[논문 리뷰] UniVAD: A Training-free Unified Model for Few-shot Visual Anomaly Detection (CVPR 2025)
논문리뷰
https://arxiv.org/pdf/2412.03342
1. Introduction
- Visual Anomaly Detection (VAD)은 이미지 내에서 정상적인 패턴에서 벗어나는 비정상적인 샘플을 식별하는 중요한 컴퓨터 비전 기술임. 이는 industrial, logical, medical 분야를 포함한 다양한 도메인에서 활용됨
- 기존 VAD 방법론들은 특정 도메인에 특화되어있어 다른 도메인으로의 일반화가 어려움. 대부분의 접근 방식은 one-for-one 방식으로, 각 객체 카테고리별로 별도의 모델 학습을 요구하며, 이는 많은 정상 샘플을 필요로 하고 일반화 및 통합 평가를 어렵게 함
- 이러한 한계를 해결하기 위해 저자들은 UniVAD (UniAD랑은 다름)를 제안하여 industrial, logical, medical 등 다양한 도메인의 이상을 탐지할 수 있는 training-free(학습이 필요 없는) 통합 모델을 제안함
- UniVAD는 테스트 시 몇 개의 정상 샘플만을 reference로 사용하여 이전에 본 적 없는 객체에서도 이상을 탐지할 수 있으며, 특정 도메인에 대한 사전 학습이 필요 없음
2. Related Work
2.1. Visual Anomaly Detection
Traditional visual anomaly detection
데이터 분포와 이상 유형의 상당한 차이 때문에 industrial, logical, medical 분야와 같은 특정 도메인에 특화되어 개발됨
- Industrial: 주로 결함을 식별하며, 최근 방법들은 patch feature matching (e.g., reconstruction-based, CLIP 등과 같은 사전 학습된 모델 활용)에 중점을 둠
