[논문 리뷰] One-for-all Few-shot Anomaly Detection Via Instance-Induced Prompt Learning (ICLR 2025)
논문리뷰
https://openreview.net/pdf?id=Zzs3JwknAY
Introduction
- Visual anomaly detection은 이미지에서 이상 징후를 탐지하는 것을 목표로 하며, 산업 손상 검사, 의료 진단 등과 같은 다양한 분야에서 널리 활용됨
- 과거 연구는 대부분 학습 중에 정상 샘플만 사용할 수 있다고 가정하고, 이를 사용하여 정상에서 벗어난 샘플을 포착할 수 있는 normality model을 학습시켜서 뛰어난 탐지 능력을 보여주었다. 하지만 이는 one-for-one, 즉 각 클래스에 대해 맞춤형 anomaly detection 모델을 학습해야 하므로 사용하기 번거롭고 학습 비용 또한 많이 듦
- 유연성을 높이고 학습 복잡성을 줄이기 위해 최근에는 one-for-all 패러다임을 따르는 연구가 많이 진행되었다. 이는 one-for-one 패러다임과 다르게 모든 클래스의 데이터에 대해 공통 모델을 학습시키기 때문에 사용 유연성과 학습 효율성을 크게 높일 수 있음
- 하지만 one-for-one과 one-for-all 방법은 모두 모델 학습을 위해 많은 양의 정상 인스턴스를 사용할 수 있다는 가정을 하고, 이는 일부 응용 시나리오에서 충족되기 힘들 수 있어, 아래와 같은 방법론들이 연구되었음
- RegAD, FastRecon과 같은 방법론들은 정상 인스턴스의 분포를 추정하거나 인스턴스 재구성을 위한 coreset을 구축하고자 하였지만, 학습 데이터의 부족으로 인해 full-shot에 비행 성능이 많이 떨어짐
- WinCLIP은 다양한 이상 현상의 일반적인 속성들을 설명하는 프롬프트 템플릿들을 수동으로 작성하고, CLIP을 사용하여 이미지 패치와 이상 프롬프트 간의 정렬을 평가하였으나, 다양한 크기의 수백 개 이미지 윈도우를 생성하고 이에 대한 특징을 추출하기에, 계산 비용이 많이 듦
- PromptAD는 V-V attention을 사용하여 CLIP의 출력 토큰에서 로컬 정보를 보존하고 데이터에서 프롬프트 집합을 자동으로 학습할 것을 제안하나, 이는 여전히 one-for-one 패러다임에 속함
→ 따라서 본 논문에서는 instance-induced prompt learning을 통해 vision-language model인 CLIP과 BLIPDiffusion의 zero/few-shot 인식 능력을 활용하여 최초의 one-for-all few-shot anomaly detection 방법인 Instance-Induced Prompt Anomaly Detection (IIPAD) 를 제안함
Related Work
Few-shot Anomaly Detection
Few-shot anomaly detection은 제한된 양의 정상 데이터만 학습에 사용할 수 있는 시나리오를 위해 설계되었음.
- TDG: 다양한 변환을 통해 support set의 이미지를 증강하고 계층적 생성 모델을 활용하여 multi-scale 패치 분포를 학습할 것을 제안함.
