1. Introduction
- 산업 결함 탐지 및 의료 영상 분야에서 cold-start 문제는 새로운 객체 범주에 대한 지도 학습을 위한 충분한 양의 레이블이 달린 데이터가 부족한 것이 특징인 주요 과제임
- Zero-shot anomaly detection (ZSAD)는 보조 데이터에 대해 학습 후 새로운 객체의 이상을 탐지하는 효과적인 솔루션이나, 다양한 제품에 걸쳐 배경 특징, 이상 유형 및 시각적 외형에 상당한 변화가 있어 강력한 일반화를 달성하기엔 어려움이 있으나, 최근엔 CLIP과 ALIGN같은 vision-language model (VLM)을 활용하여 해결하고자 함
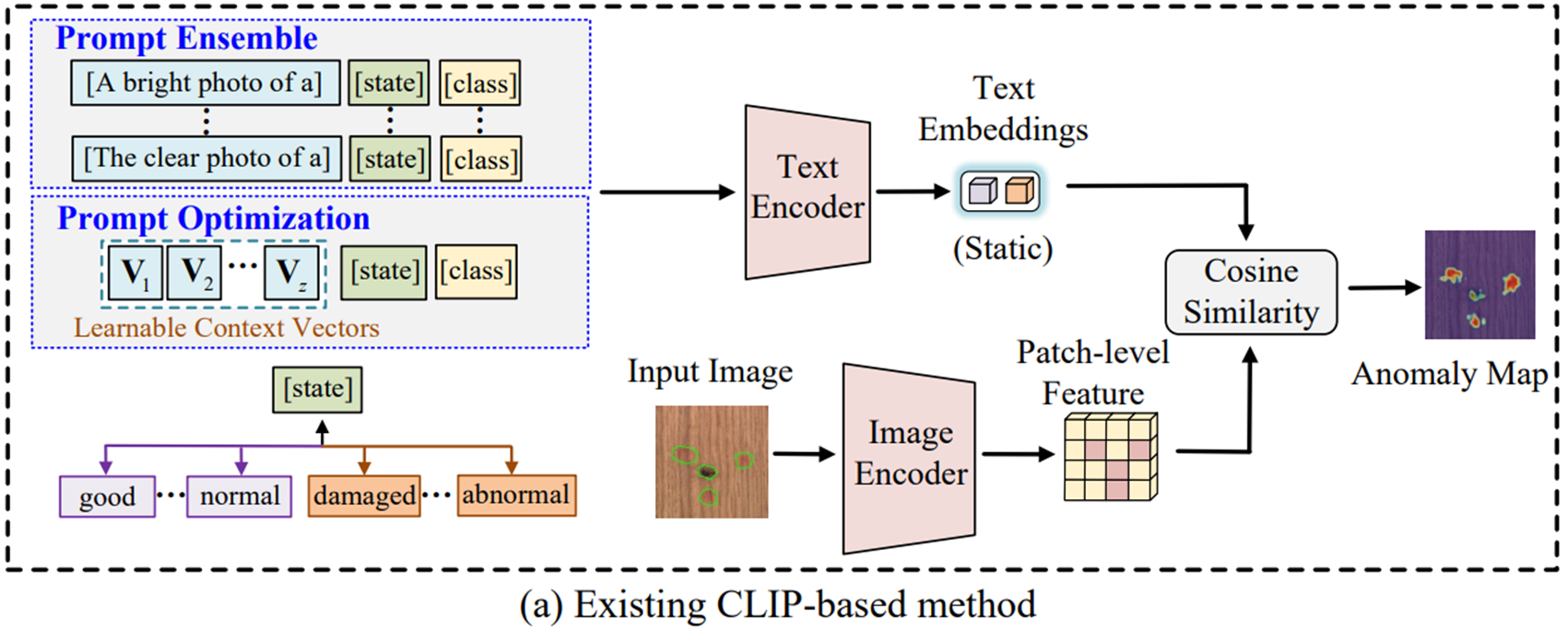
- WinCLIP, APRIL-GAN, CLIP-AD에서 사용한 프롬프트 앙상블 기반 방법은 수작업으로 제작한 프롬프트에 의존하며, AnomalyCLIP과 AdaCLIP의 프롬프트 최적화 기반 방법은 설계가 지나치게 단순하여 복잡한 context 의미를 포착하기 어려우며, 학습 가능한 프롬프트 공간이 적절하게 제약되지 않는다면 unseen 데이터에 대한 일반화 성능을 높이기 어려움
- 본 연구에서는 image-specific, image-agnostic 분포를 학습하고 텍스트 프롬프트 공간을 정규화하여 모델의 일반화 성능을 향상시키고, 학습된 분포에서 샘플링하여 프롬프트 공간을 효과적으로 커버하는 Bayesian Prompt Flow Learning (Bayes-PFL)을 제안
2. Related Works
Zero-shot Anomaly Detection
- WinCLIP은 ZSAD의 초기 연구로 multi-scale에서 텍스트를 sub image와 정렬하여 얻은 분류 결과를 집계하는 window-based 방식을 제안
- APRIL-GAN, CLIP-AD는 learnable adapter layer글 사용하여 세분화된 패치 특징을 공동 임베딩 공간에 mapping
- SAA/SAA+와 ClipSAM은 SAM과 GroundingDINO같은 여러 foundation model을 활용하였음
- AnomalyCLIP, Filo는 learnable vector를 input text 또는 CLIP의 텍스트 인코더의 중간 layer에 삽입