- Logical: 이미지의 구성 요소(색상, 양 등)가 논리적 제약 조건을 만족하는지 평가하며, 더 높은 수준의 의미론적 이해가 필요함. 종종 component들을 분할하여 개별 특징을 평가함
- Medical: 의료 영상에서 병리학적 영역을 찾아내며, reconstruction-based, self-supervised 방법 등을 포함하지만, 신체 부위 및 질병마다의 가변성 때문에 일반화가 어려움
Limitations
- 최근 UniAD와 같은 통합에 대한 연구가 이루어졌지만, 여전히 industrial application에 최적화되어 다른 도메인에서는 성능이 저하되고 모델 훈련에 많은 양의 정상 데이터가 필요함
2.2 Component Segmentation
Logical anomaly detection에서는 이미지의 sub-parts를 추출하고 각 부분에서 이상을 평가하기 위해 component segmentation에 자주 의존함.
Limitations
- ComAD: 클러스터링을 사용하여 segment하지만, few-shot 시나리오에는 적용이 어려움
- CSAD, SAM-LAD: SAM과 같은 비전 foundation model을 활용하지만, segmentation granularity를 제어하기 어려움
- Coarse granularity: 이미지 전체를 하나의 영역으로 간주하거나, 몇 개의 큰 단위로만 나누는 경우
- Fine granularity: 하나의 의미 있는 객체를 너무 많은 조각들로 분할하는 경우
- PSAD: 제한된 수의 annotation이 있는 샘플을 사용하므로 학습 비용과 수동 레이블링이 필요함
3. Method
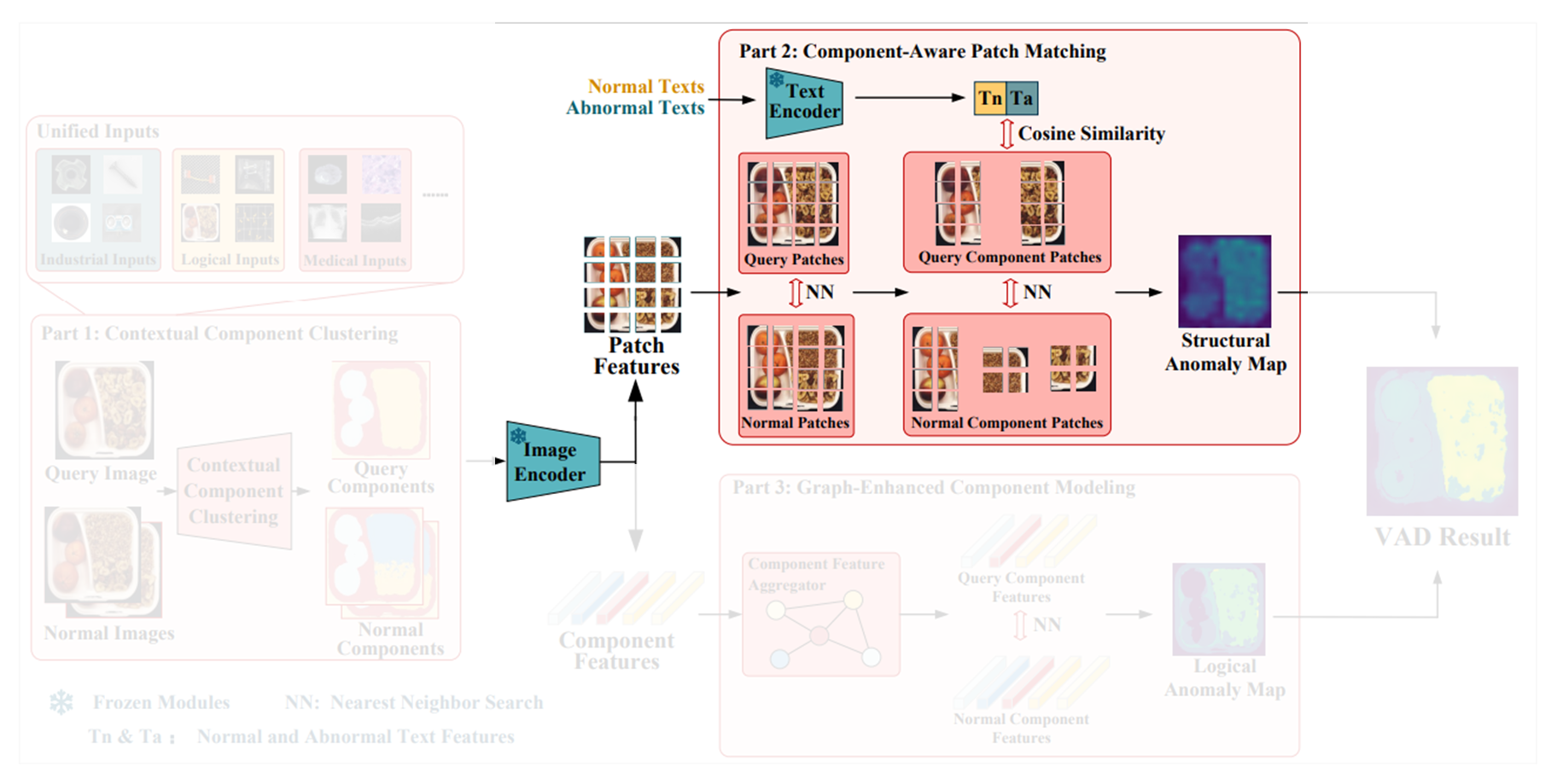
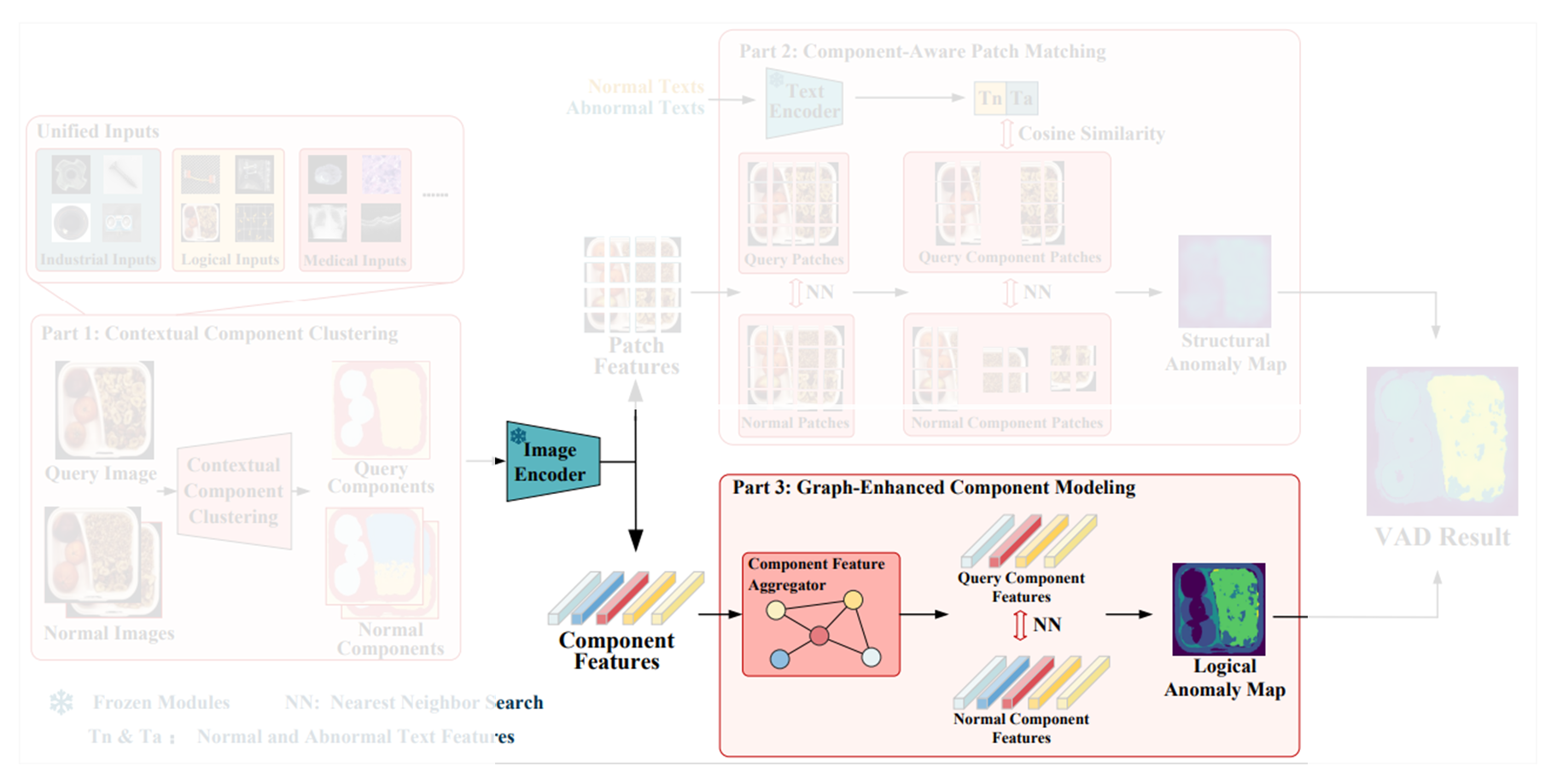
3.1. Overall Architecture
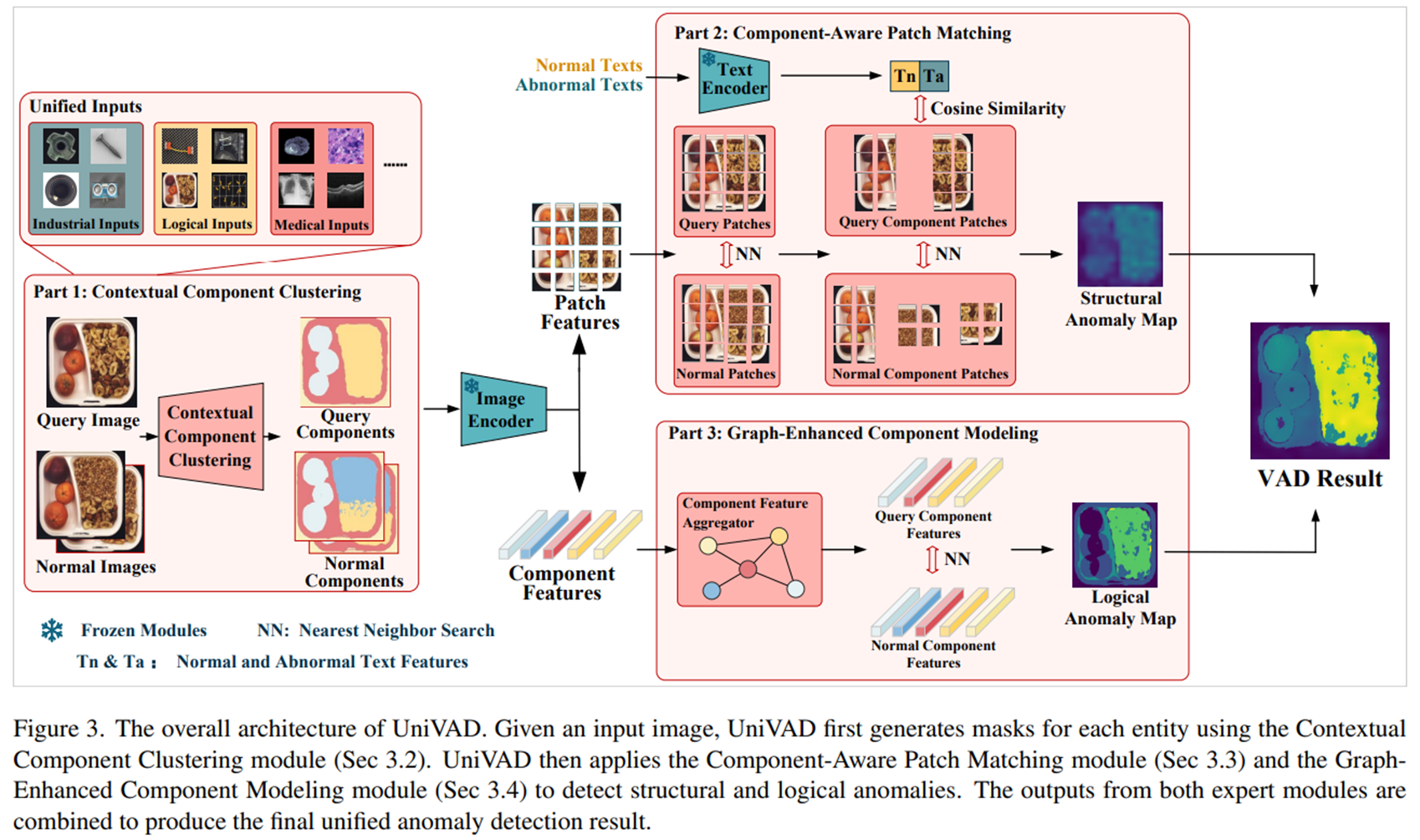
