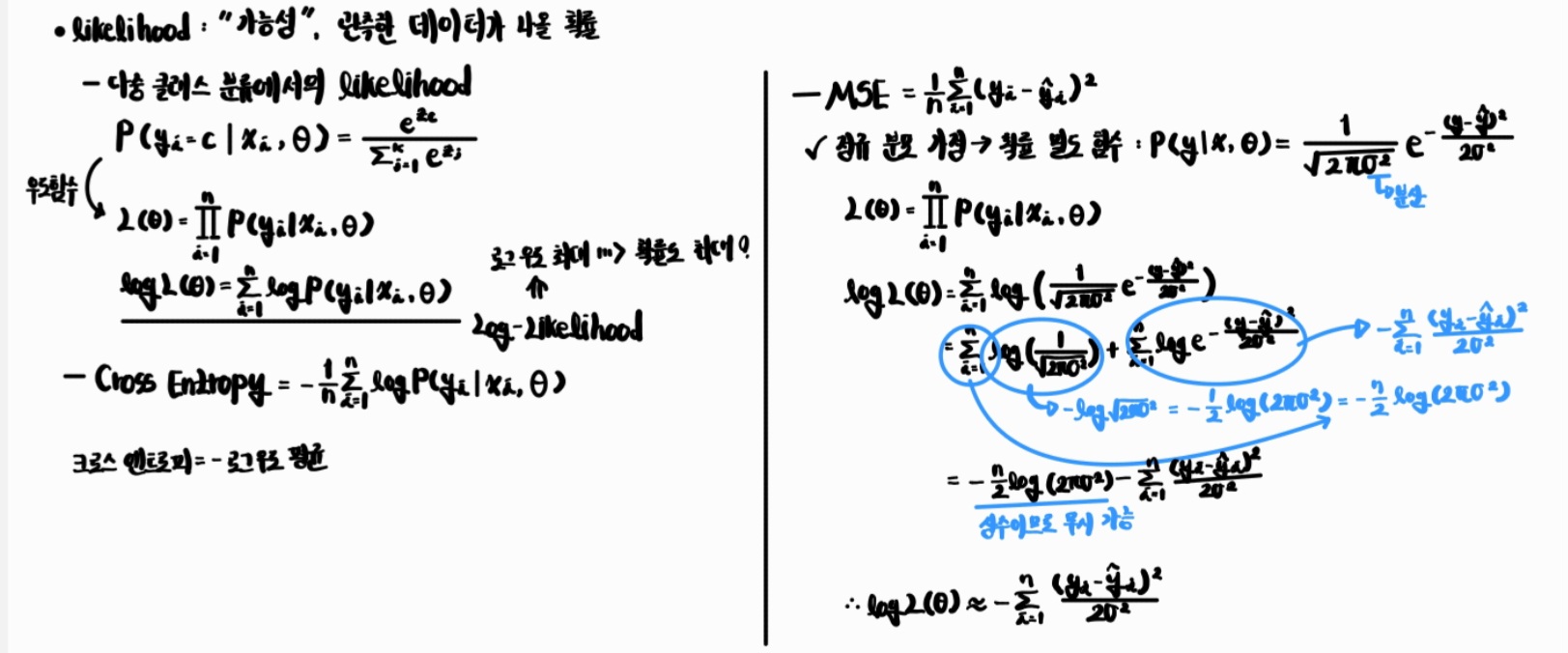
통계적인 관점에선 다음과 같다. 아래의 사진은 회귀에서의 로그 우도를 설명한다. 이때, likelihood는 가능성을 의미하며, Log-likelihood는 likelihood에 로그 함수를 활용해 수의 계산을 편리하게 해준다. 이러한 Log-likelihood의 최댓값은 실제로 일어날 확률을 가장 크게 만들어 주는 예측을 의미한다. 회귀에서 로그 우드 최대화 = MSE 최소화이므로 MSE를 최소화하는 것이 회귀에서 확률을 가장 크게 만들어주는 예측이라고 할 수 있다.

Cross Entropy Error (CEE)
CEE는 아래와 같은 식으로 정의되며, 예측값과 실제값 사이의 확률 분포 차이를 계산한다.
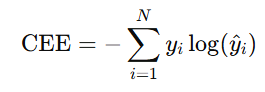
이때, 는 주로 one-hot 벡터이기 때문에 실제 정답에 해당하는 인 경우에만 loss에 영향을 주고, 다른 클래스는 loss에 영향을 주지 않는다.
또한, 정답인 확률이 높을수록 작은 loss 값을 지니기 때문에 예측값이 실제 정답과 얼마나 가까운지를 확률적으로 측정하기 좋고, 이를 통해 실제 정답의 확률을 높이고, 나머지 클래스의 확률을 낮추는 방향으로 가중치 업데이트를 진행하기도 좋다. 그래서 여러 클래스 중 어떤 클래스의 확률이 가장 높은지를 결정하는 분류 문제에 CEE를 사용하는 것이 적합하다.
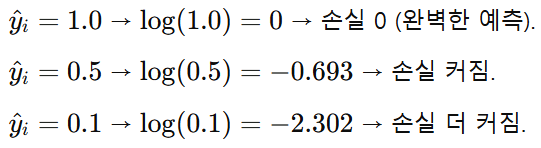
통계적인 관점에선 다음과 같다. 분류에서 로그 우드 최대화 = CEE 최소화이므로 CEE를 최소화하는 것이 분류에서 확률을 가장 크게 만들어주는 예측이라고 할 수 있다.

정리해 보면, MSE는 실제값과 예측값 사이의 오차를 잘 반영하기 때문에 연속적인 값을 잘 다루는 회귀 문제에, CEE는 실제값(주로 one-hot 인코딩)과 예측값(softmax 혹은 sigmoid를 통해 나온 예측값) 사이의 확률 분포를 계산하기 때문에 분류 문제에 주로 사용된다.
** Regression vs Classification
- MSE = “정규분포 가정” 아래 로그우도를 최대화하는 손실
- CEE = “베르누이/이항(또는 다항) 분포 가정” 아래 로그우도를 최대화하는 손실