[논문 리뷰] Towards Zero-Shot Anomaly Detection and Reasoning with Multimodal Large Language Models (CVPR 2025)
논문리뷰

1. Introduction

- Visual Anomaly Detection (VAD)는 산업 결하 검사 및 의료 영상 진단과 같은 시나리오에서 광범위하게 적용됨
- 기존에 가정되는 상당한 양의 정상 샘플의 가용성은 엄격한 데이터 개인 정보 보호 정책과 데이터 분류에 필요한 상당한 인적 노력으로 인해 특정 시나리오에서는 비현실적이며, 따라서 Zero-Shot Anomaly Detection (ZSAD)은 최근 인기 있는 패러다임으로 부상하였음
- Multimodal Large Language Models (MLLMs)의 최근 발전은 다양한 비전 task에서 혁신적인 추론 능력을 보여주었으나, 대규모 데이터 셋을 수집하고 벤치마크를 설정하는 데 어려움이 있어 이미지 이상에 대한 추론은 아직 탐구되지 못한 영역임
- 위 그림과 같이 GPT-4o와 같은 최신 MLLM들은 아직 Anomaly Detectinon 및 inference에서 설명 정확성과 이상에 대한 포괄적인 이해에 부족함
- 따라서 AD 추론에 대한 연구를 가속화하기 위해, 저자들은 최초의 visual instruction tuning dataset인 Anomaly-Instruct125k와, 평가 벤치마크인 VisA-D&R을 구축하였음
- 추가로, 현재 일반적인 MLLM들의 부족한 ZSAD 능력을 극복한 최초의 visual assistant인 Anomaly-OneVision (Anomaly-OV)를 제안함
2. Related Work
Multimodal Large Language Models
- CLIP과 같은 Vision-Language Models (VLM)은 강력한 zero-shot 분류 성능을 보여주며 다양한 downstream vision task에 적용되었음
- VLM의 비전 인코더와 LLM을 결합하여, MLLM은 visual content와 관련된 텍스트 기반 상호 작용을 가능하게 함
- 특히 MLLM은 Chain-of-Thought와 같은 프롬프팅 전략과 결합될 때 놀라운 추론 능력을 보여주었음
Unsupervised Anomaly Detection
- 이상 데이터의 부족과 수집의 어려움으로 인해, AD 모델을 학습하기 위한 주된 설정은 정상 데이터만을 사용하는 unsupervised 방식으로 수행됨
- Reconstruction-based, student-teacher 및 augmentation 기반 접근 방식과 같은 초기 연구에서는 많은 양의 정상 데이터를 사용할 수 있다고 가정하나, 이러한 접근 방식은 의료 영역에서와 같이 데이터가 제한적이거나 비쌀 때 덜 실용적
Zero-Shot Anomaly Detection
- Zero-Shot Anomaly Detection (ZSAD)는 대상 객체에 특정한 데이터를 요구하지 않고 주어진 이미지에 대한 이상 가능성에 직접 접근
- 기존 연구에서는 CLIP의 비전 및 텍스트 인코더에 의해 인코딩된 시각적 및 텍스트 특징을 비교하고 아래와 같은 형식으로 정상/이상 프롬프트를 구성하여 ZSAD를 수행한 연구가 다수 수행되었음
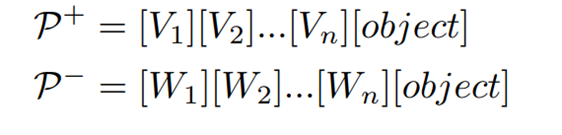
- 여기서 와 는 수작업으로 만들거나 학습 가능한 토큰이고, object는 단어 “object” 또는 객체의 클래스 이름을 나타냄
- 그러나 단순히 “object”라는 단어를 사용하여 모든 종류의 객체를 나타내는 것은 class-awareness 이상 유형을 포착하기엔 제한됨
3. Method
3.1. Preliminary
MLLM을 처음부터 학습시키는 것은 vision 및 text 임베딩 공간을 정렬하고 강력한 instruction-following 능력을 개발하기 위한 광범위한 데이터와 컴퓨팅 자원을 필요로 한다.
최근 연구에 따르면 사전 학습된 MLLM은 광범위한 knowledge base를 갖고 있지만 특정 분야에서는 성능이 저조하다. 따라서 본 연구의 목표는 해당 generalist가 중요한 visual tokens를 선택하고 활용하도록 안내하기 위해 설계된 auxiliary specialist 혹은 expert model을 도입하는 것이다. 해당 방식은 기존 모델의 일반화능력을 유지하면서 대규모 사전 학습의 필요성을 피할 수 있다.