전체 아키텍처의 흐름은 아래와 같다.
- 쿼리 이미지(즉, 테스트 이미지) 와 개의 reference 정상 이미지들 이 주어지면 contextual component clustering module ( 모듈이라고 함) 을 거쳐서 각 component에 일치하는 mask를 얻음
- 이후 query 이미지와 normal 이미지들을 모두 사전 학습된 image encoder를 거쳐서 각각의 feature map들 와 를 얻음
- Component mask에 따라 group average pooling을 적용하여 query, normal 이미지에 대한 component-level features인 와 를 얻음(는 쿼리 이미지의 component 수, 는 정상 이미지의 component 수)
- 와 는 interpolation을 거쳐서 patch-level features 와 가 됨
- 정상과 이상에 대한 텍스트 설명들을 text encoder를 거쳐서 각각 와 얻고, 위에서 얻은 patch-level features인 와 와 함께 component-aware patch matching module에 입력되어 structural anomaly map을 얻음
- 와 는 graph-enhanced component modeling module 을 지나서 logical anomaly map을 얻음
- 5,6에서 얻은 structural anomaly map과 logical anomaly map을 결합하여 최종 anomaly detection result를 얻음
위 과정만으로도 대략적인 워크플로우는 알 수 있지만, 아래에서 각 모듈을 더 자세히 알아보자.
3.2. Contextual Component Clustering ()
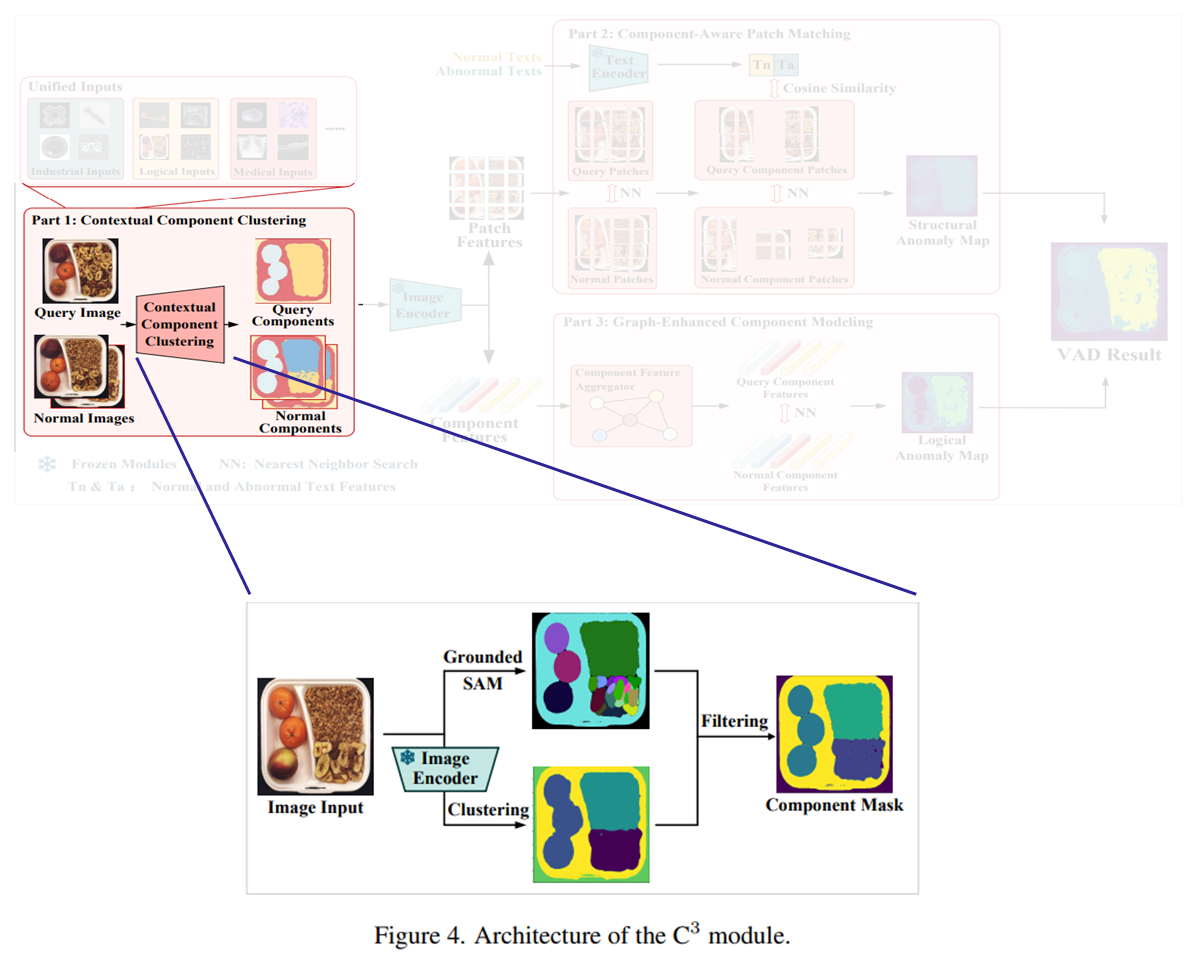
제한된 양의 정상 샘플만으로도 정확한 component segmentation을 수행하기 위해 제안되는 모듈이다. 동작 순서는 아래와 같다.