- AdaCLIP과 VCP-CLIP은 textual, visual hybrid 프롬프트를 추가로 활용하여 이상 탐지 성능을 향상시켰음
Prompt Design
- WinCLIP과 APRIL-GAN의 compositional prompt ensemble은 여러 state words와 textual templates를 조합하여 다양한 텍스트 프롬프트를 생성하였음. 이 때 대략 35개의 templates와 5개의 state words를 조합하여 35 5 개의 텍스트 프롬프트를 사용한 후, 이를 평균하여 사용
- AnomalyCLIP의 prompt optimization 방법은 텍스트 프롬프트의 context words를 learnable vector로 대체하거나, 텍스트 인코더 내 직접적으로 삽입함. 하지만 이도 결국 하나의 형태를 갖는 프롬프트 디자인됨
3. Method
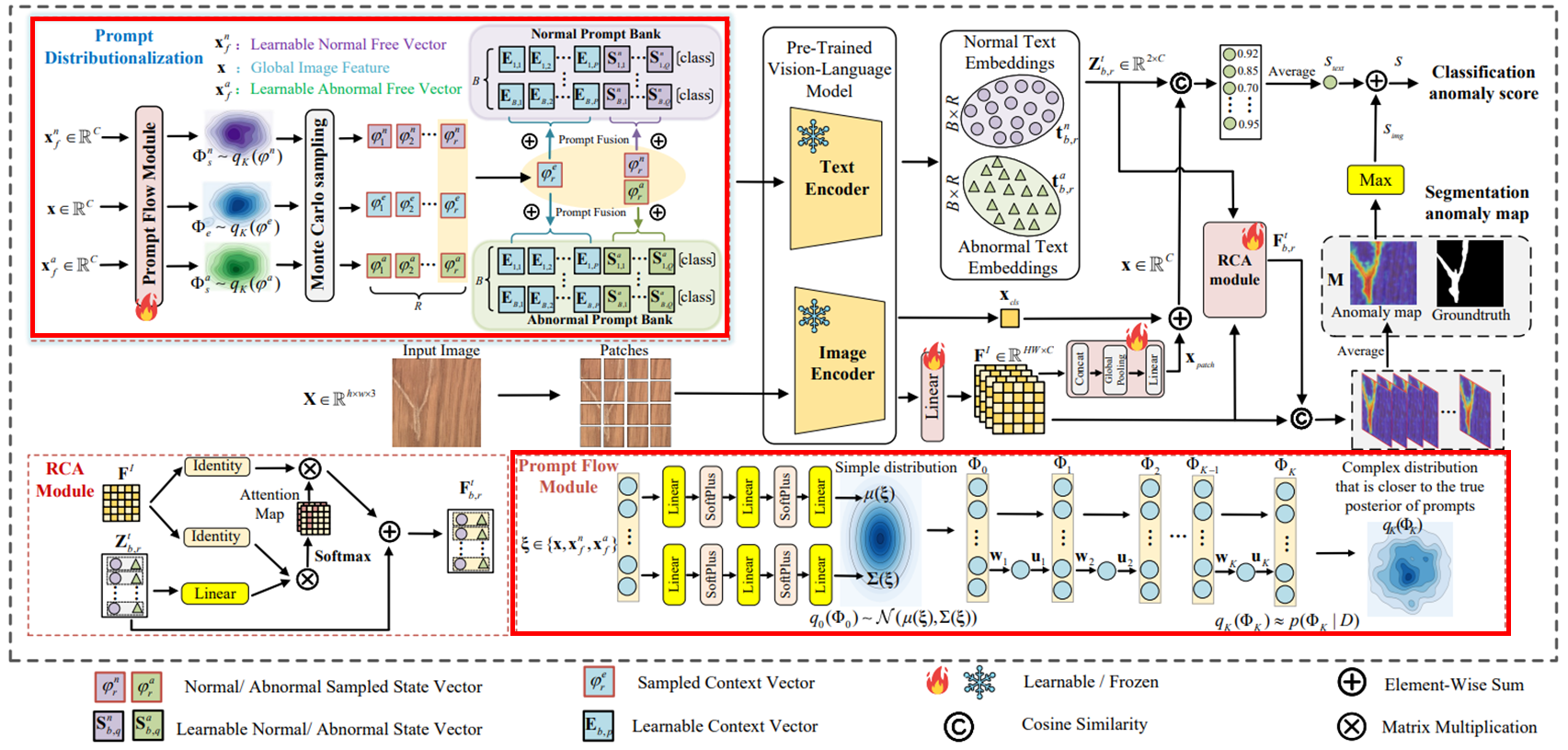
3.1. Overview
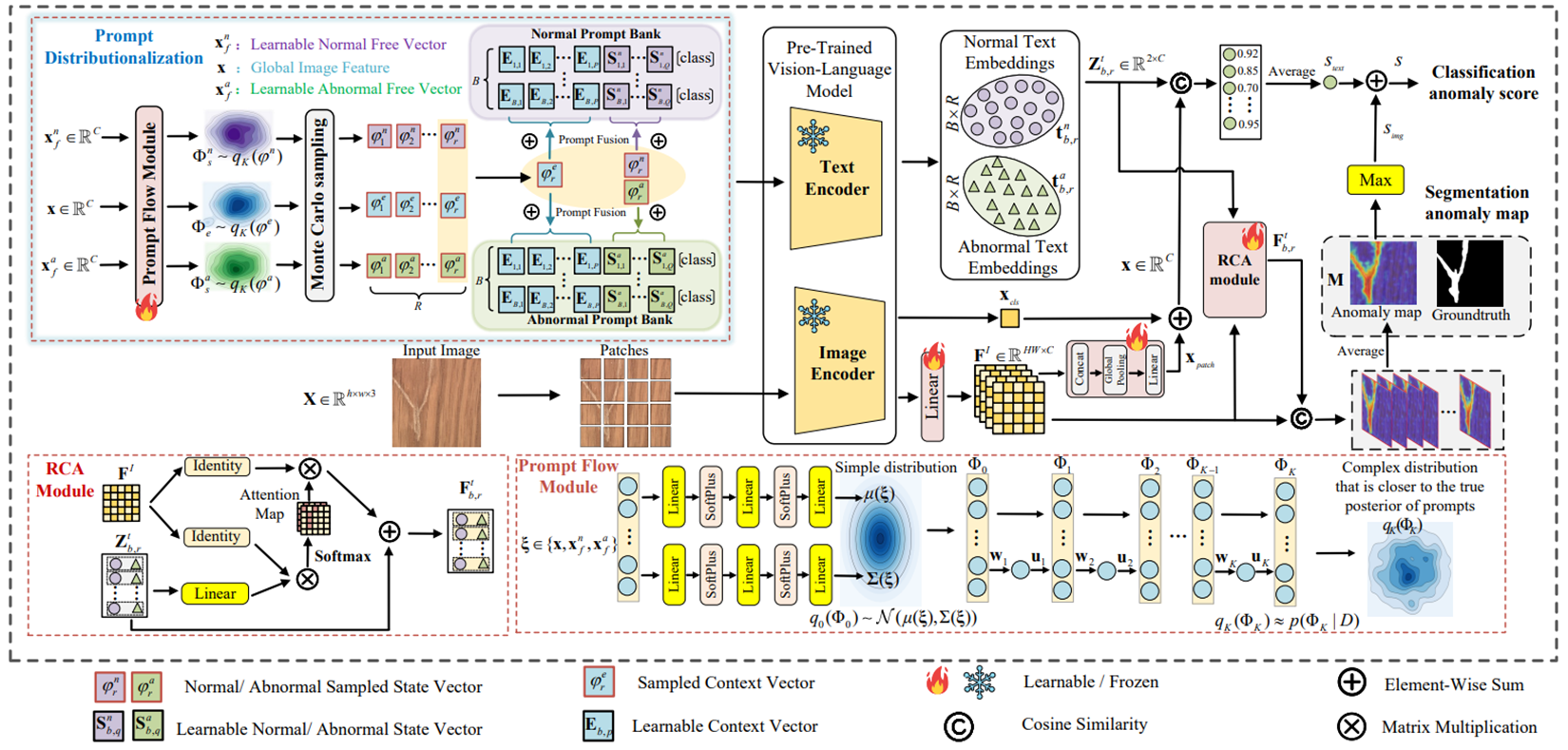
세 가지 주요 요소
Two-class prompt banks : 정상 및 이상 텍스트 설명을 위한 프롬프트 뱅크 구축
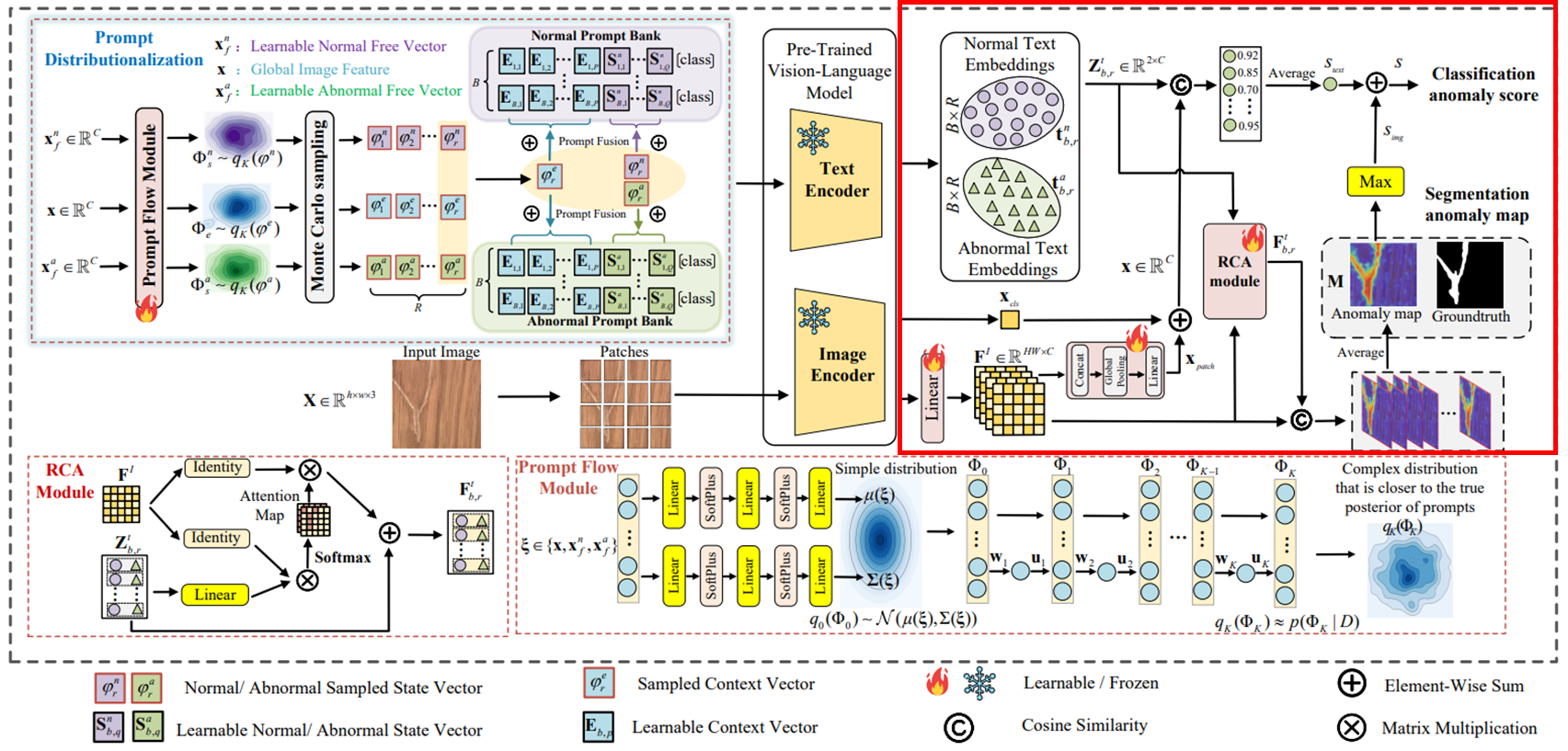
Prompt flow module : 텍스트 프롬프트 공간을 확률 분포로 모델링하고 학습하는 역할. 이를 통해 Image-Specific Distribution (ISD)와 Image-Agnostic Distribution (IAD)를 학습
RCA module : 이미지 특징과 텍스트 임베딩 간 정렬을 개선
워크플로우
- 입력 이미지 은 patch-level feature로 추출된 후 single linear projection을 거쳐 로 변환. 여기서 , 이고, 는 joint embedding space의 채널
- Prompt flow module은 context words를 위한 image-specific distribution 와, 정상/이상 state words를 위한 image-agnostic distribution 를 학습
- 학습된 세가지 분포에서 Monte Carlo 샘플링을 통해 을 샘플링하고, 이들은 prompt bank와 융합되어 다양한 텍스트 프롬프트를 생성하게 됨
- RCA 모듈을 사용하여 생성된 텍스트 임베딩 을 patch-level 이미지 특징 와 정렬하여 개선된 텍스트 임베딩 을 얻고, 이를 활용하여 최종 anomaly map 을 도출