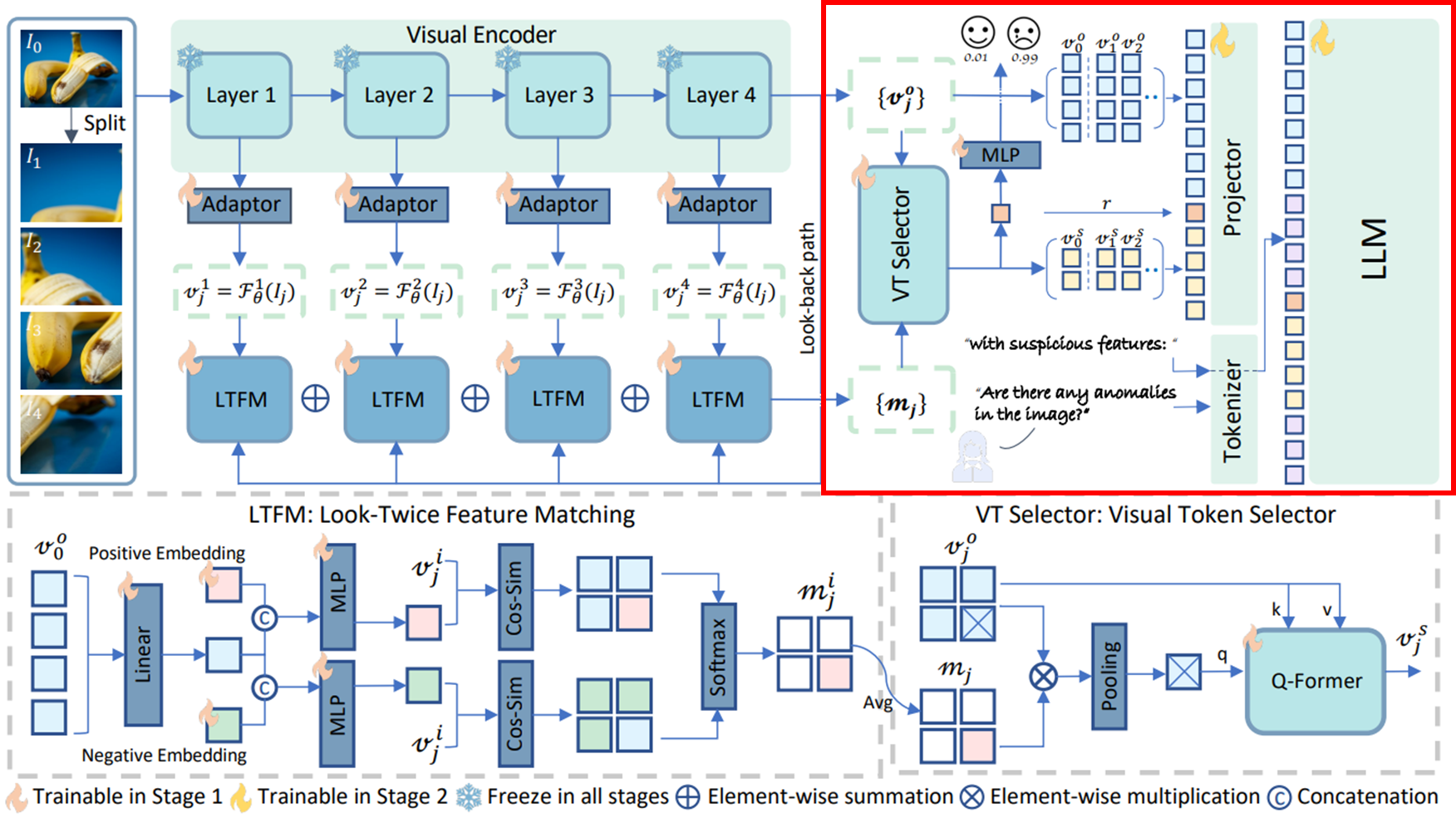
저자들은 오픈소스이며 다른 상용 모델과 유사한 성능을 보이는 LLaVA-OneVision을 base MLLM으로 선택한다. 이는 세 가지 주요 구성 요소인 visual encoder, projector, 및 LLM으로 구성된다.
- Visual Encoder: Raw 이미지에서 시각 정보를 추출
- Projector: 시각 특징의 공간을 단어 임베딩과 정렬
- LLM: 텍스트 명령어 처리 및 복잡한 추론
3.2. Architecture Overview
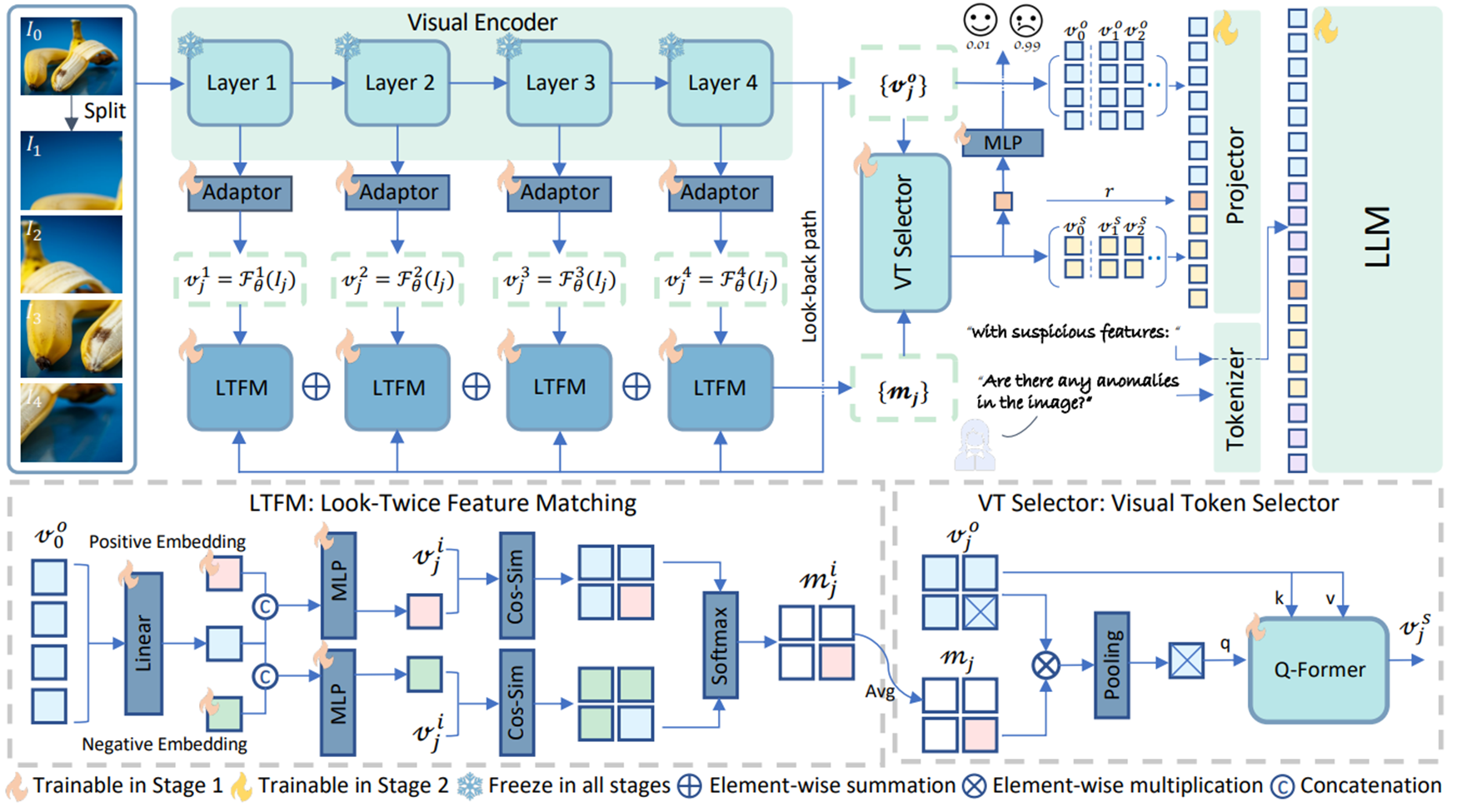
- LLaVa-OneVision과 동일한 image-splitting 전략인 AnyRes를 사용하여 입력 고해상도 이미지는 여러 crop으로 분할되며, 새로운 이미지 셋은 로 다시 쓸 수 있다. 여기서 은 크기가 조정된 원본 이미지이고, 은 이미지 crop을 나타낸다.