- RegAD: 이미지 증강대신, auxiliary dataset을 활용하여 target 데이터셋에서 anomaly detection을 위한 매칭 매커니즘을 제안함.
- DifferNet: Normalizing flow를 활용하여 pretrained model에서 추출한 descriptive features의 분포를 추정함.
- FastRecon: 특징을 정상으로 재구성하기 위해 projection matrix를 학습
- GraphCore: 데이터 증강을 통해 정상 특징 뱅크를 확대하고 GNN을 학습하여 이상을 식별
→ 위 방법들은 모두 one-for-one 패러다임을 따름
Leveraging VLMs for Zero-/Few-shot Anomaly Detection
CLIP은 zero-shot 및 few-shot 분류에서 뛰어난 성능을 입증한 모델이기 때문에, anomaly detection에서의 적용을 위해 널리 연구되고 있음
One-for-one paradigm
- WinCLIP: 수동 텍스트 프롬프트를 활용하여 사전에 정의된 window에서 이상을 탐지
- AnoVL: Adapter를 사용하여 텍스트 프롬프트를 V-V attention 기반 visual encoder를 통해 추출된 visual patch와 통합
- PromptAD: 텍스트 프롬프트를 수동으로 과하게 작성하는 과정을 없애기 위해서 semantic concatenation을 통해 정상/비정상 프롬프트를 학습할 것을 제안
One-for-all zero-shot paradigm
- AnomalyCLIP: 다른 도메인의 auxiliary dataset을 활용하여 카테고리 전반에 걸쳐 일반적인 정상/비정상을 캡처하는 object-agnostic text prompt를 학습
- AdaCLIP: Auxiliary dataset을 사용하여 hybrid 프롬프트를 학습
- InCTRL: Anomaly detection을 위한 일반적인 비정상을 캡처하는 residual learning을 수행하기 위해 몇 개의 정상 이미지를 프롬프트로 활용할 것을 제안
→ AnomalyCLIP과 AdaCLIP은 auxiliary dataset으로 pixel-level annotation이 있는 수천 개의 정상/비정상 이미지가 필요하고, InCTRL은 anomaly localization은 불가함
Methods
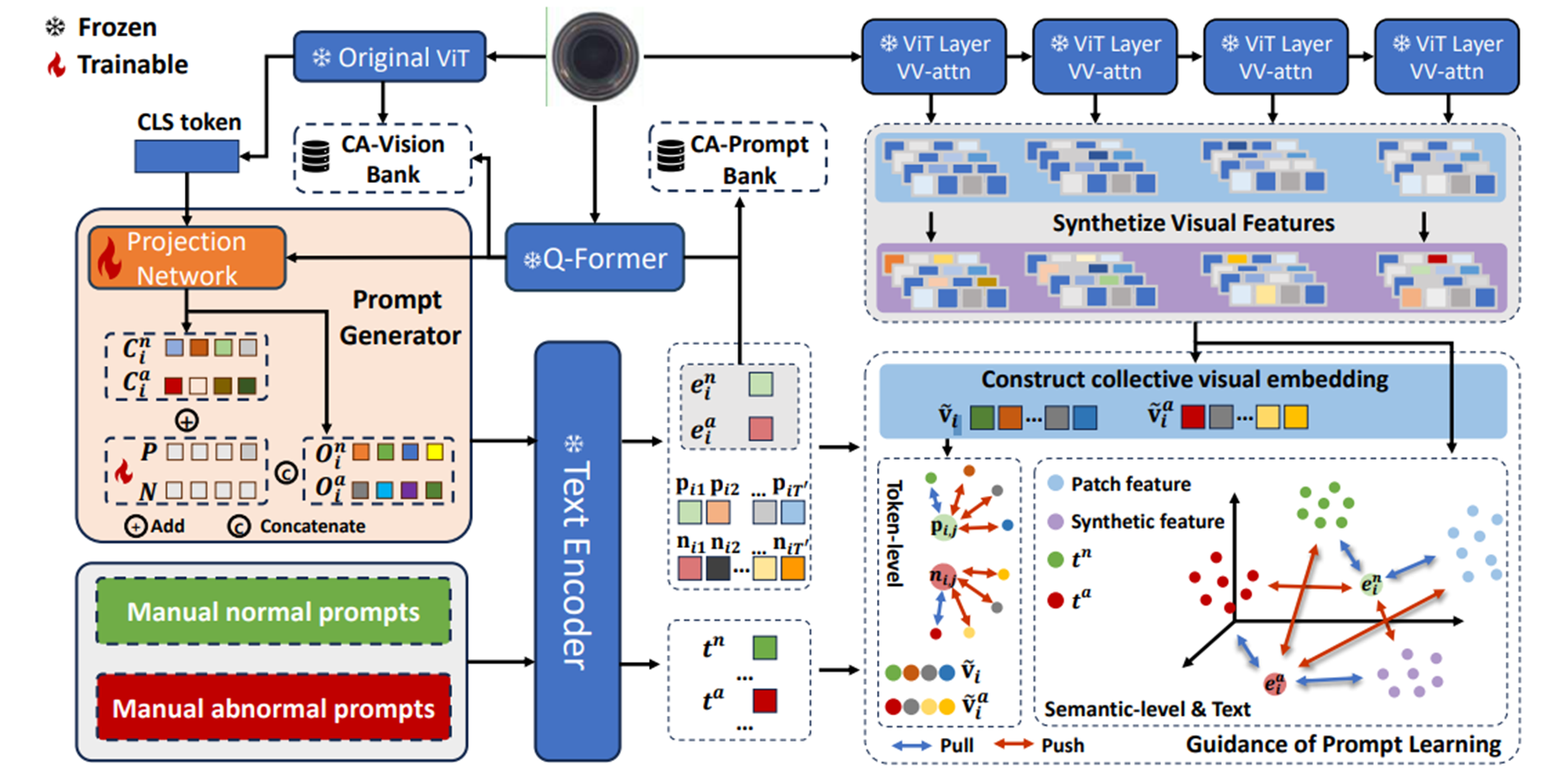
Few-shot anomaly detection에서, training dataset은 이고, 각각은 다중 클래스에서의 소수의 정상 이미지들로 구성된다. 각각의 클래스는 최대 (1~4)개의 정상 샘플로 구성된다. 본 논문에서의 목표는 이러한 소규모 데이터 셋 으로 다양한 카테고리에 존재하는 이상들을 detect & localization할 수 있도록 돕는 프롬프트 세트를 학습하는 것이다.
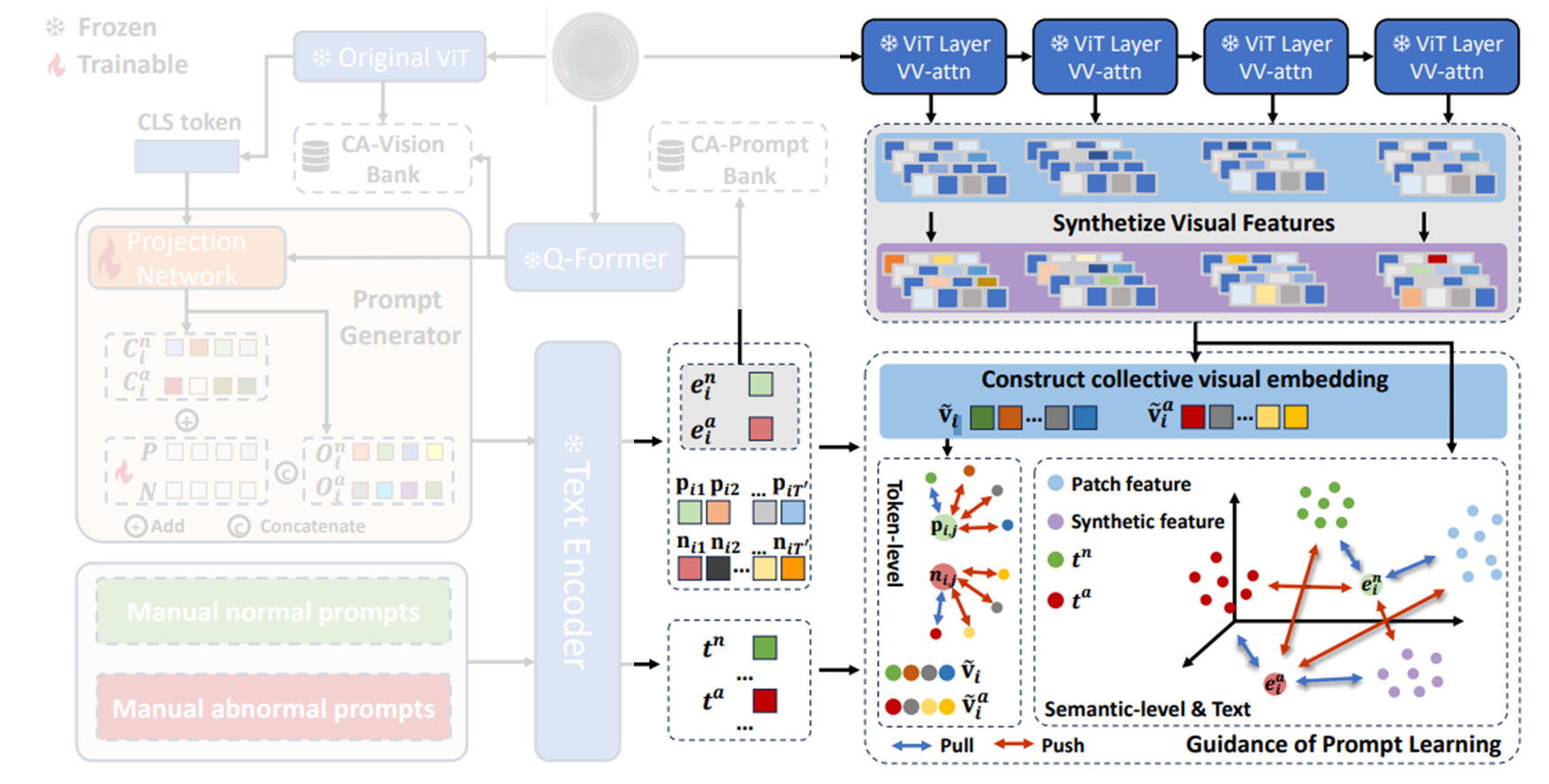
이를 위해 class-shared prompt generator를 개발하는데, 이는 모든 instance에 대해 specific한 프롬프트를 생성할 수 있다. 이 prompt generator는 프롬프트와 visual space 간 정렬을 유도하고 정상/비정상에 대한 일반적인 텍스트 설명의 guidance를 활용하여 학습된다.