3.2. Two-Class Prompt Banks
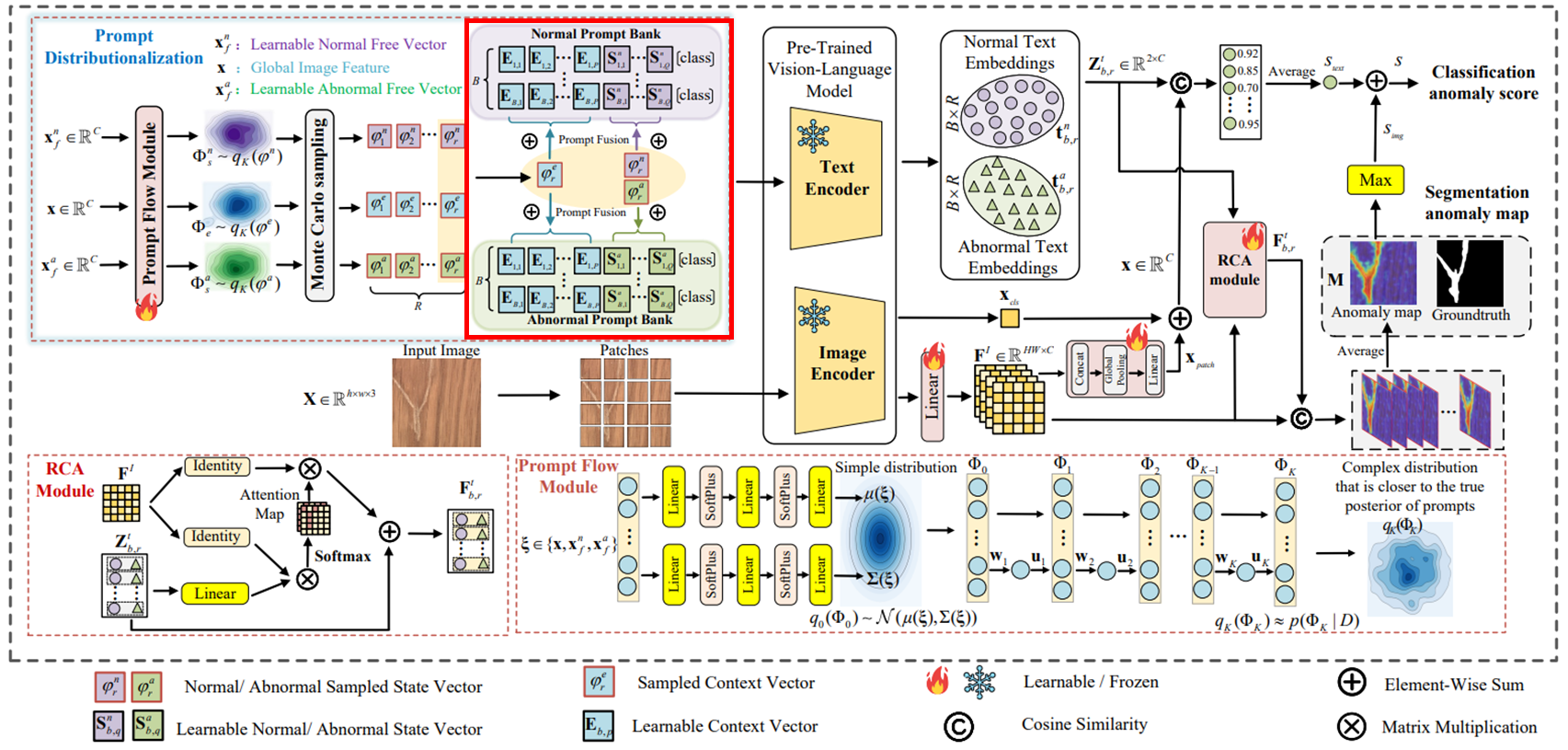
텍스트 프롬프트를 context words, state words, class words 이렇게 세 가지로 분해해서, state words를 수동을 설계하고 context words만 최적화하던 이전 프롬프트와는 다르게 state words(normal, abnormal)은 여전히 최적화 가능한 프롬프트 공간 내에 있다고 주장
따라서 기존의 수동으로 설계된 context words와 state words를 learnable vector인 로 대체하고, WinCLIP의 Compositional Prompt Ensemble에서 영감을 받아 정상 케이스와 이상 케이스를 위한 각각의 메모리뱅크 를 구축
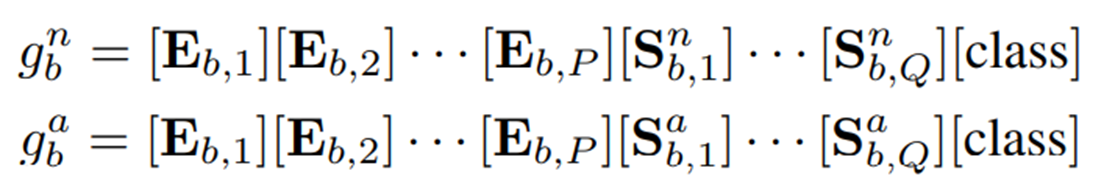
여기서 는 프롬프트 뱅크 내 개별 프롬프트 인덱스이며, 는 텍스트의 contextual 정보를 인코딩하도록 설계된 벡터, 그리고 는 각각 학습 가능한 정상/이상 state 벡터
이 때, 동일한 프롬프트 뱅크에서 생성된 텍스트 임베딩 간 직교성을 강제하여 프롬프트 내에서 포착되는 정상 및 이상의 다양성을 높임
3.3 Prompt Distributionalization
Bayesian Inference
보조 데이터셋을 (이고, 각각 입력 이미지, image-level 레이블, pixel-level 레이블) 라고 할 때, 텍스트 프롬프트 분포를 구성하기 위한 context, normal state, abnormal state 단어 임베딩들은 차원의 랜덤 벡터인 로 표현되고, posterior probabilities는 아래와 같이 계산됨
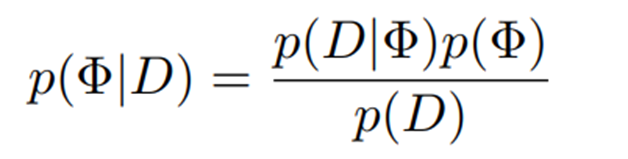
이 때 marginal likelihood 를 계산하는 것은 어렵기 때문에 해당 사후 확률을 근사하기 위해 로 매개화된 분포 를 사용한 variational inference가 수행되며, 이 때 모든 변수는 상호 독립적인 mean-field 가정 하에서 작동
Jensen 부등식을 적용하면 학습 데이터의 log marginal likelihood에 대한 upper bound가 도출된다.