- 위 그림에서 확인할 수 있듯 이미지 셋 는 visual encoder 에 의해 처리되어 최종 visual feature 를 출력한다. AnomalyCLIP과 유사하게 ViT에서 선택된 4개 layer의 출력을 저장하여 multi-level의 이미지 표현을 포착하고 4개의 adaptor를 적용하여 차원을 압축하여 를 얻게 되는데, 여기서 는 번째 layer에서 추출된 것을 의미하고, 는 에서 해당 이미지 인덱스를 나타낸다. 이를 통해 fine-grained local semantics를 효과적으로 포착할 수 있다.
- 이러한 이미지 특징은 이미 ZSAD에 필요한 클래스 정보를 포함하고 있다. 객체 분류에 대한 사람의 개입을 피하고 모델 복잡성을 피하기 위해 일반적으로 사용되는 텍스트 인코더를 제거하고, visual model 자체가 의심스러운 클래스 또는 객체에 대한 정보를 구문 분석하도록 한다.
- 원본 이미지에 대한 출력 은 look-back path에서 대상 객체 또는 영역에 대한 global description을 제공하는 데 활용된다. Multi-level 특징과 global embedding을 통해 LTFM 모듈은 의심스러운 토큰의 인식 및 localization을 담당한다.

- ① 의심스러운 객체 또는 영역을 식별한 다음 ② 자세히 검사하는 인간의 visual inspection에서 영감을 얻어, 중요한 시각 토큰을 집계하고 이상 탐지 및 추론에 대한 지침을 처리할 때 LLM이 이러한 토큰을 많은 관련 없는 토큰과 명시적으로 구별하도록 지원하는 VT selector 모듈을 설계한다.
- 원본 시각 특징은 “Can you describe the content of the image?”와 같은 일반적인 지침에 대한 base model의 일반화 성능을 유지하기 위해 보존된다.
이제 저자들이 제안하는 LTFM 모듈과 VT selector 모듈을 자세히 살펴보자
3.3. Look-Twice Feature Matching (LTFM)
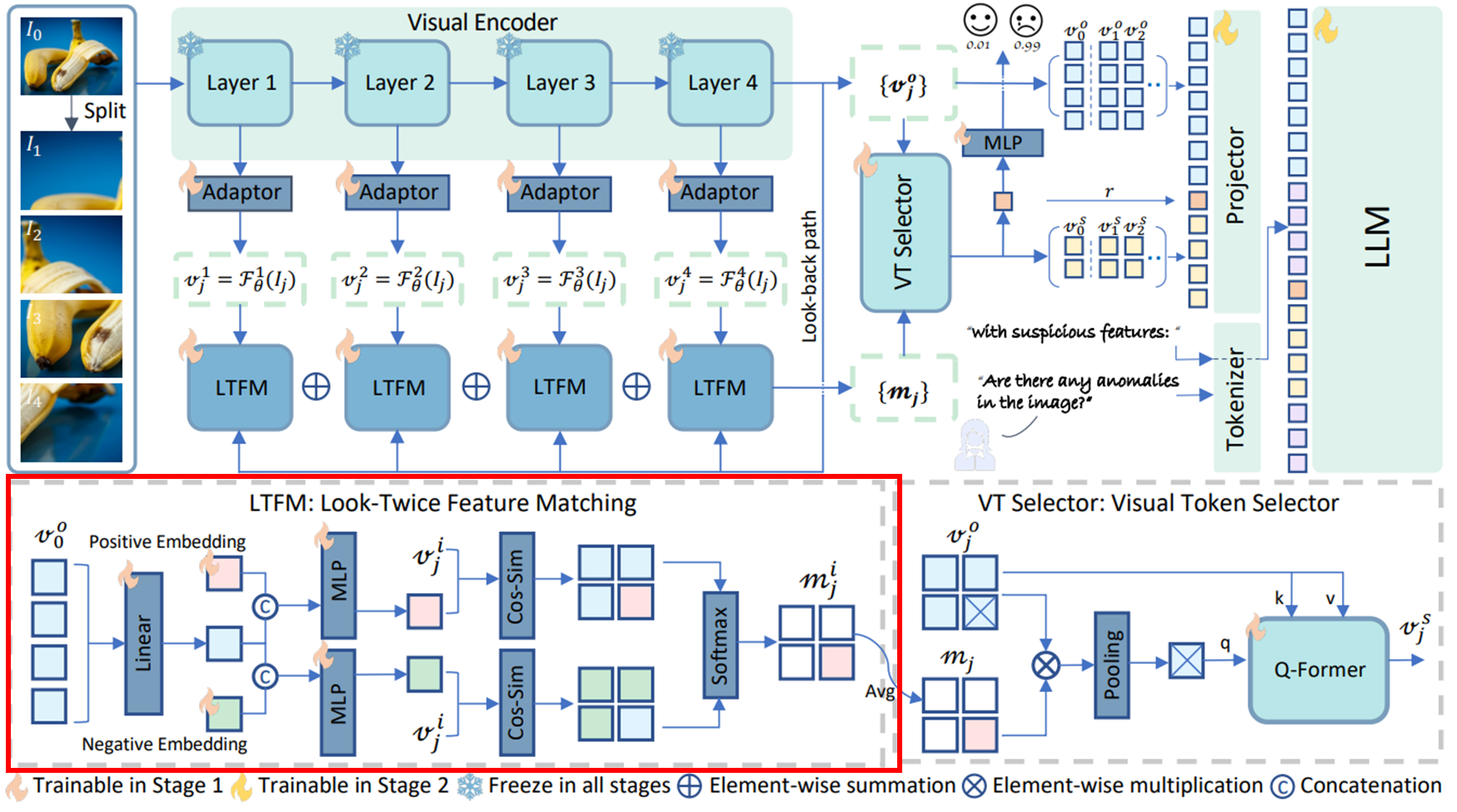
Look-back path에서 제공하는 global 객체 정보 가 주어지면 이를 두 개의 학습 가능한 두 개의 임베딩 와 (각각 정상과 이상)와 병합하여 class-awareness abnormality description을 생성한다.