-
입력 이미지(쿼리, 정상 이미지 모두)가 들어오면, Recognize Anything Model 을 통해 이미지 내의 객체를 식별하고 content tags를 생성한다.
-
Grounded SAM을 통해 모든 식별된 객체에 대한 마스크를 생성한다. (GroundingDINO로 텍스트+이미지 → bounding box 생성, 그 이후 SAM으로 bounding box + 이미지 → segmentation mask 생성)
-
Segmentation granularity를 피하고 쿼리와 정상 이미지에 대해 일관된 component 마스크를 얻기 위해 다음과 같은 조정 과정을 거친다.
초기에 Grounded SAM으로 개의 component masks 을 얻었다고 하면:
-
만약 (식별된 객체가 하나라면)이고, 이상의 지역이 포함된다면 어떤 객체에 대한 클래스가 아니라, texture에 대한 클래스에 속하는 것이라고 보고, 전체 이미지를 하나의 component로 잡는다.
-
만약 이면서 보다 작은 지역이 포함된다면 해당 이미지가 하나의 객체를 포함한다고 가정하고, SAM이 생성한 마스크 그 자체를 최종 마스크 으로 사용한다.
-
만약 (식별된 객체가 많음)이면 위 fig 4처럼 clustering 결과를 통해 조정 과정을 거친다:
- 먼저 image encoder로 정상 이미지의 feature map 을 추출하고, K-means clustering을 통해 개의 그룹을 얻는다.
- 쿼리와 정상 이미지 feature map의 각 feature에 대해서 각 cluster의 centroid와 유사도를 통해 개의 cluster mask인 를 얻는다.
- 개의 마스크 중에서 네 꼭지점의 픽셀 레이블이 모두 1인 마스크를 background 마스크로 간주하고, 해당 마스크는 제거한다.
- 이렇게 배경 마스크가 제거된 개의 마스크를 resize하여 기존 크기의 를 얻는다.
- 의 각 마스크 에 대해 내 마스크들과 Intersection over Union (IOU)를 계산해서 가장 높은 IoU를 갖는 마스크 와 일대일 매칭이 된다.
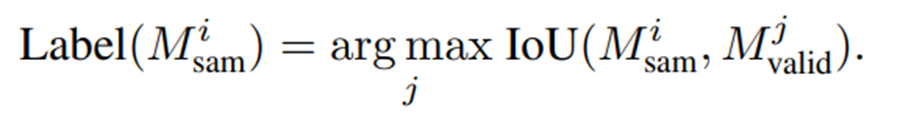
- 마지막으로, 원래 마스크 를 레이블 가 할당된 모든 마스크의 합집합으로 대체하여 최종 마스크 집합 를 생성
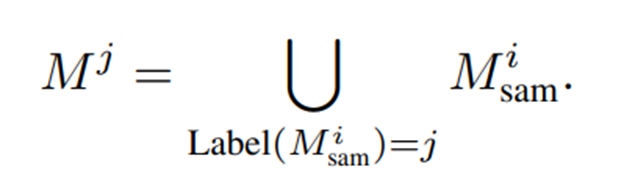
-
이러한 과정을 통해 granularity control된 정확한 component segmentation mask를 얻게 되고, 이후 component-aware patch-matching module과 graph-enhanced component modeling module을 통해 structural anomaly와 logical anomaly를 탐지하게 된다.
3.3. Component-Aware Patch Matching (CAPM)
Patch feature matching에 사용되는 모듈로, component constraints와 image-text feature 유사도 비교를 통해 성능 향상에 기여한다.
우선 일반적인 patch feature matching 방식으로 patch-matching anomaly score를 구한다.
- ImageNet으로 학습된 pretrained image encoder로 쿼리 이미지와 정상 이미지에 대한 feature map 와 를 추출해서, 둘 모두 interpolation을 적용해서 patch features인 와 를 얻는다. (, 는 이미지의 input size였던 와 동일할 것으로 추정)
- 쿼리 이미지로 얻은 모든 들에 대해 정상 이미지에서 얻은 의 모든 패치들과 코사인 유사도를 계산해서 각각 가장 작은 코사인 거리를 갖는 정상 패치와의 코사인 거리값으로 patch-matching anomaly score를 계산하게 된다.
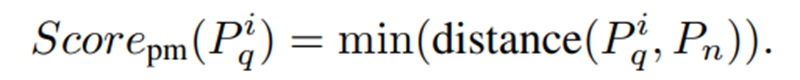
하지만 위 방식은 이미지의 배경 영역에서 비정상 패턴과 유사한 패치를 이상으로 오인하여 false positive를 발생시킬 수도 있고, 이미지 내 다양한 component를 서로 구분하지 못하여 유사한 색상이나 질감을 가지는 관련 없는 영역의 패치들을 잘못 짝지어 missed detection이 발생할 수 있다.
따라서 모듈에서 얻은 component mask를 활용해서 같은 component에 속하는 패치 내에서 feature matching이 일어날 수 있도록 하여 component-aware anomaly score를 계산한다. 자세히 알아보자.
- Normal patch features인 을 얻은 후, 개의 component masks를 활용해서 개의 patch subsets를 만드는데, 패치들은 자신이 속하는 마스크에 할당된다.