추가로, test-time knowledge를 통합하여 이상을 탐지하기 위해 category-aware memory bank가 추가된다.
Instance-Specific Prompt Generator
프롬프트를 수동으로 만드는 것을 피하기 위해 CoOp에서 영감을 받은 AnomalyCLIP과 PromptAD는 각 데이터 카테고리에 대해 learnable vector set을 도입한 다음, 개별적으로 학습하는 것으로 설명될 수 있다. 이러한 프롬프트는 아래와 같은 형태를 갖고 있었다.
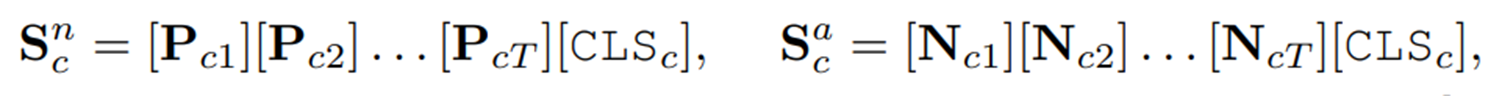
여기서 는 번째 클래스에 대한 정상, 이상 프롬프트를 나타낸다. 와 는 번째 토큰을 나타내며, 는 토큰의 총 개수이다. 는 번째 클래스 이름의 token을 나타낸다. 이러한 기존의 프롬프트 디자인은 one-for-one 패러다임에 빠지게 되고, 실제 사용 시 불편함을 초래한다.
이러한 방법을 one-for-all 패러다임에 적용하기 위해, 저자들은 우선 와 가 클래스 에 의존하지 않도록 하고자 아래와 같이 통일된 토큰 구조를 쓰도록 수정하였다.

이제 토큰 와 는 모든 인스턴스에 대해 공유되므로, 프롬프트의 유일한 차이점은 클래스 토큰인 에서 비롯된다. 하지만 클래스 이름은 각 인스턴스를 대략적으로만 설명할 수 있으므로, 이러한 프롬프트는 정상 인스턴스와 비정상 인스턴스 간의 미묘한 차이를 포착할 만큼 충분히 표현적이진 못하다.
이를 위해 저자들은 BLIP-Diffusion의 Q-Former로 이미지 에 대한 object token 를 추출할 것을 제안한다. Q-Former는 이미지 컨텐츠를 설명할 뿐 아니라 CLIP text encoder에 의해 해석될 수 있는 토큰 집합을 출력하기 위해 CLIP과 함께 학습되므로, 원본 이미지의 핵심 시각 정보를 담으면서 LLM이 이해하고 활용할 수 있는 형태라고 볼 수 있다.
그렇다고 해서 이러한 를 를 직접 대체하기엔 좋지 않은데, 이는 CLIP과 같은 Vision-Language Model (VLM)이 이미지의 정상과 비정상 간의 미묘한 차이를 포착하도록 학습되지 않았기 때문이다.
따라서, 먼저 두 개의 MLP인 를 통해 를 각각 과 로 변환하도록 하며, 이는 각각 정상과 이상을 설명하게 되고, 아래처럼 를 대체하도록 한다.
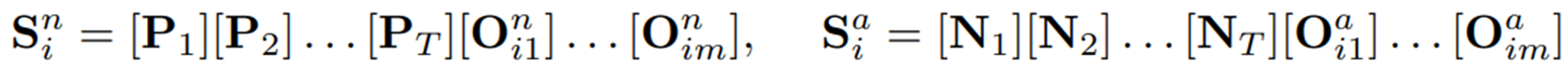
여기서 끝나는게 아니고(뭐가 굉장히 많다..), prefixs인 와 는 여전히 모든 인스턴스 간에 공유되기 때문에, 아직 해당 구조의 프롬프트는 다른 이미지 인스턴스 간 미묘한 정상성과 비정상성을 잘 포착하기엔 제한적이다. 따라서, CoCoOp의 방법에서 영감을 받아, instance-specific visual information을 각 와 에 주입해주기로 한다. 이는 각 이미지 인스턴스의 CLIP image encoder와 Q-Former의 출력을 projection network를 통해 추출되고, CoCoOp과 마찬가지로 각 와 토큰 벡터들에 더해지게 되어 최종 정상/이상 프롬프트인 와 를 얻게 된다.
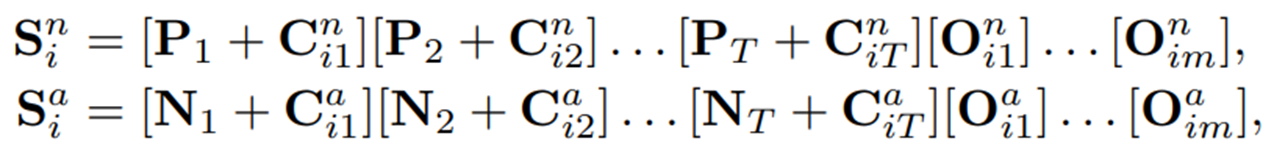
여기서 은 (번째 인스턴스에서 추출된, 정상을 보고자 하는 visual information)의 번째 토큰.
여기서 learnable prefix인 와 를 통해 정상성과 비정상성의 전반적인 설명을 포착하고, 와 는 각 이미지에 특화된 디테일한 정상/이상 정보를 포착한다. 이러한 프롬프트 디자인으로 이상을 포착하기 위한 instance-specific 프롬프트가 생성된다.
그래서 CLIP image encoder와 Q-Former의 출력을 갖고 를 어떤 식으로 추출하느냐?

와 를 추출하기 위해서는 우선, 해당 정상 인스턴스의 CLIP visual encoder로부터 추출되는 cls 토큰과 Q-Former로부터 추출되는 를 활용하게 되는데, 먼저 cls 토큰의 경우 MLP 를 거쳐서 textual token space로 projection 되어 의 첫번째 term 을 구성하게 되고,
cls 토큰을 query로 하고 를 normal, abnormal 각각의 linear projection을 거쳐 얻은 와 를 각각의 key, value로 사용하여 cross attention을 수행한 후, 를 거쳐 얻은 두 번째 term을 첫번째 term과 더해서 각 , 를 얻게 된다.