구체적으로, linear layer 가 token 차원에 따라 적용되어 에서 유용한 토큰을 선택하고 융합한 다음, 융합된 벡터는 와 와 독립적으로 연결되고 두 개의 MLP 를 통과하여 normality/abnormality description 를 얻는다. 이 과정을 수식으로 나타내면 아래와 같다.
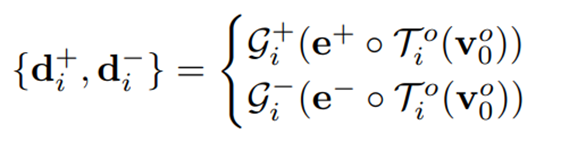
이 때 서로 다른 layer에서 추출된 visual features는 서로 다른 크기의 의미론에 집중하고, 그렇기에 와 의 파라미터는 각 layer마다 독립적으로 분리시킨다.
그리고, CLIP 모델의 zero-shot 분류 메커니즘과 유사하게 아래와 같이 코사인 유사도와 소프트맥스 연산을 결합하여 의 각 패치 토큰이 비정상 패턴에 속할 가능성을 계산한다.
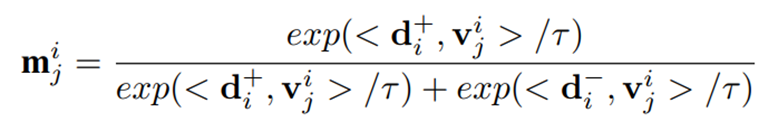
여기서 는 visual tokens에 대한 중요도 맵을 나타내고, 는 temperature 하이퍼파라미터이며, 는 코사인 유사도 연산자를 나타낸다. 의 패치 가중치는 해당 visual token이 비정상 토큰에 얼마나 가까운지를 나타낸다.
이후 모든 맵을 평균화하여 low-level에서 high-level까지 토큰 중요도를 포착한다.
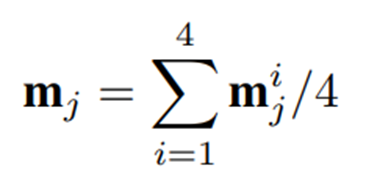
시각 특징은 순방향 및 look-back path에서 두 번 활용되므로 해당 모듈은 Look-Twice Feature Matching이라고 명명되었다.
3.4. Visual Token Selector
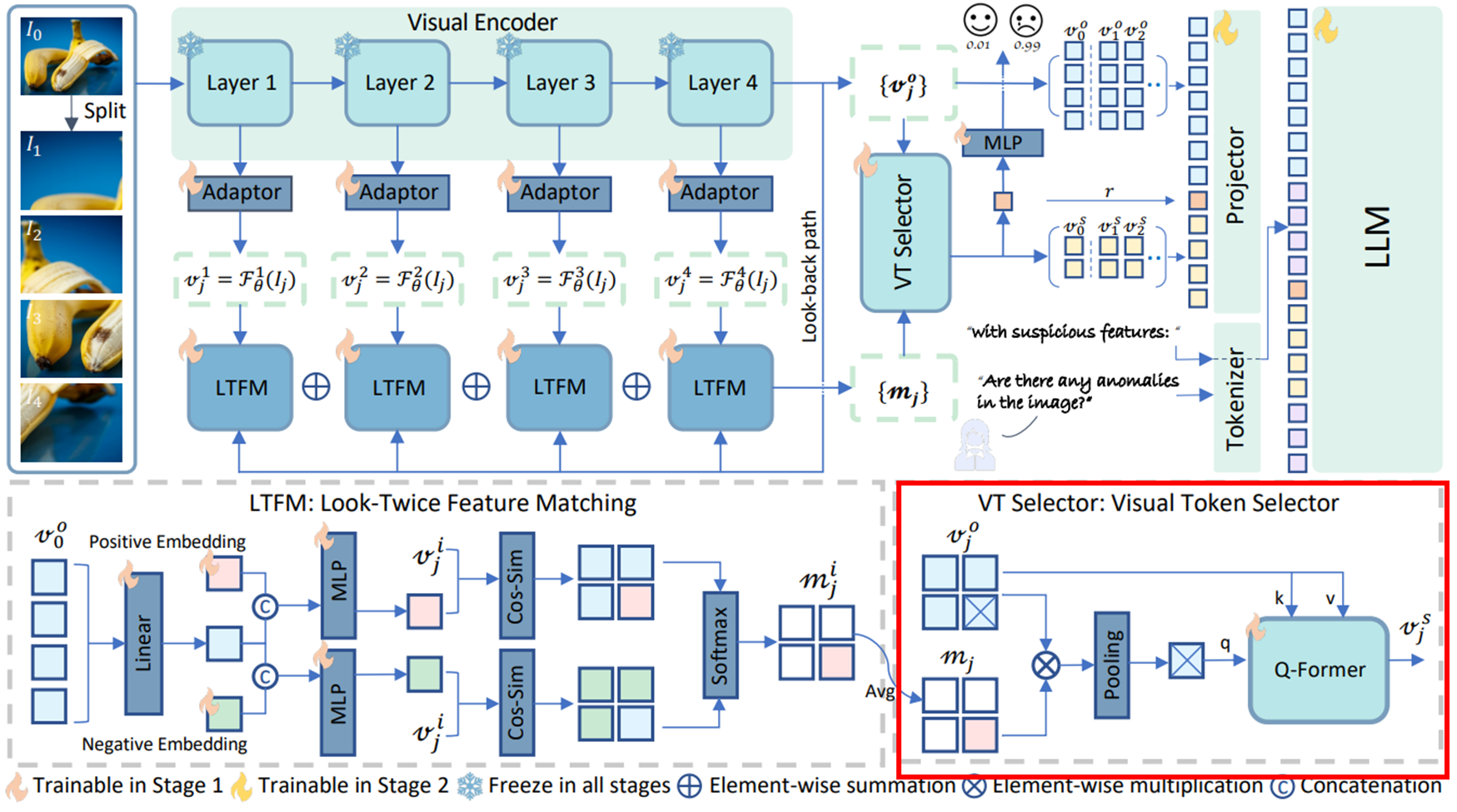
최근 MLLM에서 널리 적용되는 image cropping 전략에 따라, 고해상도 이미지에는 수 많은 visual token들이 있다. 이러한 토큰은 풍부한 시각적 세부 정보를 제공하지만 LLM은 특정 task에 적응할 때 가장 유용한 정보를 선택해야 한다. LLM에 해당 도메인에 대한 충분한 지식이 없다면 token 선택 프로세스가 복잡해 지기 때문에, 저자들은 어떤 토큰이 중요한지 아닌지를 알고 LLM이 중요한 토큰을 선택하고 확대하도록 specialist 또는 expert를 도입한다.