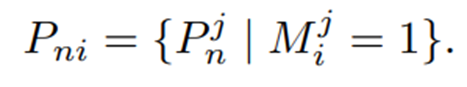
- 그리고 쿼리 patch features인 에 대해서도 똑같은 과정을 거쳐서 를 얻고, 같은 에 속하는 정상/쿼리 feature들 간의 유사도 비교를 수행하도록 한다.
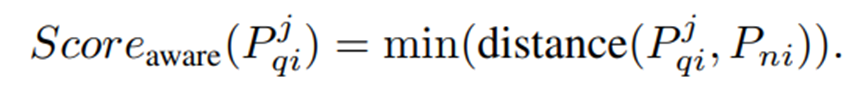
추가로, 각 패치에 대해 이미지-텍스트 feature-matching도 추가로 수행하는데, 이는 사전 학습된 text encoder로부터 정상/이상 text feature인 과 를 구하고, 쿼리 이미지의 각 feature와 코사인 유사도를 구하고 소프트맥스를 통해 image-text anomaly score를 구한다.
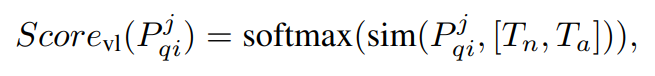
마지막으로, 앞서 구한 세 가지 anomaly score를 가중합하여 최종 structural anomaly를 계산한다.
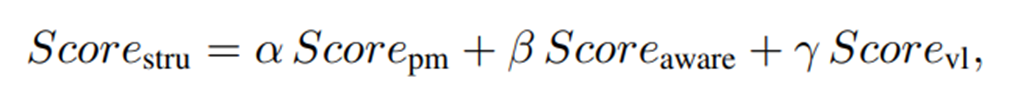
는 하이퍼파라미터로, 실험에서는 모두 1/3로 통일하였다고 한다.
3.4. Graph-Enhanced Component Modeling
앞서 설명한 CAPM 모듈은 low-level semantics 차원에서 structural anomaly를 탐지하기 위해 설계된 모듈이고, 이는 보통 이상 부위가 정상 이미지에서는 나타나지 않는다는 점을 활용하였다면, high-level semantic logical anomaly의 경우에는 이상 content가 정상 이미지에서도 나타날 수 있지만, 잘못된 방식으로 결합된 경우(e.g., 도시락의 두 과일 개수 비율이 반전됨)를 다루기 때문에, 단일 patch feature를 비교하는 방식으로는 해결이 어렵다.
따라서 본 논문에서는 Graph-Enhanced Component Modeling (GECM) module을 디자인하여 각 component의 전체적인 특성에 집중하여 components의 addition, omission, 또는 misplacement를 탐지하고자 한다.
동작 순서는 아래와 같다.
-
모듈에서 component masks를 얻은 후, 마찬가지로 사전 학습된 image encoder를 통해 와 을 얻고, group average pooling을 적용하여 쿼리와 정상 이미지의 각 component에 대한 deep features를 포착하도록 와 를 얻는다.
-
이후, Component Feature Aggreagator (CFA) module을 통해 각 component의 특징을 추가로 모델링한다.
- 해당 모듈에서는 먼저 각 component feature를 그래프의 노드로 모델링하고, 두 component 특징 간의 코사인 유사도를 두 노드를 연결하는 edge의 가중치로 모델링하여 그래프의 모든 노드에 대한 인접 행렬을 계산한다.
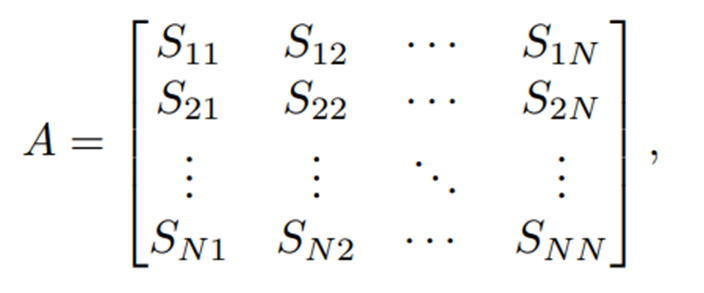
- 여기서 은 components의 수이고, 는 와 노드 간 정규화된 유사도를 의미한다. 수식으로는 아래와 같이 표현된다.
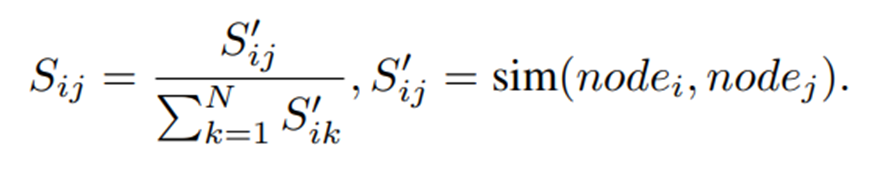
-
다음으로, 이 인접행렬 에서 graph attention operation을 통해 노드 정보를 집계하여 각 component에서 어떤 feature embeddings가 그 component의 전반적인 특성을 대표하는지를 알아내는데, 이들은 각각 와 로 표현된다. (는 graph attention)
-
내의 embedding들인 (는 노드, 즉 하나의 component를 의미함)를 의 벡터들과 유사도를 구하여 해당 component에 대한 deep anomaly score를 다음과 같이 계산한다.
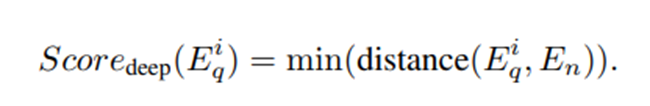
- 이번엔 logical anomaly를 탐지하는 데 중요한 요소인 각 component의 area, color, position같은 geometric features인 와 를 얻고, 이를 활용하여 다음과 같이 geometric anomaly score를 계산한다.
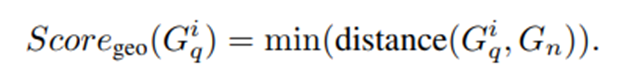
- 이후 두가지 score를 결합하여 logical anomaly score를 얻는다.
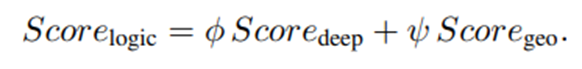
앞 섹션에서 구한 structural anomaly score 과 방금 구한 logical anomaly score 을 다음과 같이 결합하여 최종 anomaly score map을 얻게 된다.