이렇게 얻은 는 cls token으로부터 global visual information과, category tokens로부터 얻은 fine-grained details를 포착하고 있다.
그렇게 얻은 최종 정상/이상 프롬프트인 와 을 text encoder 를 거쳐서 아래와 같은 프롬프트 임베딩을 얻게 된다.

여기서 , 즉 정상/이상 토큰에 정상/이상 카테고리 토큰이 concat된 길이이며, 와 는 각 정상/이상 프롬프트 시퀀스 전체의 의미를 대표하는 단일 벡터 임베딩이다. 각 임베딩들이 어떻게 사용되는지는 이후 섹션에서 더 자세히 살펴보자.
Multi-modal Prompt Training
Prompt generator가 해당 입력 이미지에 맞춘 정상/이상 프롬프트를 생성할 수 있도록 하기 위해, 저자들은 visual, textual 모달리티 모두에서 프롬프트를 학습을 돕고자 한다.
Visual Guidance
Unsupervised setting에서 소수의 정상 샘플만 접근 가능하기 때문에, contrastive learning을 통해 정상 prompt embedding은 정상 visual features와 가깝게 하면서, 이상 prompt embedding과는 멀도록 한다. 해당 접근 방식은 이상을 탐지하기 위한 CLIP-based 방법의 목표와 일치한다.
학습 시 multi-level의 semantic information과, computational cost 간의 trade-off를 고려하여, CLIP visual encoder의 특정 중간 layer의 출력들을 선택하고(로 표기), 해당 feature들을 활용하여 를 구성하며(여기서 는 feature map 사이즈. 만약 input image가 336 336이고, encoder를 ViT-L-16을 썼다면 는 모두 336 14 = 24), 는 의 번째 출력을 의미한다. 이 때 내부 normal feature를 추출할 때 사용되는 encoder의 transformer block에서 V-V attention으로 대체함으로써 local 정보를 보존하도록 하였다. 좀 더 자세히 알아보자.
Semantic-Level Alignment
각 학습 이미지 에 대해, 해당 normal prompt embedding 은 (visual encoder의 중간 layer의 출력들)의 normal patch feature들에 가깝게 당겨지고, anomalous prompt embedding 는 이들로부터 멀어지도록 한다. 해당 부분의 semantic-level alignment loss는 아래와 같이 정의된다.
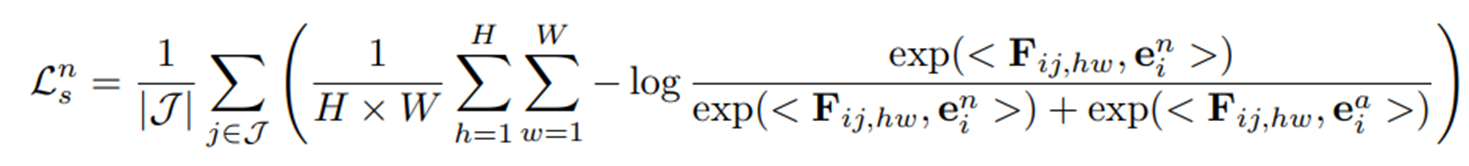
여기서 는 cosine similarity를 나타내고, 는 번째 이미지에서 번째 layer 출력으로 나온 feature map의 번째 patch의 feature를 의미한다.
Token-Level Alignment
전체 프롬프트의 embedding을 patch feature에만 정렬하는 것은 prompt가 세부 사항을 포착하는 능력을 약화시킬 수 있다. 저자들은 여러 이미지 패치가 때론 캡션의 단일 단어에 해당하는 경우가 많다는 연구에 영향을 받아서 패치 그룹과 하나의 프롬프트 토큰의 임베딩 간 정렬을 수행한다. 이 접근 방식은 프롬프트가 CLIP의 V-V attention에서 제공받는 상세하고 관련성이 큰 local 정보를 잘 포착하도록 한다.
먼저 이미지 에 대한 CLIP visual encoder의 번째 layer에서 나온 normal prompt token embedding과 patch embedding 간의 유사도 행렬 을 계산한다. 여기서 이고, 이다. 의 각 element 는 prompt token embedding 와 patch feature 간의 유사도를 나타내며, token-level alignment weight를 얻기위해 각 element 값을 min-max normalization을 통해 [0, 1]범위로 정규화한다.
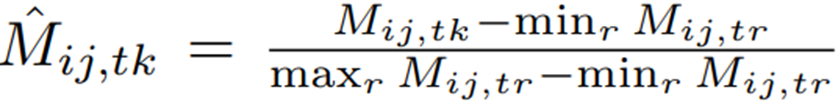
이후, 관련없는 패치를 줄이고 각 prompt token embedding이 여러 patch feature와 정렬되도록 하기 위해, 정규화된 행렬 를 희소화(sparsify) 하는데, 이는 sparsify threshold 를 넘기면 0으로 변환함으로써 수행된다.
이렇게 얻은 token-level alignment weight는 최종적으로 로 얻어지게 된다. 이후 를 사용하여 prompt token과 가장 관련성이 높은 patch feature를 로 얻어지게 된다. 즉, 는 번째 프롬프트 토큰과 관련된 collective visual patcvh의 embedding으로 이해될 수 있고,
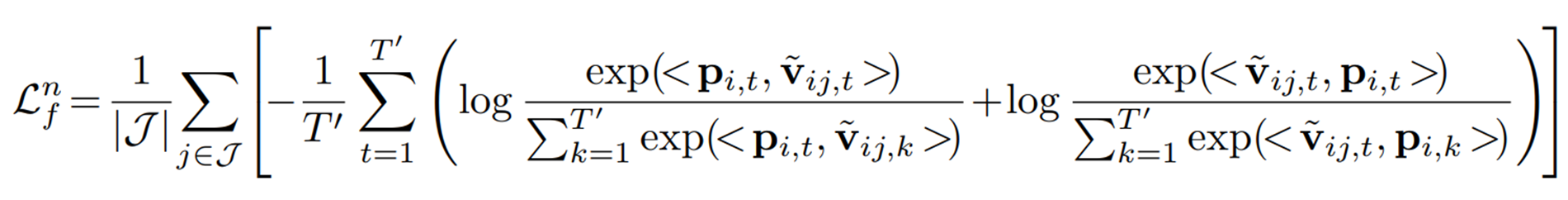
위 loss를 최소화하여 prompt token embedding 와 collective visual embedding 를 더 가깝게 당기도록 학습된다.