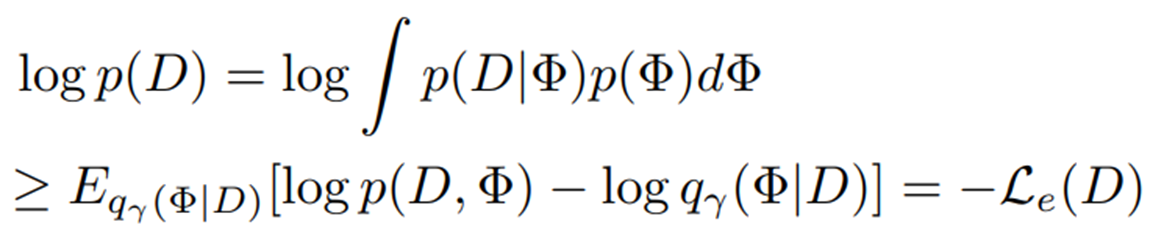
따라서, variational distribution 의 ELBO는 loss 를 최소화하여 얻을 수 있다.
Prompt flow module

더 풍부한 posterior approximation을 통해 프롬프트 분포를 더 잘 추정할 수 있다. 따라서 prompt flow module은 간단한 확률 분포 을 일련의 가역적 mapping 를 통해 보다 복잡한 분포 로 변환한다.
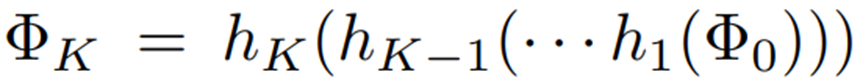
이러한 가역적 변환 덕분에, 최종 분포 의 log density를 초기 분포 와 각 변환의 야코비안 행렬식을 이용하여 정확하게 계산할 수 있으며, 이는 모델이 복잡한 프롬프트 분포를 유연하게 학습할 수 있도록 한다.
이 때 모델 효율성을 위해 의 선형 변환을 사용한다.
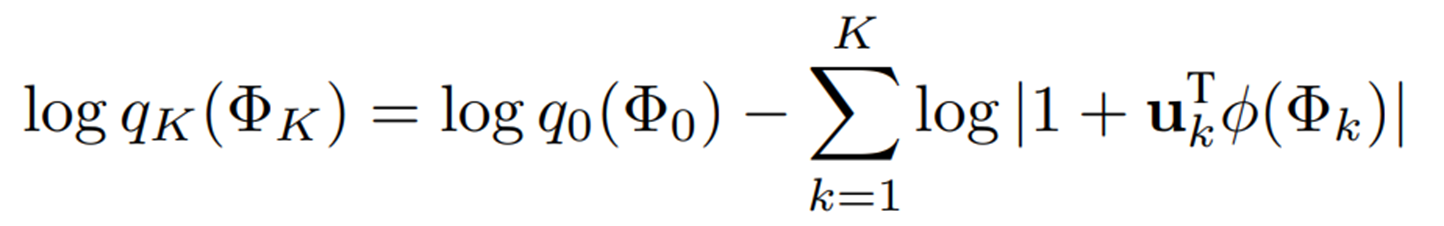
여기서 는 이다. 를 로 대체함으로써, prompt flow module을 최적화하는 목적함수는 아래와 같이 계산된다.
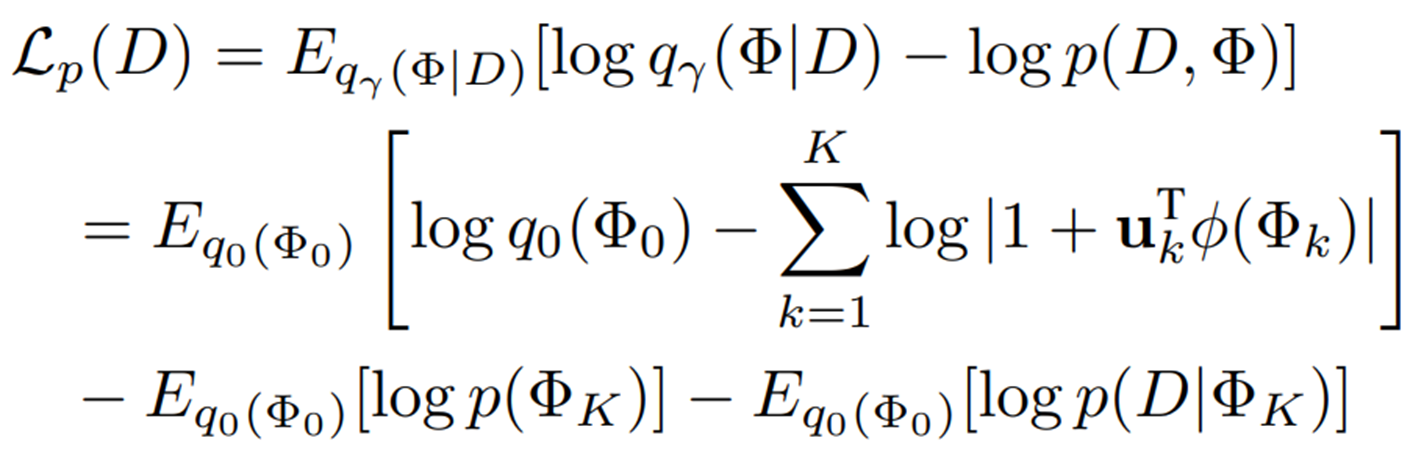
여기서 사전 분포는 을 따르며, 초기 밀도 는 표준 정규 분포로 정의되는데, 벡터 에 의해 조건화된 가우시안 분포 로 정의된다. 여기서 와 는 를 입력으로 받는 linear layer를 통해 파라미터화된다.
입력받는 에 따라 Image-Specific Distribution (ISD)과 Image-Agnostic Distribution (IAD) 두 종류의 분포를 얻게 되며, ISD의 경우 는 전역 이미지 특징 로 설정되어 context distribution을 모델링하고 unseen 도메인에서 일반화를 향상시키는 dynamic distribution을 획득한다. IAD의 경우 는 학습 가능한 자유 벡터 와 로 각각 설정하는 동시에 같은 네트워크 가중치를 공유한다. 이러한 static distribution은 정상/이상 조건 모두에 대한 통합된 state semantics를 학습하는 데 사용된다.
Prompt sampling and fusion
Monte Carlo 샘플링은 초기 밀도 에서 번의 반복으로 샘플링한다. 샘플링된 결과는 prompt flow 모듈을 통해 처리되어 을 얻는다. 이는 샘플링 된 context 벡터, 정상 state 벡터, 이상 state 벡터를 나타낸다. 이후 fusion 프로세스는 아래와 같이 공식화 된다.