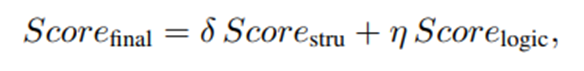
(는 모두 하이퍼파라미터로, 논문에서는 0.5로 설정했다고 언급함)
4. Experiments
4.1. Experimental Setups
Datasets
총 9개의 industrial, logical, medical anomaly detection domain의 데이터 셋으로 검증을 수행하였음
Competing Methods and Baselines
Few-normal-shot 세팅에서는 target dataset에서 학습 없이 test time에 소수의 정상 샘플만 reference로 제공되며, industrial 비교 모델로는 PatchCore, WinCLIP, AnomalyGPT, UniAD를, logical 비교 모델로는 ComAD, medical 비교 모델로는 MedCLIP을 선택하였다.
Few-abnormal-shot 세팅에서는 medical anomaly detection에서 흔히 사용되는 설정으로, target dataset에서 적은 수의 정상/비정상 샘플로 학습 후 테스트를 수행한다. DRA, BGAD, MVFA를 비교 모델로 선정하였다.
Evaluation Protocols
기존의 이상 탐지 방법론에 맞춰, image-level, pixel-level 모두 Area Under the Receive Operating Characteristic Curve (AUC)를 평가 지표로 사용하였다.
Implementation Details
Few-normal-shot 세팅에서 UniVAD에 추가적인 학습은 수행되지 않으며, 모든 이미지의 해상도는 448 x 448로 resize하였다. vision encoder로는 CLIP-L/14@336px와 DINOv2-G/14를 사용하였다.
Image-level의 anomaly score는 pixel-level anomaly score 결과에서 사후적으로 도출되는데, medical 도메인 중 HIS만 평균값을 사용하였고, 나머지 데이터셋에서는 최대값을 사용하였다.
4.2. Main Results
Few-normal-shot setting
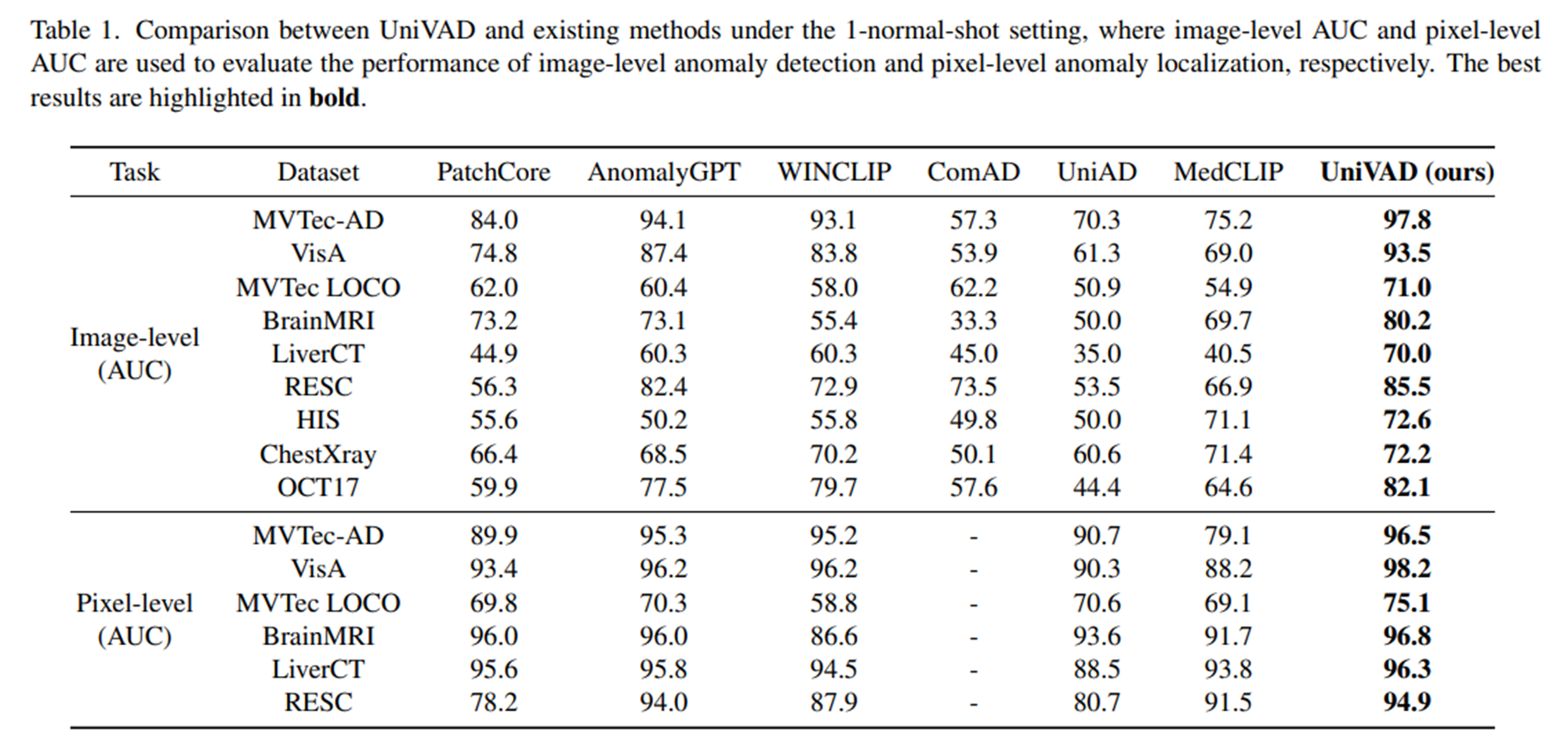
- UniVAD는 image-level auc 및 pixel-level auc 모두에서 기존의 도메인 별 방법들을 뛰어넘는 성능을 보였음