Synthetic Visual Guidance for Anomalous Prompt
학습 때 이상 샘플이 없기 때문에, anomalous prompt embedding을 normal patch feature에서 멀리 밀어냄으로써만 이상에 대한 프롬프트 학습이 가능하다. 하지만 실제로 이상 이미지는 정상 이미지와 유사하기 때문에, anomalous prompt를 맹목적으로 밀어내기만 하는 것은 prompt가 의미있는 semantic 정보를 잃게할 수도 있다.
이에 SimpleNet의 방식에 따라, normal feature에 noise를 추가할 것을 제안한다. 이 때 gaussian noise는 너무 약하고 anomalous prompt를 안내하는 데 의미있는 정보를 제공하지 않기 때문에, 번째 layer의 feature인 를 번째 layer의 feature로 왜곡할 것을 제안한다. (은 의 바로 이전 layer로 설정)
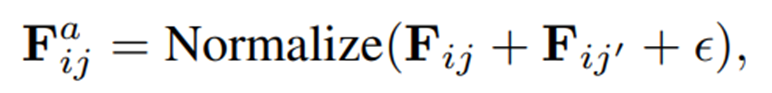
위와 같이 를 로 대체하여 이상 feature를 합성하는데, 는 norm을 1로 정규화하는 연산이고, ~ 은 gaussian noise를 나타낸다. 서로 다른 layer의 feature를 더해줌으로써 서로 다른 scale의 정보를 융합할 수 있으며, 그 결과 low-level visual detail과 high-level semantic concept을 모두 포함하는 synthetic visual feature 를 생성하여 일부 불일치나 부자연스러움을 표현한다.
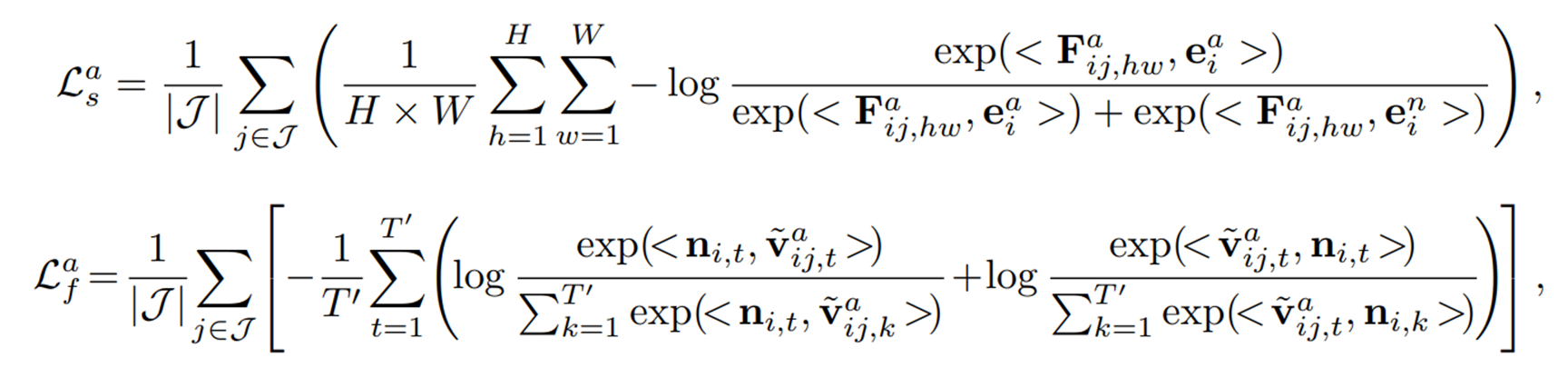
이제 마찬가지로 이를 활용해서 이상에 대한 semantic-level, token-level alignment를 수행해줄 수 있다. 여기서 는 번째 anomalous prompt token embedding을 의미하며, 는 에 일치하는 grouping patch features이다.
Textual Guidance
위의 visual guidance에서 비정상 시각 데이터는 합성 데이터를 사용하였기 때문에, prompt 학습 과정에서 편향이 발생할 수 있다. 이를 해결하기 위해 수동으로 제작된 prompt를 추가로 활용한다. 이 때 one-for-all 패러다임을 따르기 위해 특정 카테고리 이름을 “object” 등 일반적인 단어로 대체한다.
일반적인 정상 상태를 설명하는 템플릿 을 (e.g., “A photo of a perfect object”) 제작하고, 비정상적인 상태를 설명하는 템플릿 는 PromptAD에서 수행한 것처럼 데이터 세트의 anomaly label에서 생성한다(e.g., “A photo of the object with color stain”).
이렇게 생성된 프롬프트들은 특정성이 부족하고 다양한 카테고리에 대한 적응성은 부족하기에, 이상 탐지에 직접적으로 활용하기에보단, prompt 학습을 안내하는 데 사용한다.
프롬프트의 visual guidance와 일관되게, contrastive learning을 통해 아래 를 최소화하여 learnable 프롬프트를 수동 프롬프트와 정렬하도록 한다.
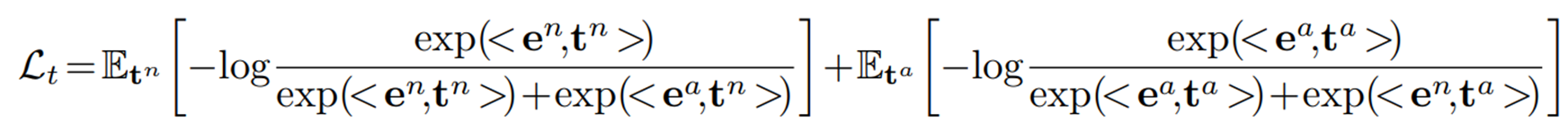
여기서 와 는 각각 정상 수동 프롬프트와 비정상 수동 프롬프트의 임베딩을 나타낸다. 이렇게 수동 prompt의 guidance를 통해 학습되는 프롬프트는 전문가 지식을 사용하여 일반적인 정상 상태와 실제 비정상 상태를 식별하는 능력을 갖게 된다.
이렇게 프롬프트 학습의 전체 loss는 visual guidance와 textual guidance의 가중합으로 이루어진다.
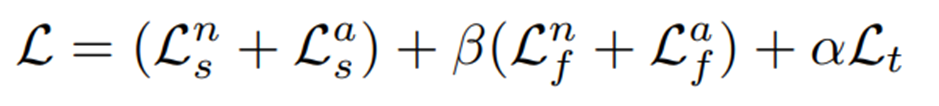
Intro에서 수동 프롬프트 제작을 피하고자 했다고 하는데, 결국은 수동 프롬프트도 학습에 쓰인다.