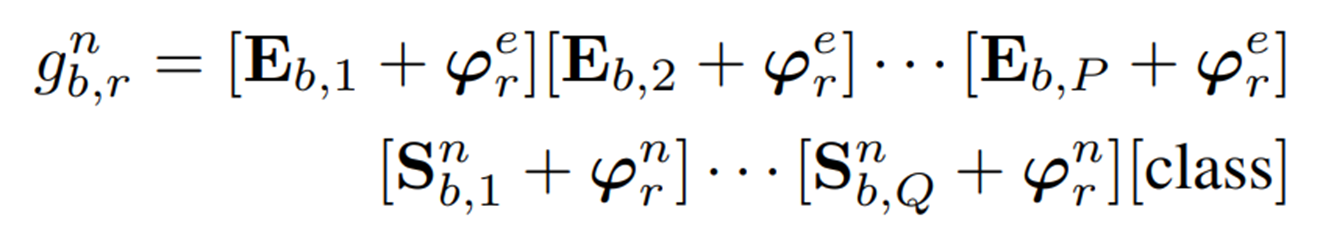
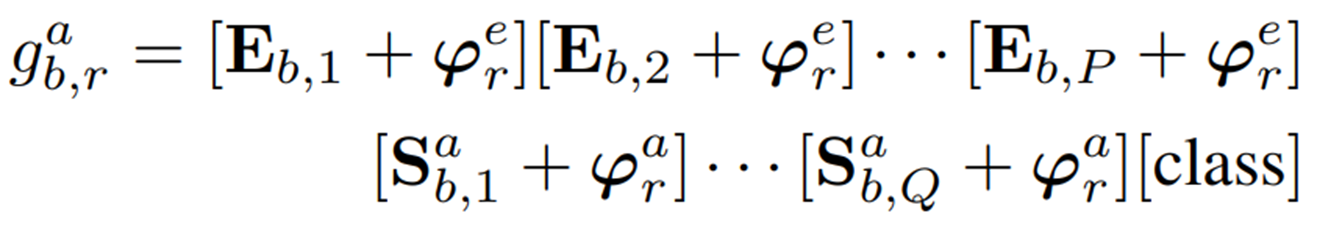
여기서 은 각각 프롬프트 뱅크에서 번째 프롬프트의 번째 샘플링에서 얻은 텍스트 프롬프트를 나타낸다. 샘플링 및 융합 후, 각 뱅크의 프롬프트 수는 로 증가하고, 이산 샘플링 후 적절한 기울기 역전파를 보장하기 위해 최적화 과정에서 reparameterization method가 사용된다.
3.4. Residual Cross-modal Attention Module (RCA Module)
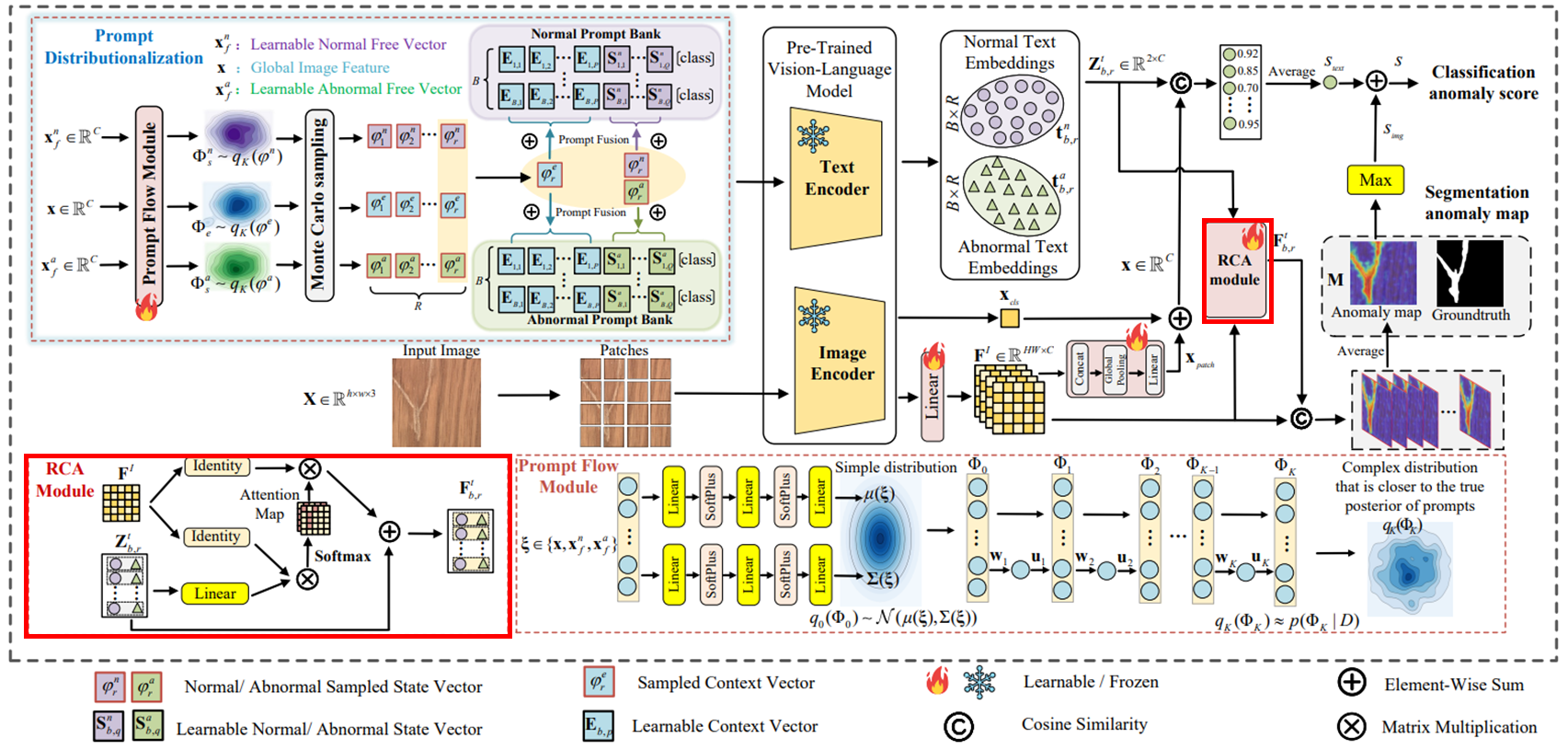
텍스트 인코더를 통해 텍스트 프롬프트에서 파생된 정상/이상 텍스트 임베딩은 로 표현된다. 이미지에 특화된 분포 및 Monte Carlo 샘플링으로 인해 생성된 텍스트 임베딩은 학습 및 추론 중에 동적으로 변한다. 이는 anomaly segmentation 작업에서 텍스트 임베딩 (를 concat한 결과)를 fine-grained 패치 임베딩 와 정렬하는 데 어려움을 야기하기 때문에, RCA 모듈을 통해 텍스트 및 fine-grained 이미지 특징 간 cross-modal 상호 작용을 일으키며, 아래와 같이 공식화 된다.
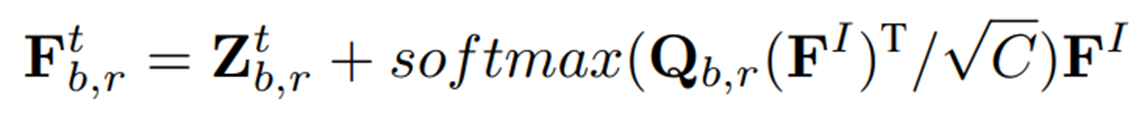
여기서 은 조정된 텍스트 임베딩이다. 쿼리 임베딩 은 이며, 는 linear mapping layer의 가중치 행렬이다.
RCA 모듈은 더 나은 zero-shot 성능을 위해 기존 텍스트 특징과 cross-modal 특징을 융합하고, 프롬프트 뱅크로의 기울기 역전파를 가능하게하여 학습 가능한 프롬프트의 최적화를 개선한다.
3.5. Anomaly Map and Anomaly Score
Pixel-level Anomaly map
레이어의 patch-level 특징 을 추출하고 텍스트 임베딩 과 정렬한다. 이 때 번째 layer의 anomaly map은 아래와 같이 계산된다.
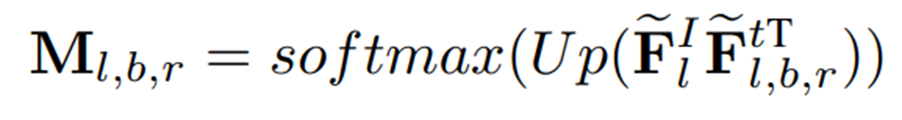
은 L2 정규화 연산을 나타내고, 는 upsampling 연산을 나타낸다. 최종 결과 는 layer의 패치 특징을 의 조정된 텍스트 임베딩과 정렬하여 얻은 anomaly map을 평균 하여 얻는다.