- 특히, image-level auc는 평균 6.2%, pixel-level auc는 평균 1.7%의 성능 향상이 이루어졌음
- 이러한 결과는 UniVAD의 강력한 transferability와 다양한 도메인에 걸쳐 이상을 효과적으로 감지할 수 있는 능력을 입증함
Few-abnormal-shot setting
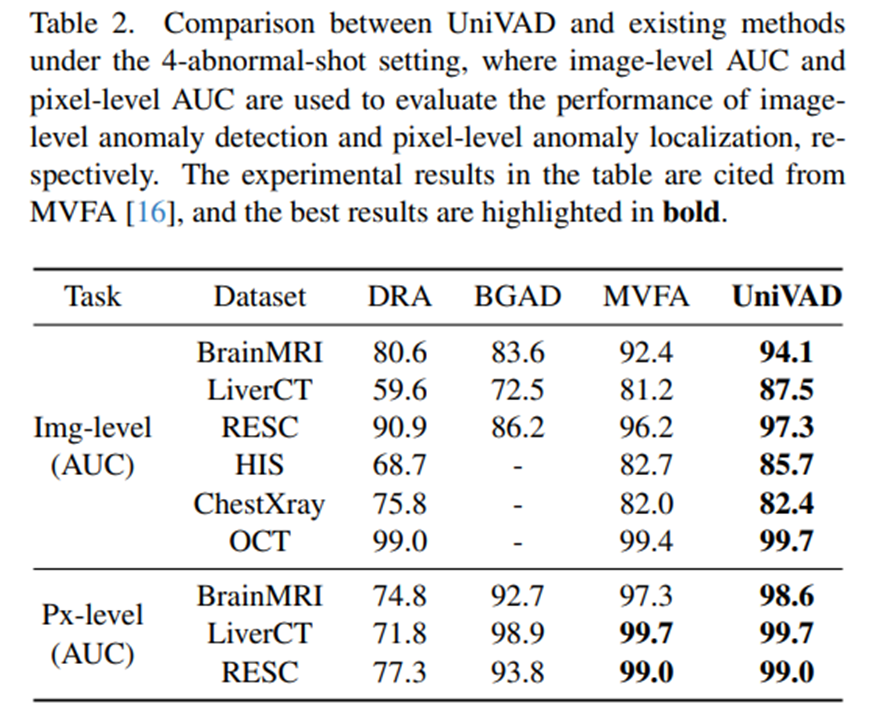
- 4-abnormal-shot 설정에서도 UniVAD는 기존 접근 방식보다 뛰어난 성능을 보여주었음
- 이는 UniVAD가 강력한 일반화 능력과 함께 도메인별 작업에 대한 뛰어난 정확도를 모두 갖추고 있음을 보여줌
4.3. Ablation Study
Contextual Component Clustering
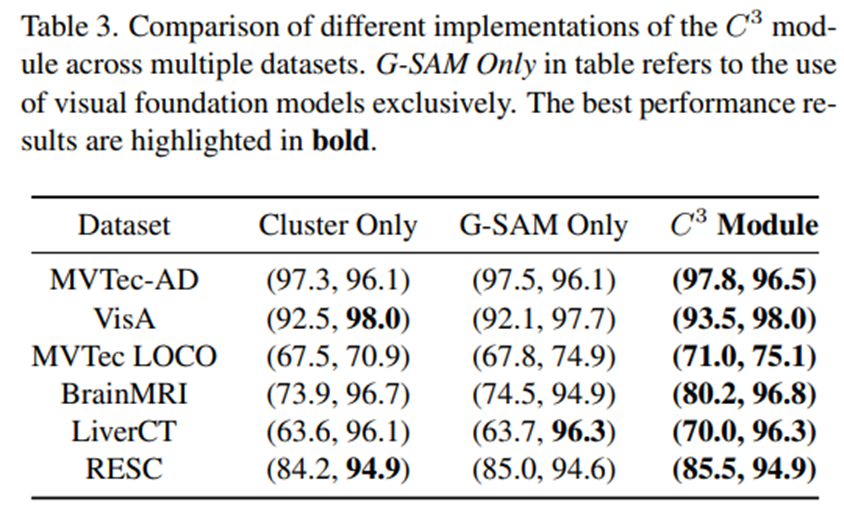
- 모듈에서 cluster만 사용하거나 Grounded SAM만 사용하면 성능이 감소하는 것을 확인할 수 있음
- Pixel-level에서는 MVTec-LOCO 데이터셋에서 Grounded SAM을 쓰고 안 쓰고의 차이가 가장 dramatic하게 차이나는데, MVTec-LOCO같이 logical anomaly를 탐지하는 데 있어서 이미지 내 개별 구성 요소를 정확하게 분리하는 것이 중요할 것으로 보임(논문 앞에서도 언급하긴 함)
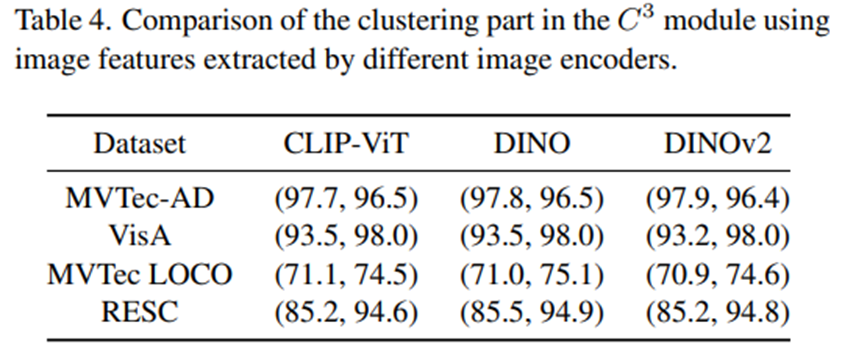
- image encoder를 바꿔가며 실험한 결과, 큰 성능 차이는 없는 것으로 보임.
- 한 가지 궁금한 건, 본 ablation에서는 아마 clustering에 사용되는 image encoder의 효과를 보여주기 위한 실험 같긴 한데, image encoder는 component-aware patch matching 파트에도 text embedding과 비교를 하기 위해 patch features를 추출하는 과정에서도 쓰인다. 이 부분에는 text embedding과 유사도를 비교하는 과정이 들어가기 때문에, CLIP encoder를 쓰는 경우 성능 향상이 당연히 이루어져야 하지 않나 싶은데, 왜 성능 차이가 없는지 의문이 든다.
DINO가 개쩌는건가?모듈에 대한 ablation이기 때문에, CAPM에 사용되는 vision encoder는 CLIP으로 고정시키고, Clustering에 사용되는 vision encoder만 갈아가며 실험한게 맞는것같기도..