Category-Aware Memory Bank
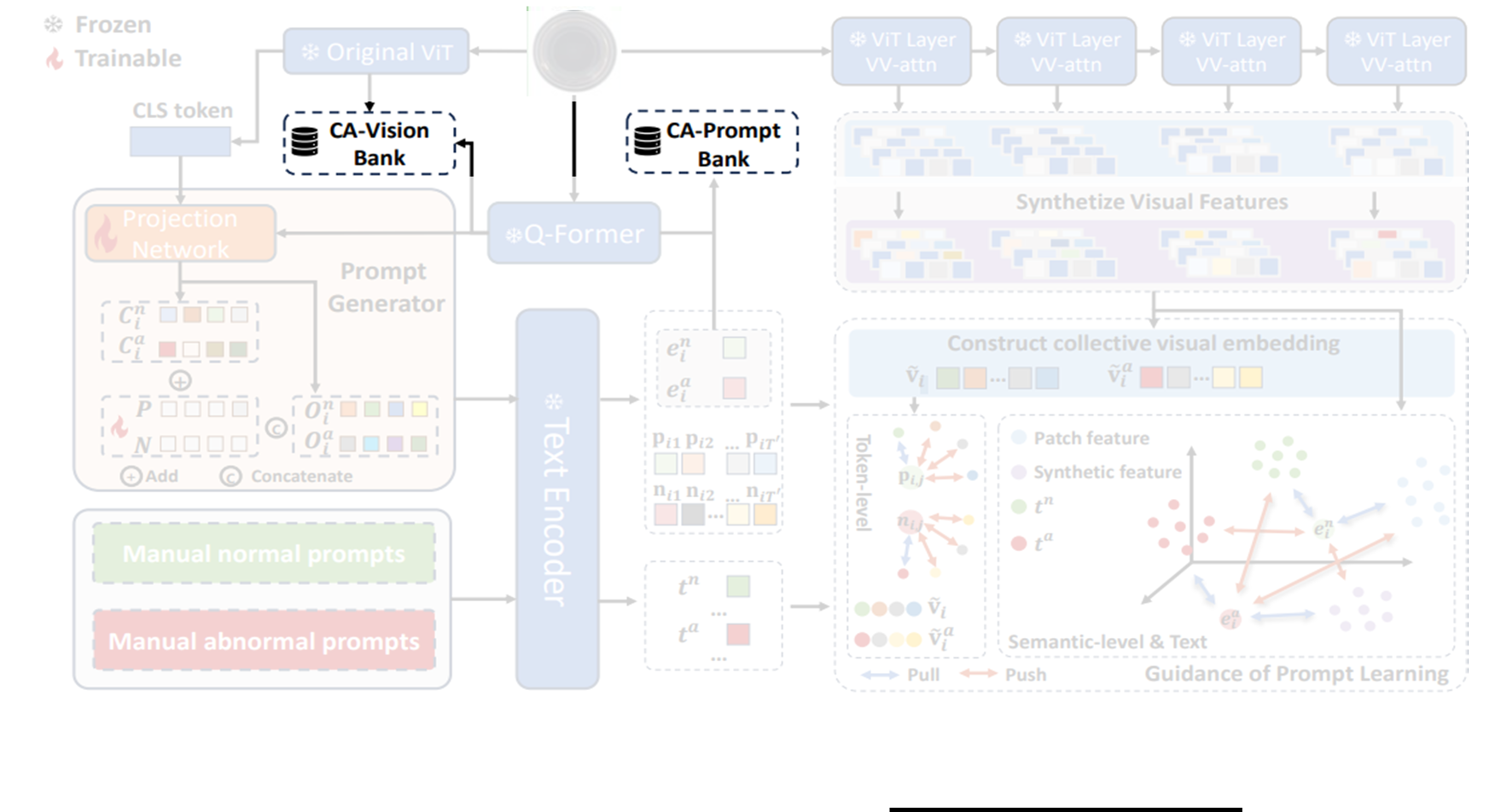
Category-Aware Vision Bank
One-for-all 패러다임에서는 memory bank를 사용할 때 서로 다른 클래스의 visual features가 포함되는데, 만약 특정 클래스의 비정상 패치의 특징이 완전히 다른 클래스의 정상 특징과 유사한다면, 이는 mismatch 문제를 발생시킬 수 있다.
이를 극복하기 위해 저자들은 category-aware memory bank를 제안하는데, 이는 CLIP의 visual encoder의 번째 layer에서 출력된 이미지 패치 토큰 을 그대로 저장하는 대신, Q-Former에서 추출한 카테고리 토큰 를 추가로 활용하는데, 이는 번째 이미지의 와 를 쌍으로 묶어서 저장을 하는 것이다.
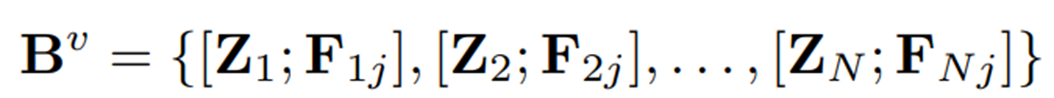
테스트 단계에서는 먼저 테스트 이미지의 카테고리 토큰 와 저장된 토큰 간의 유사도를 통해 에서 요소 그룹을 retrieval하고, 테스트 이미지의 패치 토큰 특징 와 이전 단계에서 검색된 와의 유사성을 평가한다. 이렇게 메모리뱅크에 저장되는 번째 학습 이미지의 는 중간의 두 가지 layer에서만 추출되어 각각 , 로 저장된다.
Category-Aware Prompt Embedding Bank
Prompt에 대한 embedding bank인 도 구축을 하는데, 이는 의 training instances의 prompt embedding들을 저장한다.
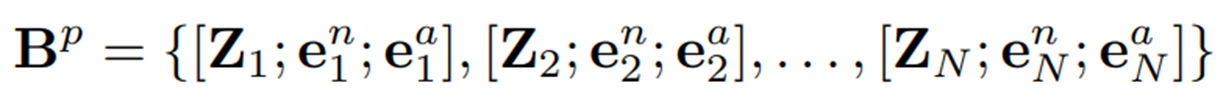
테스트 중에는 해당 vision bank에서 사용된 것과 유사하게 테스트 이미지와 가장 유사한 top K개의 프롬프트를 검색한다.
Anomaly Detection
학습된 고정 프롬프트를 사용하는 이전 연구들과는 달리, 본 연구에서는 prompt generator를 통해 테스트 이미지로부터 추가적인 정보를 활용할 수 있다.
에서 검색된 prompt embedding 그룹인 와 와, 테스트 이미지에서 얻은 prompt embeddings인 와 를 통해 이상 탐지에 쓰이는 prompt embeddings는 아래와 같이 구해진다.