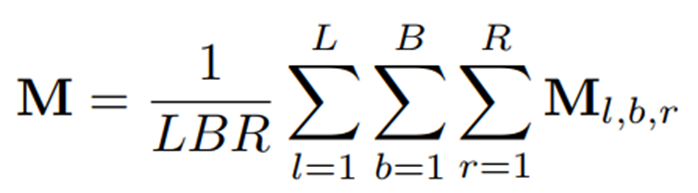
Image-level Anomaly map
Anomaly 분류를 위해 이상 값은 텍스트와 이미지 branch 모두에서 가져온다. Text branch의 anomaly score는 아래와 같이 계산된다.
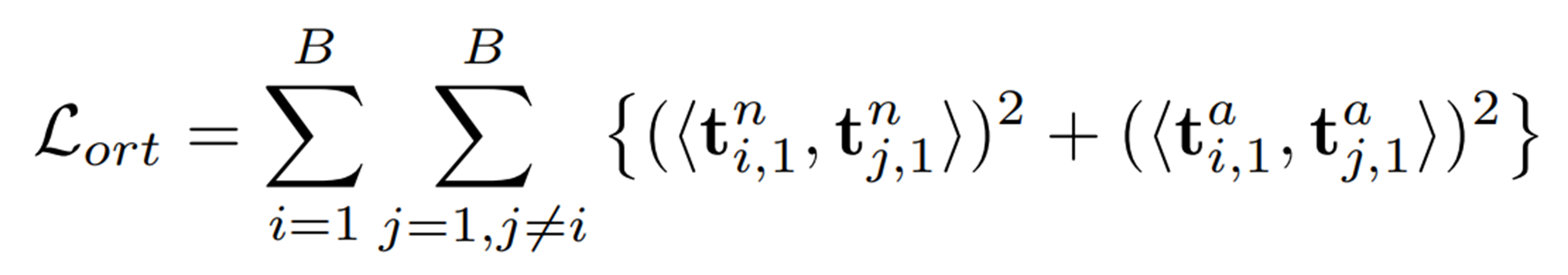
여기서 는 global 이미지 임베딩이다. 는 vanilla 이미지 인코더의 클래스 토큰에서 얻은 global 이미지 특징을 나타내고, 는 fine-grained 패치 특징의 융합으로 얻어진다. 우선 는 채널 차원을 따라 연결된 후, 공간 차원을 따라 global average pooling이 적용되고, 그 뒤에 결과를 에 mapping하는 선형 layer가 이어진다. image branch의 anomaly score는 anomaly map의 최대값으로 계산된다. () 그렇게 최종 image-level anomaly score는 와 를 합한 결과로 사용된다.
3.6. Loss Function
학습 단계에서는 효율성을 높이기 위해 단일 Monte Carlo 샘플링이 수행된다. 샘플들의 텍스트 프롬프트를 로, 해당 텍스트 임베딩을 로 나타낼 때, 프롬프트 뱅크에서 학습 가능한 프롬프트의 다양성을 높이기 위해 텍스트 임베딩에 아래와 같은 직교 손실을 설계한다.
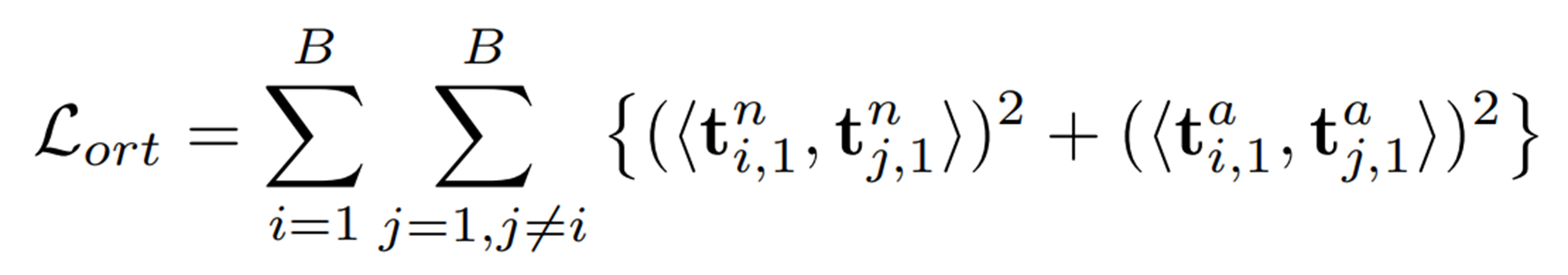
여기서 는 코사인 유사도이며 최종 손실 함수는 아래와 같이 표현된다.
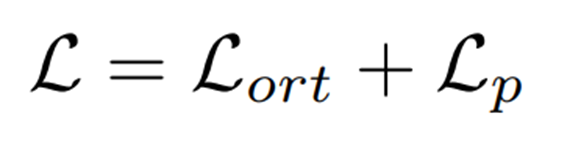
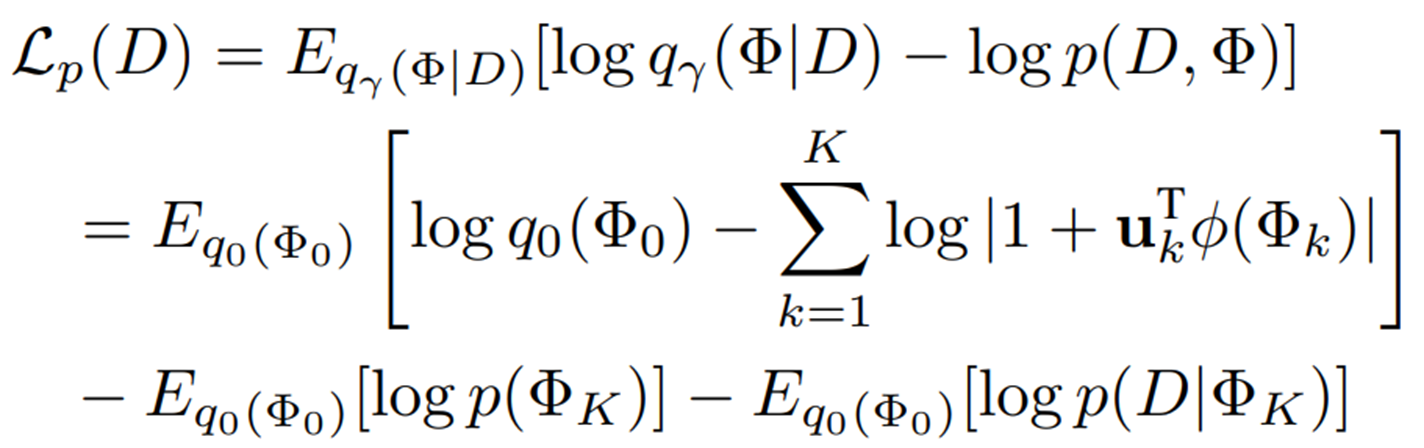
여기서 는 위에서 언급한 prompt flow loss 이다. 의 첫 두 term은 초기 분포 를 간단한 prior 분포 로 조정하여 latent variables의 분포를 효과적으로 제어하는 regularization term이다.
해당 정규화는 prompt flow module이 효과적인 프롬프트 분포를 학습하여 과적합을 완화하고 프롬프트의 일반화를 향상시키도록 보장한다.
세 번째 term은 데이터의 log-likelihood를 최대화하며, 이는 classification loss(텍스트-이미지 정렬)와 segmentation loss(텍스트-패치 정렬)의 합으로 근사된다.