의 각 이미지 crop에 대해 인코딩된 visual token 와 해당 중요도 맵 가 주어지면, 의심스러운 토큰은 두 텐서를 직접 곱하여 강조 표시된다.이후 정상 토큰은 0으로 조정되고 비정상 토큰은 유지한 후 spatial average pooling 를 적용하여 토큰 수를 줄인다. 이는 아래와 같은 식으로 표현 가능하다.
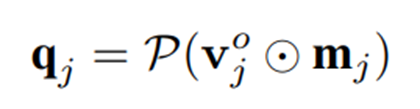
는 풀링된 쿼리 토큰을 나타내며, 경험적으로 로 설정하는 것이 가장 나은 trade-off를 제공한다.
이후 Q-Former 가 활용되어 를 쿼리로, 를 key 및 value로 적용하여 상관 관계가 있는 토큰을 집계한다.
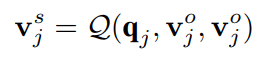
그렇게 VT Selector는 anomaly expert가 주어진 이미지에 대해 가장 의심스러운 의미를 포함하는 visual token을 직접 선택하는 데 사용하는 도구 역할을 하게 된다.
3.5. Inference and Loss
Anomaly Detection
전통적인 이상 탐지 task에서 모델은 이미지가 비정상일 가능성을 예측한다. Anomaly score 예측을 달성하기 위해 중요도 맵에 가중치를 둔 평균 연산을 통해 모든 이미지 crop에서 이상 정보를 집계한다.
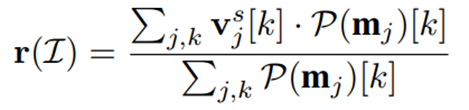
는 VT selector와 같은 spatial pooling이고 는 전체 이미지에 대한 global anomaly information을 포함하는 벡터이다.
이후 anomaly expert는 를 파싱하여 image-level anomaly score를 계산할 수 있다.
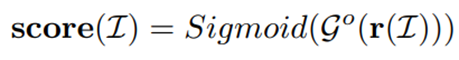
Text Generation
원래의 와 선택된 의 concatenation을 직접적으로 LLM의 input으로 넣는 대신, 두 토큰 시리즈 중간에 “ suspicious feature: “라는 indication prompt를 적용하여 이상 관련 instruction을 처리할 때 LLM에 대해 선택된 토큰을 강조 표시한다. 이러한 접근은 MLLM에서 프롬프트 엔지니어링의 한 형태로 간주될 수있으며, 는 {highly, moderately, slightly} 중에 선택되며 및 사전에 정의된 임계값 에 의해 선택된다. 입력 이미지 가 이상일 가능성이 높으면 LLM은 선택된 토큰에 더 큰 중점을 둘 것이고, 그렇지 않으면 이러한 토큰의 중요도는 떨어진다.
텍스트 생성은 LLM의 auto-regressive token 예측 메커니즘에 의해 구현된다.
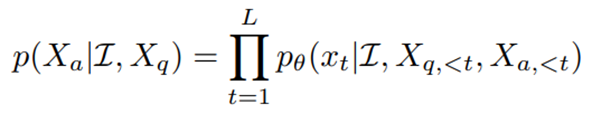
여기서 및 는 길이가 인 시퀀스에 대해 현재 예측 토큰 이전의 모든 이전 turn의 답변 및 명령 토큰이다.
전체 모델은 에 의해 파라미터화되고 각 예측된 답변 토큰 에 대해 기존 언어 모델 cross-entropy 손실에 의해 학습된다.
4. Dataset and Benchmark
이미지 이상 탐지 및 추론을 위한 multimodal instruction-following 데이터가 부족하면 해당 도메인에서의 special intelligent assistant의 개발은 제한된다. 따라서 본 연구에서는 데이터 부족 문제를 해결하기 위해 최초의 대규모 instruction tuning 데이터셋인 Anomaly-Instruct-125k와 해당 이상 탐지 및 추론 벤치 마크인 VisA-D&R을 구축한다.
4.1. Anomaly-Instruct-125k
기존의 이상 탐지 데이터 셋에는 이미지 캡션이 제공되지 않기에 GPT-4V 또는 GPT-4o도 명시적인 사람의 개입 없이 이미지에서 이상을 찾고 설명할 수 없다는 점을 해결하고자, 정확한 이상 설명 생성을 위한 새로운 프롬프트 파이프라인을 설계한다.
대부분의 데이터 셋에는 이상 유형에 대한 주석이 포함되어 있으므로 클래스 이름과 이상 유형을 수동으로 결합한다. (e.g., “A [capsule] with [poke] on surface”) 그리고 이상 마스크가 제공되면 이미지에 bounding box를 그려서 이상 영역을 강조 표시한다.
이렇게 짧은 설명과 bounding box가 있는 이미지를 사용하여 GPT-4o를 프롬프트하여 자세한 이미지 및 이상 설명을 생성한다. 이후, LLaVA와 유사한 in-context learning 전략을 사용하여 instruction을 만든다.
통합된 visual inspection 데이터 셋을 위해 MVTecAD, BMAD, Anomaly-ShapeNet, Real3D-AD, MVTec-3D AD로부터 정밀한 instruction 데이터가 수집되며, 이는 산업에서 의료 도메인에 걸쳐 2D-3D 데이터를 모두 포함한다. 3D point cloud 데이터는 9개의 multi-view 이미지로 변환되고, 해당 마스크는 사전에 정의된 카메라 위치를 사용하여 렌더링된다.
그러나 이러한 데이터 셋의 다양성과 규모는 상대적으로 제한적이므로 instruction data를 확장하기 위해 이미지 수집, 데이터 정제 및 instruction 생성을 위한 GPT-4o와 Google Image Search를 결합한 자동 이상 데이터 수집 파이프라인을 도입한다. 마지막으로, 이상 탐지를 목표로 하는 72,000개의 in-the-wild 이미지(WebAD로 명명)가 수집되어 instruction dataset을 풍부하게 한다.