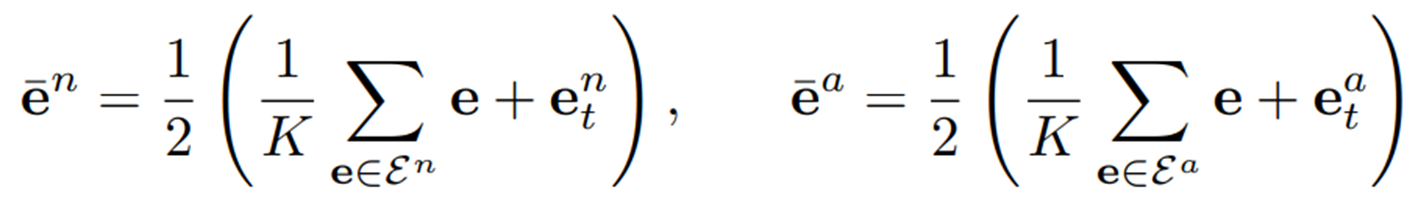
각각은 테스트 이미지의 정상/이상 fusion prompt embeddings가 된다.
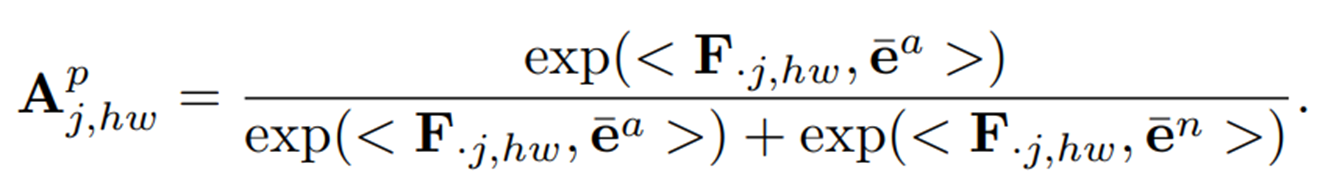
이후 테스트 이미지의 번째 layer의 패치 토큰인 (·는 테스트 이미지를 의미)가 융합된 이상 prompt embedding인 과 얼마나 다른 지를 통해 prompt-guided anomaly map 을 구한다. 이 때 모든 layers에 대해 구하고 평균을 취한 를 구한다.
이후 test 이미지의 와, 에서 검색된 가장 유사한 패치 토큰 그룹 를 비교하여 아래와 같이 visual anomaly map 를 얻는다.
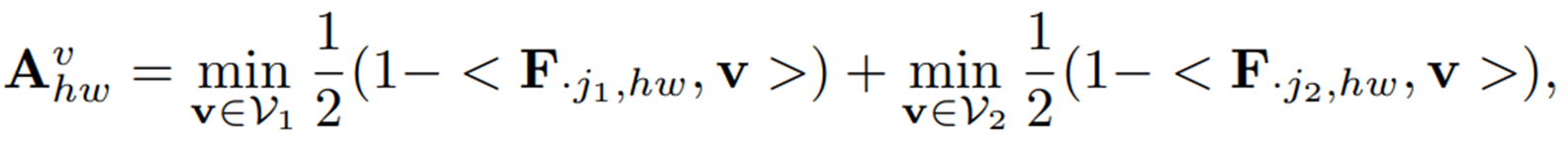
최종 pixel-level anomaly score map과 image-level score는 다음과 같이 구해진다.
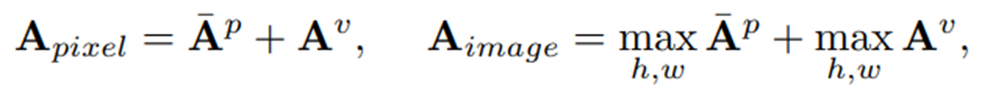
Experiments
Experiment Setting and Baseline
Dataset
Anomaly Detection task에서 가장 많이 사용되는 두 가지 벤치마크 데이터셋인 MVTec-AD, VisA를 사용
Experimental Setup
학습 데이터셋이 벤치마크의 모든 카테고리를 포함하고, 각 클래스에 대해 K-shot normal image만 포함하는 설정에서 비교 실험을 수행함.
Evaluation
Image-level 성능은 Area Under the Receiver Operating Characteristic Curve (AUROC), Area Under Precision Recall (AUPR)를 사용, pixel-level 성능은 마찬가지로 AUROC와 Per-Region Overlap (PRO) 사용