4. Experiments
4.1. Experimental Setup
Datasets
산업 분야, 의료 분야의 총 15개 데이터셋을 사용하였으며 보조 데이터셋으로는 산업 도메인의 VisA 데이터셋 사용, VisA를 평가할 땐 MVTec-AD 데이터셋을 사용
Evaluation Metrics
Image-level : AUROC (Area Under the Receiver Operating Characteristics), F1-max, AP (Average Precision)
Pixel-level : AUROC, AP, PRO (Per-Region Overlap)
Implementation Details
-
Backbone은 사전 학습된 CLIP ViT-L-14-336 모델 사용
-
입력 이미지 해상도는
-
패치 임베딩은 6, 12, 18, 24 번째 layer에서 추출
-
프롬프트 뱅크의 프롬프트 수는 3으로, prompt flow 길이는 10으로 설정
-
학습 가능한 context vector와 state vector 길이는 모두 5로 설정
-
Monte Carlo 샘플링 횟수는 학습 땐 1회, 테스트 때는 10회 수행
4.2. Comparison with State-of-the-art methods
Quantitative Comparison
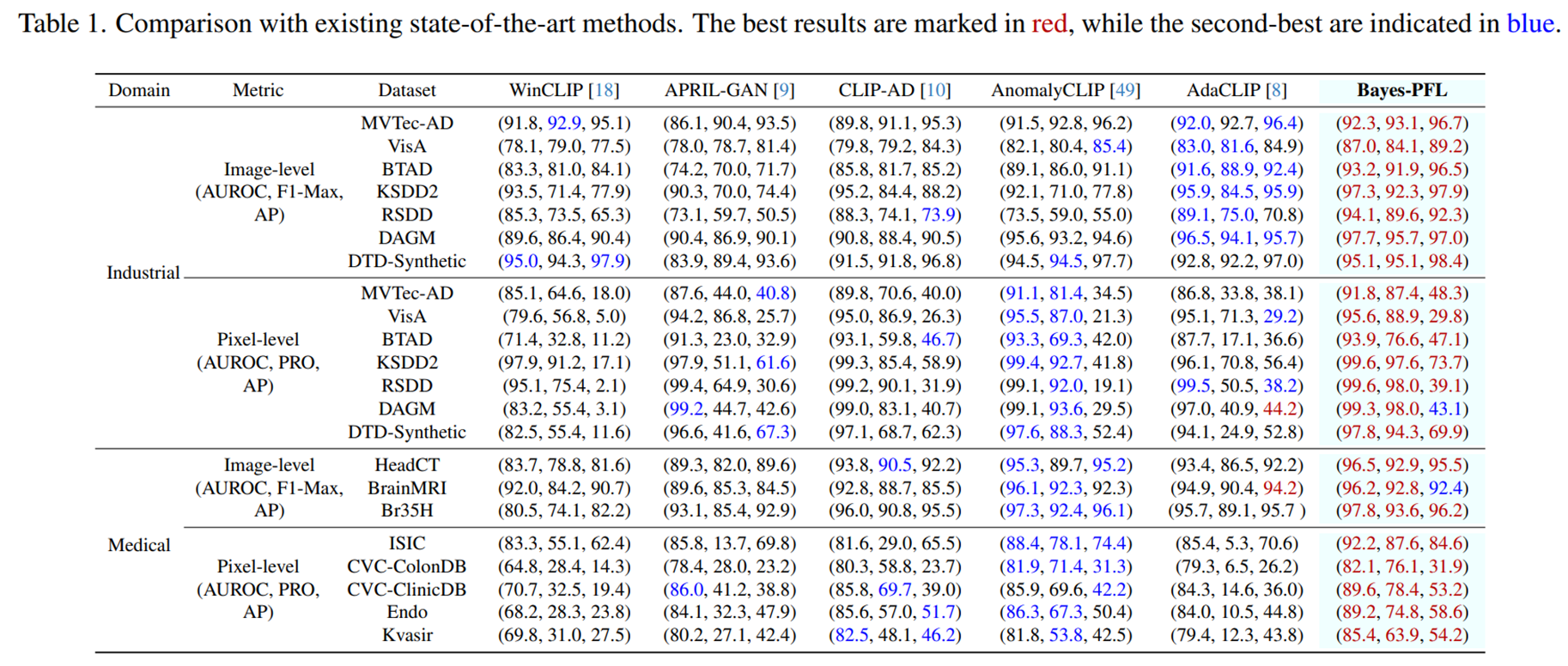
- 저자들이 제안하는 Bayes-PFL은 거의 모든 데이터셋에서 image-level 및 pixel-level에서 SOTA 달성
- AdaCLIP의 낮은 PRO 성능은 예측된 anomaly score의 높은 분산과, 큰 이상 영역을 효과적으로 감지하는 능력의 한계 때문으로 분석
- Bayes-PFL은 분포 샘플링을 통해 더 넓은 프롬프트 공간을 탐색하여 넓은 이상 영역 감지 능력을 향상
Qualitative Comparison

- Bayes-PFL은 다른 방법론에 비해 더 정확한 segmentation 결과와, 더 완전한 이상 영역 localization을 달성하였음
- 특히 의료 도메인의 카테고리에서 상당한 우위를 보임
Performance comparison at different training epochs
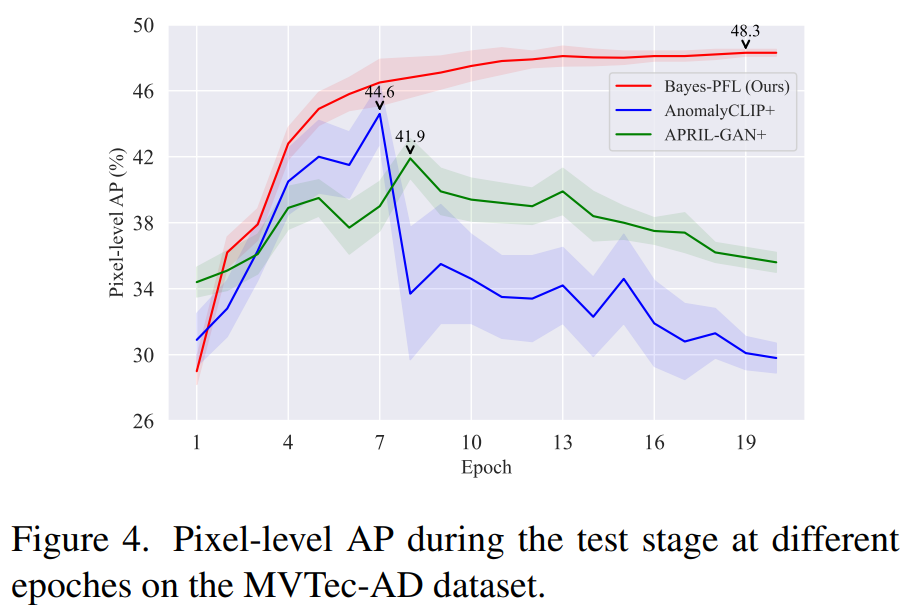
- Bayes-PFL은 학습 전반에 걸쳐 안정적이고 지속적으로 개선되는 AP를 보여주며, APRIL-GAN+ 및 AnomalyCLIP+를 능가하였다.
4.3. Image-specific vs. Image-agnostic distribution
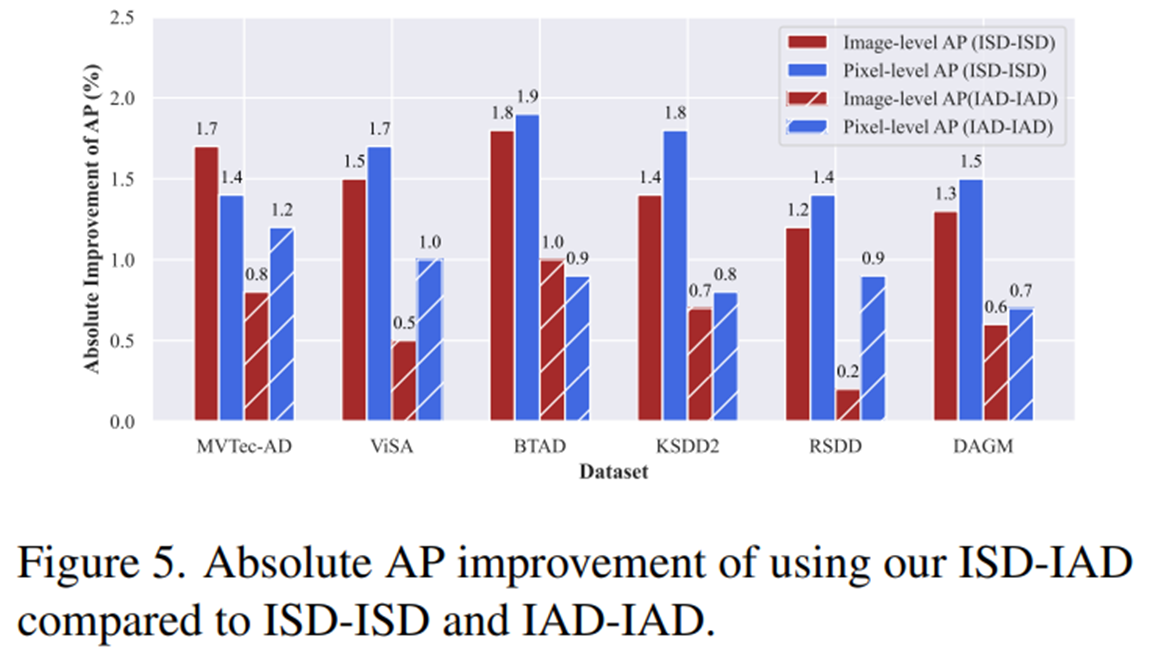
- Contextual, state words 각각에 모두 ISD-ISD나 IAD-IAD를 조합하는 것보다, contextual words에는 ISD를, state words에는 IAD로 모델링하는 것이 가장 성능이 좋았다.