Component-Aware Patch Matching
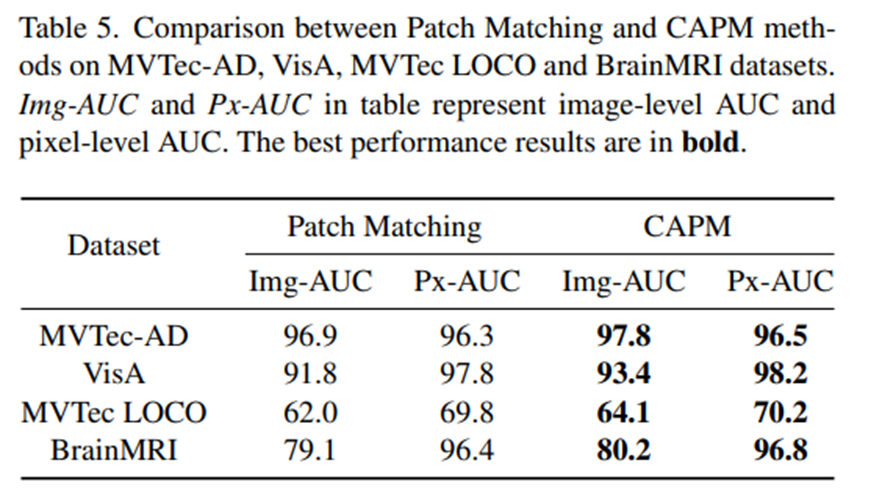
- 기존의 단순 patch matching과 CAPM의 성능 비교를 위한 실험으로, CAPM 방식으로 같은 component에 속하는 패치끼리만 유사도를 비교하도록 하는 방식이 성능 향상을 이끌고 있다.
Graph-Enhanced Component Modeling
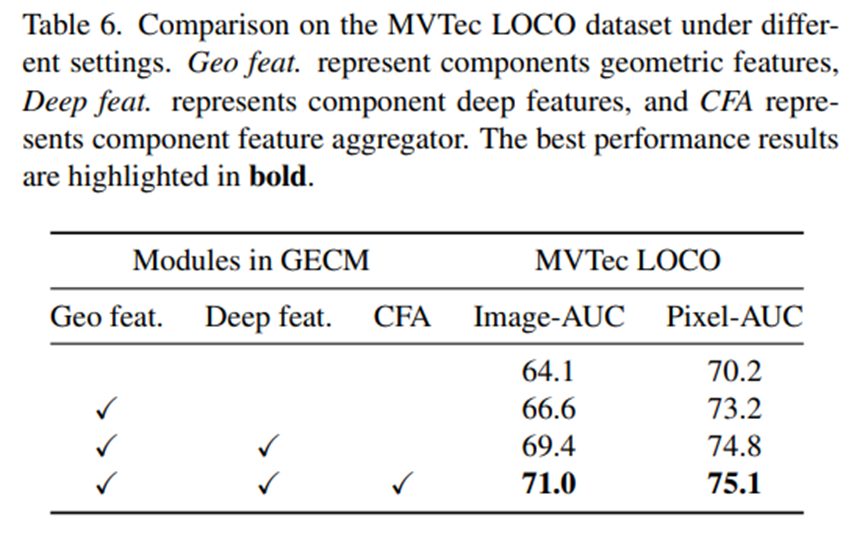
- Logical anomaly score를 계산하는 데 있어서, geometrical features, deep features, CFA는 모두 성능 향상에 기여하였다.
4.4. Visualization Results
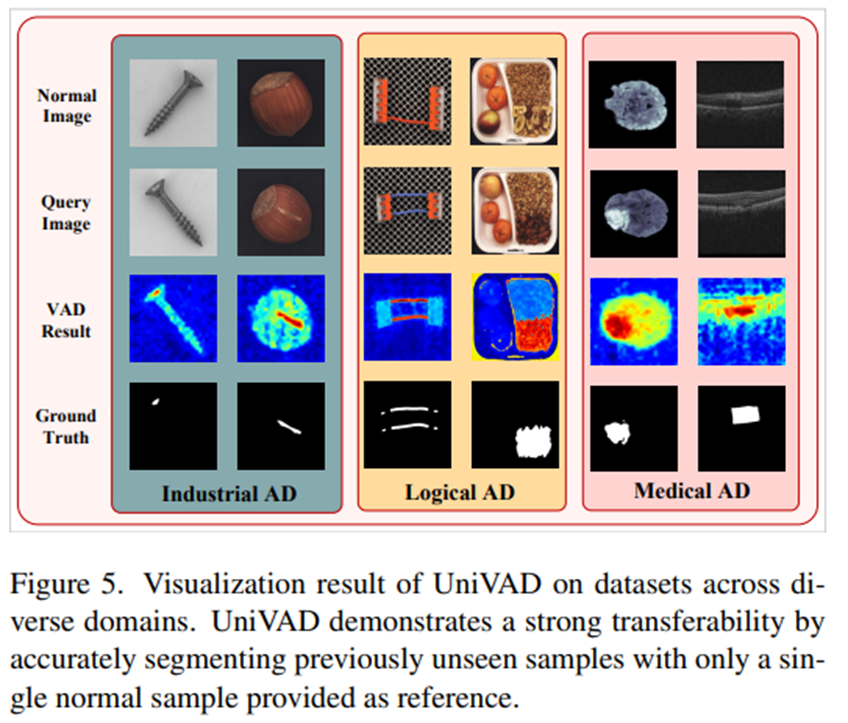
- Industrial, logical, medical 도메인에서 모두 한 번도 보지 못한 샘플들에 대해 이상 부위를 잘 잡고 있는 것을 확인할 수 있다.
Review
올해 ICLR에서 발표된 IIPAD(https://velog.io/@barley_15/논문-리뷰-One-for-all-Few-shot-Anomaly-Detection-Via-Instance-Induced-Prompt-Learning-ICLR-2025) 논문을 리뷰하면서 “이제 unified anomaly detection 방법론은 few-shot 세팅도 가능하게 연구 되겠구나~” 했는데 UniVAD는 training-free하게 모든 도메인(산업, 메디컬, 심지어 logical까지)에서 이상탐지를 수행하는 걸 보고, 같은 시기 논문인데 두 편 모두 one-for-all 패러다임에서 참 많은 변화를 주는구나 싶었다.
불과 작년 재작년까지만 해도 unified model이라면 MVTec-AD의 모든 클래스들을 통합 학습 및 평가하고, VisA의 모든 클래스들을 통합 학습 및 평가해서 실험 결과를 보여주는 논문들이 나왔는데, UniVAD는 애초에 추가 학습 없이 소수 정상 이미지만 주어지면 모든 도메인에서 테스트만 딸깍 해서 결과를 내는게, 이게 진정한 통합 모델이지 싶었다.