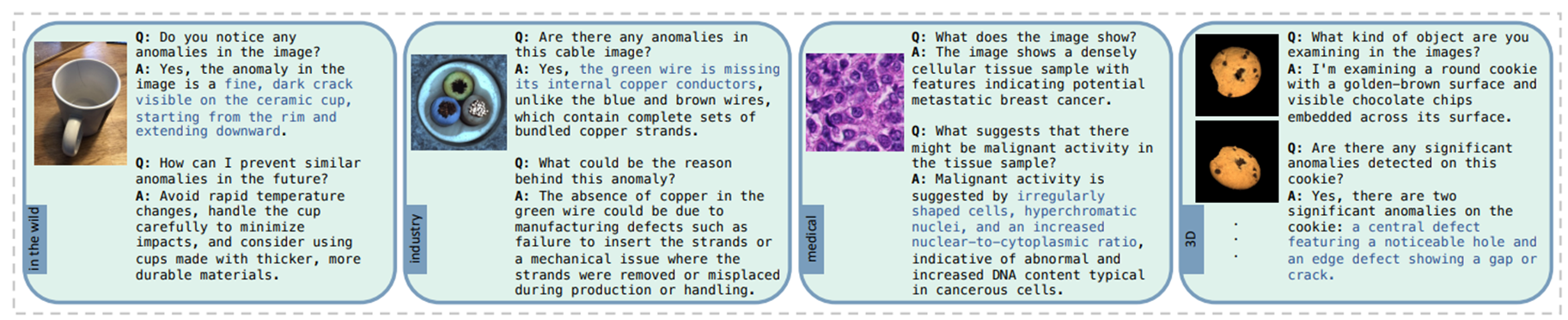
Instruction은 주로 multi-round 대화 형식으로, low-level 추론에서의 이상 탐지 및 설명과 복잡한 이해를 위한 potential cause 및 future suggestions를 다룬다.
4.2. Visa-D&R
기존 및 미래 방법의 이상 탐지 및 추론 성능 평가를 위해 VisA 데이터셋에서 10개의 클래스를 선택하고 Anomaly-Instruct-125k와 유사한 데이터 생성 파이프라인을 따라 벤치마크를 생성한다. 이 때 잘못된 설명은 Q&A 생성을 위해 활용하기 전에 사람이 직접 선택하여 re-annotation 하였다. 해당 벤치마크는 761개의 정상 샘플과 1000개의 이상 샘플로 구성된다.

탐지 성능을 평가하기 위해, one-word 답변을 유도하도록 설계된 질문이 MLLM에 사용되며, 결과는 accuracy, precision, recall, f1-score를 사용하여 정량화된다. 추론 성능은 시각적 결함 또는 이상에 대한 설명을 중심으로 하는 low-level 추론과 MLLM이 감지된 이상에 대한 잠재적 원인 및 미래 개선 전략을 제공해야 하는 complex reasoning 두 부분으로 나뉜다.
여기서 ROUGE-L, Sentence-BERT, GPT-Score는 생성된 텍스트와 GT 간의 유사성을 정량화하는 데 사용된다.
Low-level의 추론은 탐지 성능과 밀접하게 관련되어 있으며, low-level 추론의 이상 유형 설명은 복잡한 추론의 출력을 결정한다.
5. Experiment
5.1. Training & Evaluation
Training
- Anomaly-OV는 두 가지 독립적인 학습 단계를 거친다.
- Anomaly expert의 구성 요소가 학습되어 기존의 ZSAD를 목표로 token selection 기능을 얻는다. 이 때 Anomaly-Instruct-125k의 모든 데이터를 활용하며, 이전 연구와 유사하게 학습 데이터에 포함된 데이터 셋에서 모델을 평가할 때 해당 데이터 셋은 VisA로 대체된다.
- Anomaly expert와 visual encoder가 고정되고 projector와 LLM을 학습 가능하게 한다. Instruction 데이터셋 외에도 일반화 능력을 유지하기 위해 LLaVaOneVision의 학습 receipe에서 약 350k개의 데이터를 샘플링한다.
Evaluation
- 산업 검사 데이터 셋, 의료 진단 데이터 셋 총 9개의 벤치마크에서 평가
- image-level 이상 탐지 성능은 Area Under the Receiver Operating Characteristics (AUROC)로 평가
- Text-based 이상 탐지 성능은 accuracy, precision, recall, f1-score로 평가
- Anomaly reasoning 성능은 이상 데이터만 사용하고, 생성된 텍스트와 GT 간의 유사도를 ROUGE-L, Sentence-BERT, GPT-Score를 활용하여 정량화
- 이 때 시각적 결함/비정상을 설명하는 low-level 추론과, 잠재적 원인 및 향후 개선 전략을 제공해야 하는 complex 추론 두 부분으로 나뉨
5.2. Zero-Shot Anomaly Detection
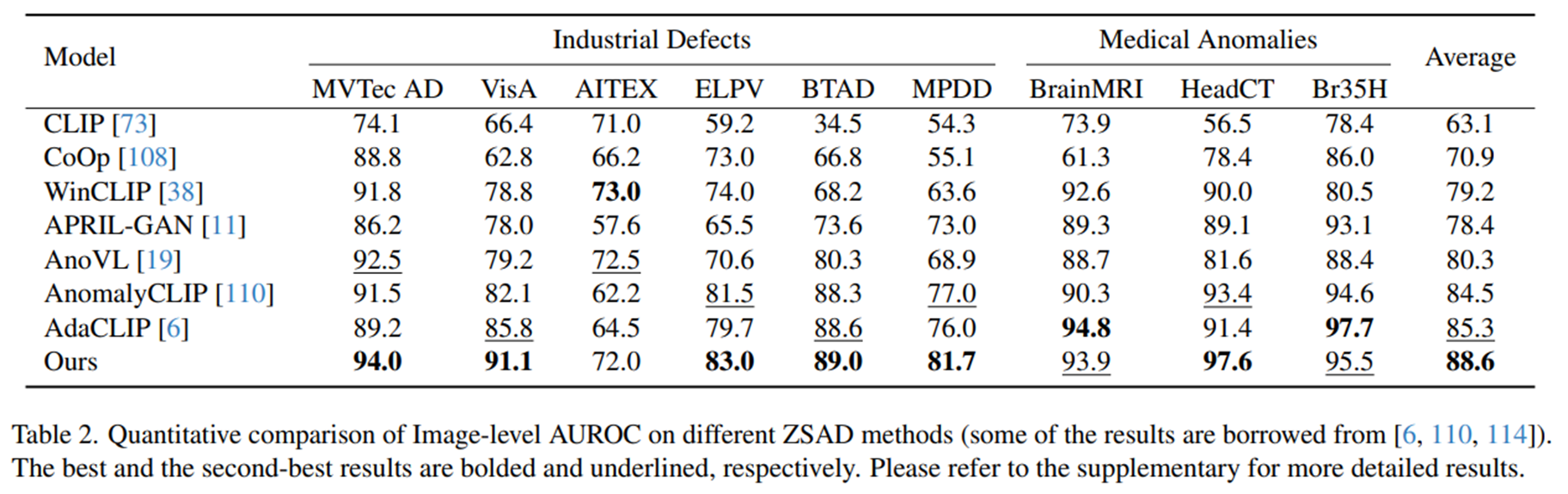
- Anomaly-OV의 anomaly expert는 기존의 ZSAD 방법론과 비교했을 때, 대부분의 벤치마크에서 image-level AUROC에서 상당한 개선을 보였다.