4.4. Ablation
Influence of different components
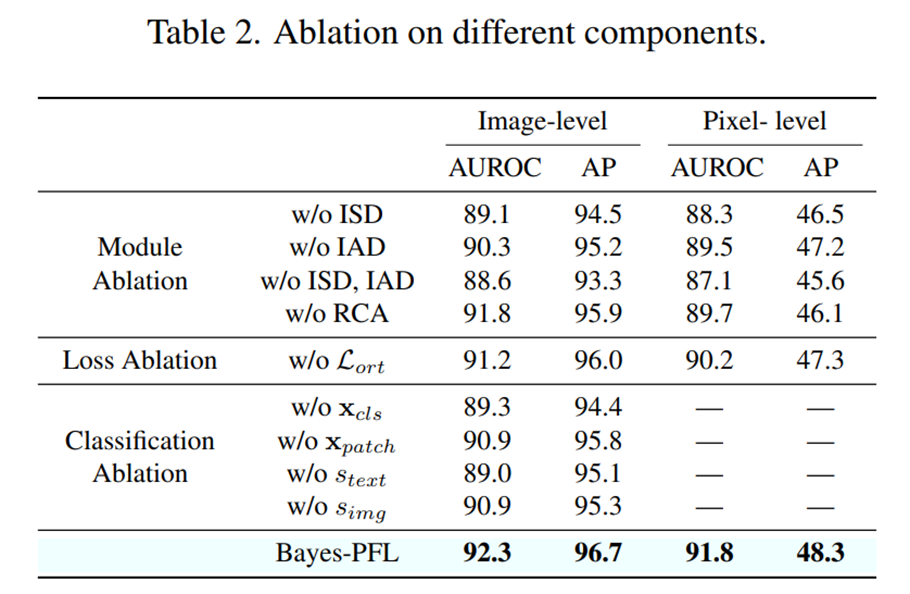
- Module ablation에서는 프롬프트 모듈의 ISD 및 IAD 또는 RCA 모듈을 제거했을 때 성능 저하로 이어졌다. 특히 ISD를 제거했을 때 IAD를 제거했을 때 보다 성능 저하가 컸는데, 이는 이미지에 따라 동적으로 조절되는 context distribution 모델링이 일반화 능력에 더 큰 영향을 미친다는 것을 시사한다.
- Loss ablation에서는 직교 손실을 사용하지 않았을 때 image 및 pixel-level 지표에서 약 1%p의 성능 하락이 있었다.
- Classification ablation에서는 image-level anomaly score 계산에 사용되는 , , , 중 어떤 것을 제거하더라도 성능 하락으로 이어졌다. 이는 text 및 image branch 결과가 서로를 보완하며, CLIP 모델이 global image features에 미세한 patch features를 통합하는 것이 분류 성능을 향상하는 데 도움이 됨을 나타낸다.
Influence of the number of sampling iterations
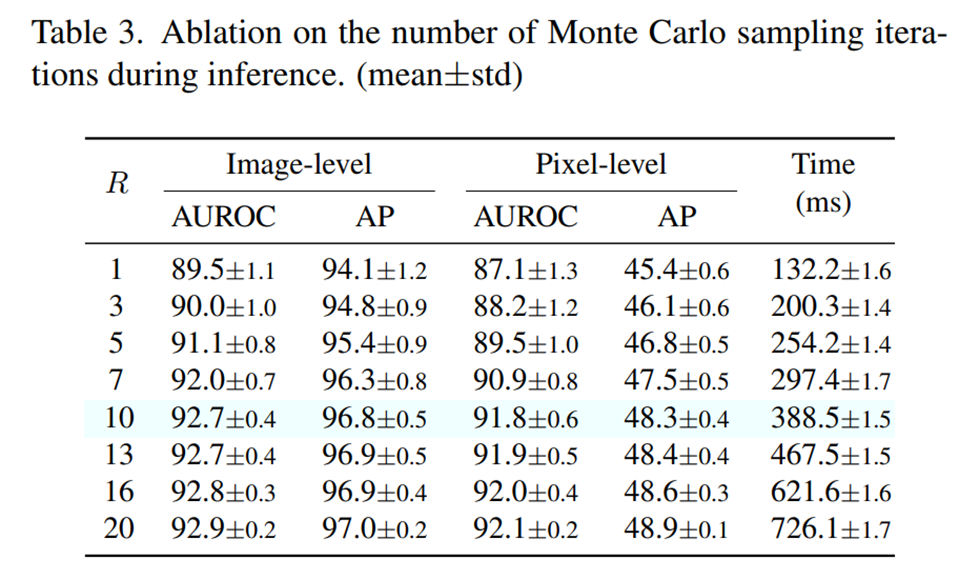
- 추론 단계에서 Monte Carlo 샘플링 반복 횟수가 증가함에 따라 모델의 일반화 성능과 안정성이 향상되었다.
- 하지만 반복 횟수가 증가하면 추론 시간도 길어지는 trade-off가 발생하므로, 본 논문에서는 R=10을 기본값으로 하여 성능과 효율성 간의 균형을 맞추었다.
Influence of the ensemble mode
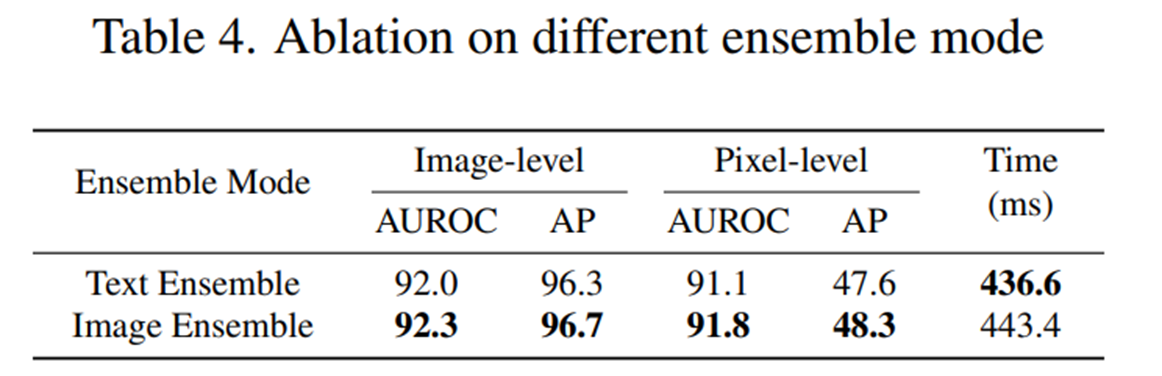
- 텍스트 임베딩을 먼저 평균한 다음 이미지 특징과 정렬하는 text ensemble과, 이미지 특징을 개별적으로 먼저 정렬한 다음 이상 점수 또는 맵을 평균하는 image ensemble을 실험한 결과, image ensemble이 text ensemble보다 더 우수한 ZSAD 성능을 보였으며, 추론 효율성은 비슷하였다.