- 이는 기존 모델에서 널리 사용되던 텍스트 인코더가 이상 탐지 성능에 반드시 필요하진 않다는 점을 시사한다.

- Anomaly expert는 LLM이 의심스로운 visual token을 선택하도록 돕는 역할을 한다. 위 그림을 통해 시각화된 significance map은 이러한 해석 가능한 token selection 메커니즘을 잘 보여준다.
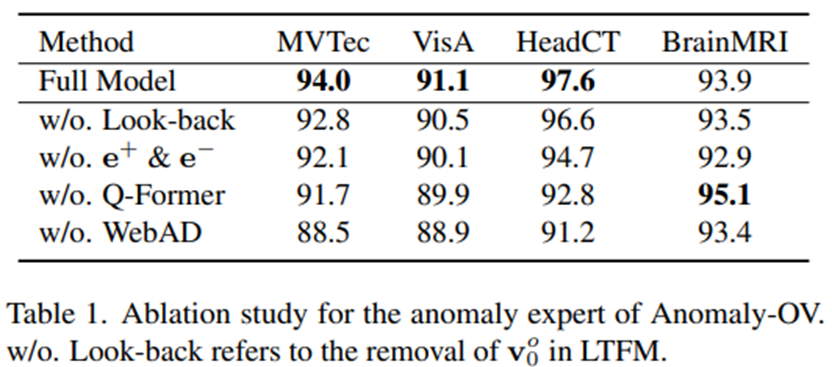
- Anomaly-OV의 성공적인 성능은 주로 WebAD라는 추가 데이터 셋 덕분으로, 이 데이터 셋을 통해 모델은 텍스트 인코더 없이도 정상/이상에 대한 더 일반적인 의미론을 학습할 수 있었다.
- Q-Former는 BrainMRI 벤치마크에서는 모델 성능을 다소 감소시켰지만, 대부분의 다른 벤치마크에서는 효과를 보여 visual token aggregation의 중요성을 나타낸다.
- Look-back 정보와 두 개의 learnable 임베딩 은 각각 class-awareness 이상을 설명하고 정상/이상 특징을 구별하는데 필수적임
5.3. Anomaly Detection & Reasoning
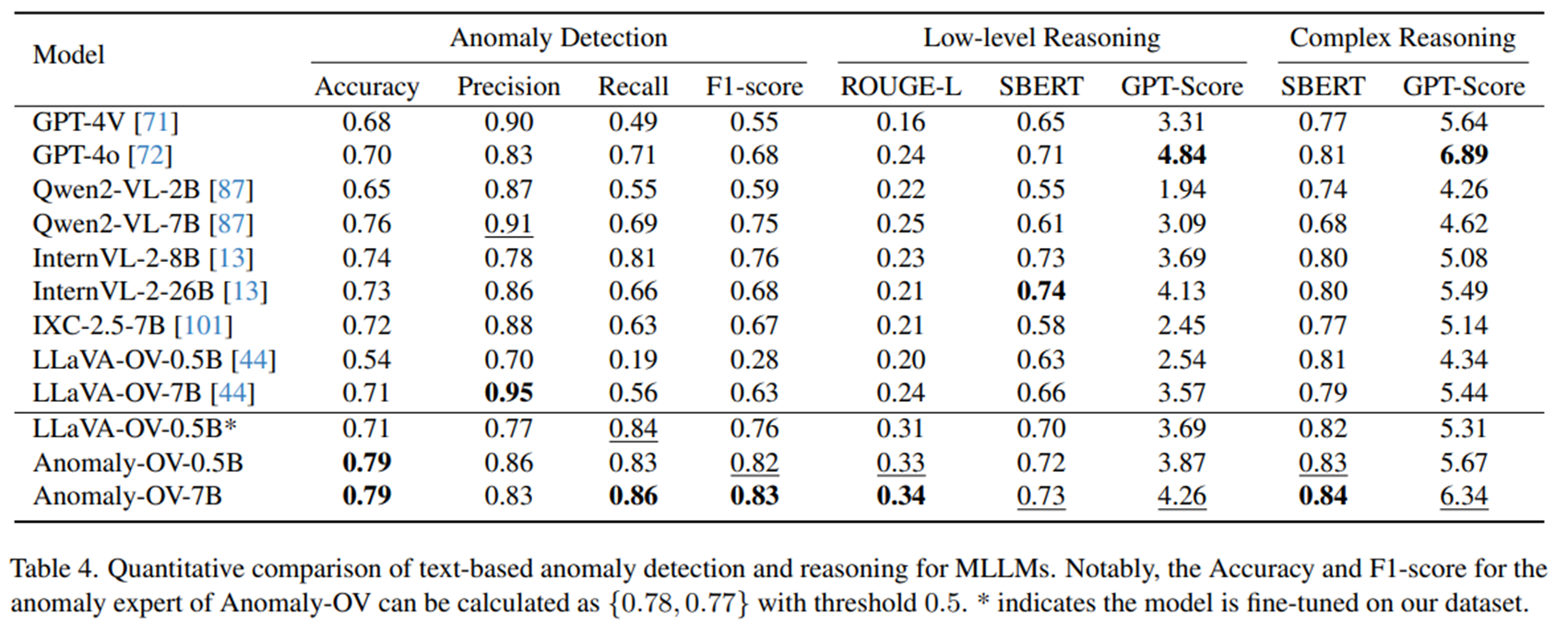
- Anomaly-OV는 anomaly expert의 강력한 zero-shot 탐지 및 의심 토큰 선택 능력으로 기존의 다른 MLLM에 비해 텍스트 기반 이상 탐지 및 추론에서 상당한 성능 향상을 달성
- 대부분의 기존 MLLM들은 precision에 비해 recall이 낮게 나타났는데, 이는 기존 모델들이 이상을 잘 놓치는 경향이 있다는 점을 보여줌
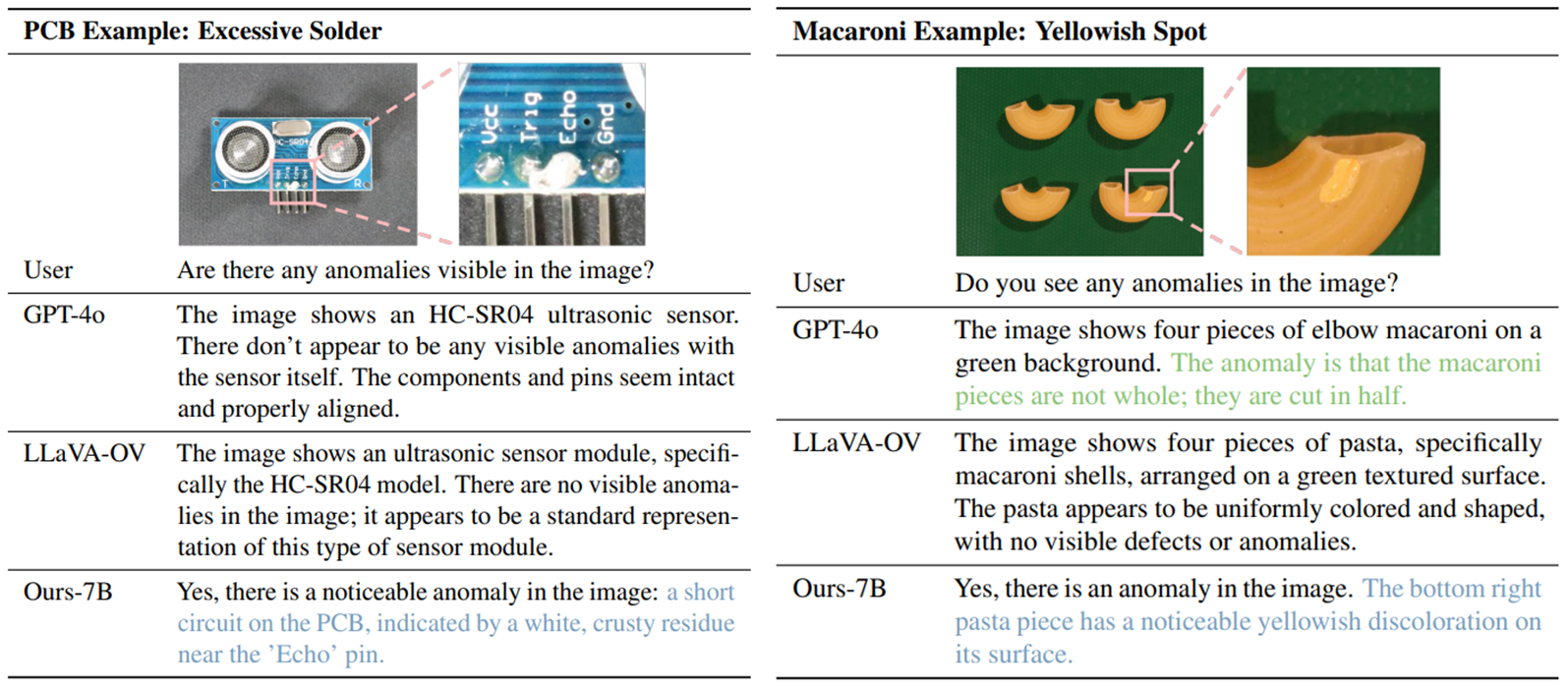
- GPT-4o와 LLaVA-OV 모두 이상 특징에 둔감하며 이미지 내 이상을 정확하게 감지하지 못하는 경우가 있었다.
- GPT-4o는 이미지가 이상하다는 것을 알면서도 이상을 정확하게 설명하지 못하는 경우가 있었음
5.4. Extension
해당 섹션에서는 Anomaly-OV 모델이 다양한 영역에서 시각적 이상 탐지 및 추론 작업을 수행할 수 있는 잠재력을 다룸
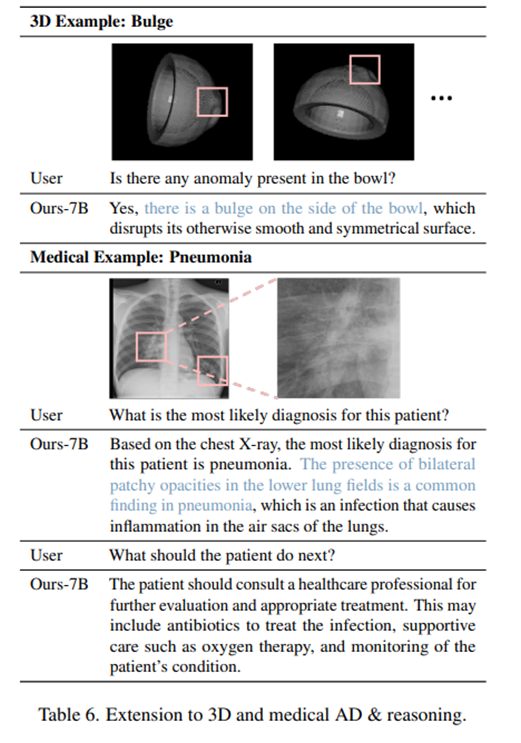
- MLLM의 일반화 및 다중 이미지 처리 능력을 활용하여 다양한 시각 검사 시나리오에 적용할 수 있는 통합 보조 장치를 구축할 수 있으며, 이는 단일 모델이 여러 유형의 이상 탐지 작업을 처리할 수 있음을 시사
- Anomaly-OV는 학습 시 Anomaly-ShapeNet 데이터셋을 사용하지 않았음에도 불구하고 3D 및 의료분야의 이상 탐지 및 추론에서 포괄적인 지식을 보여줌.
- 이는 위 표를 통해 입증 가능

好的内容 看得很开心