Implementation Details
CLIP은 ViT-L/14 모델을 사용, Q-Former는 BLIP-Diffusion의 것을 사용, learnable prompt token 길이는 24로 설정.
Baselines
SPADE, PatchCore, FastRecon, WinCLIP, PromptAD, UniAD, OmniAL, HVQ-Trans, DiAD 등 다양한 베이스라인 모델로 비교 실험 수행
Experimental Results
Overall Performance
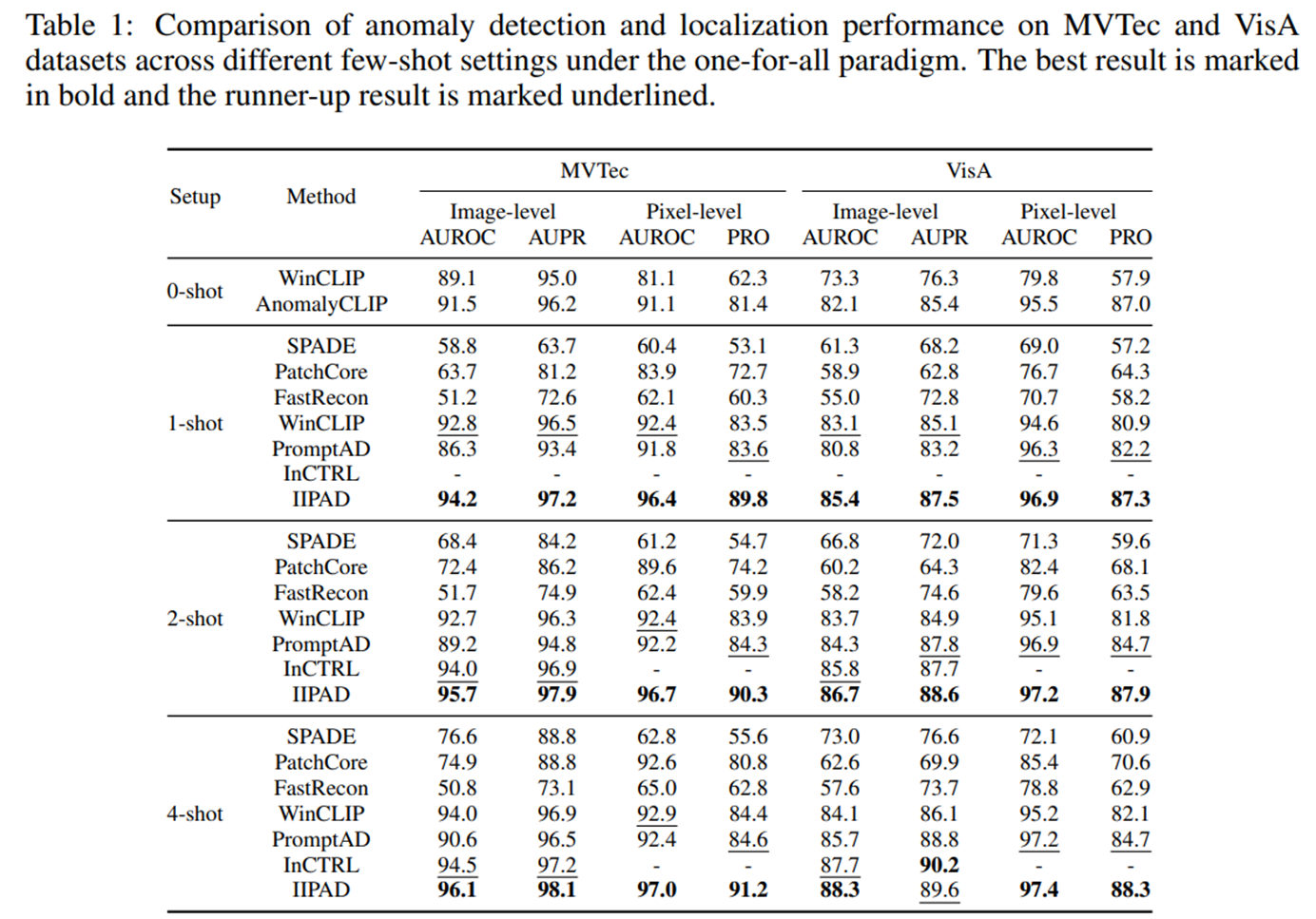
- 모든 few-shot 설정에서 baseline인 one-for-all few-shot 베이스라인들보다 좋은 성능을 보여주었음 (SPADE, PatchCore 등은 기존에는 one-for-one full-shot 설정)
- WinCLIP이나 AnomalyCLIP 등과 같이 zero-shot 방식은 target domain의 정보 활용 없이 auxiliary dataset과 수동 프롬프트에 의존하기 때문에, few-shot 방식에 비해 낮은 성능을 보이는데, 이는 target domain data가 학습에 활용되는 것의 중요성을 시사함
Comparison with One-For-One Few-Shot Methods
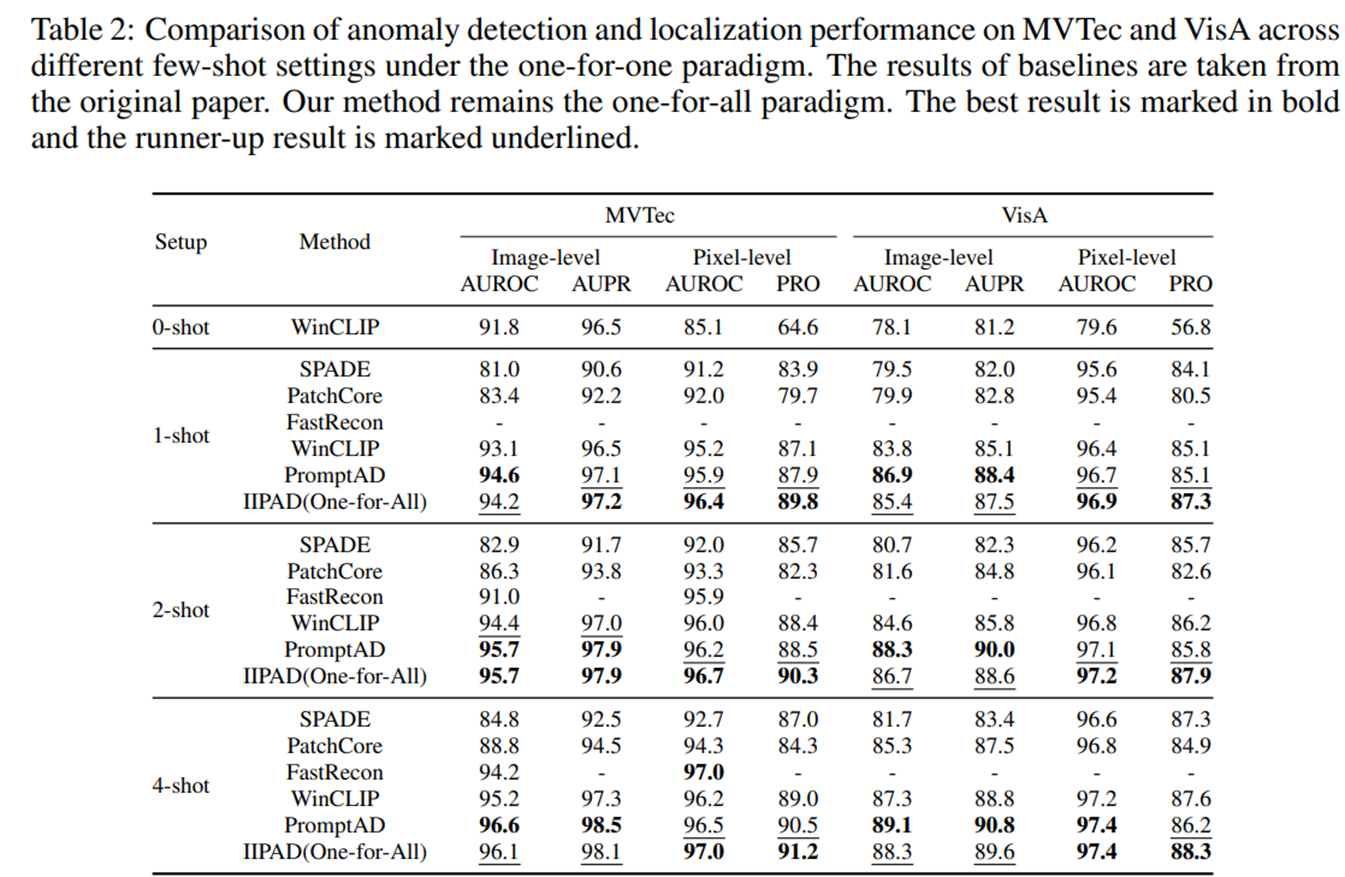
- IIPAD는 One-for-All 모델임에도 불구하고, 각 클래스별로 별도의 모델을 학습하는 one-for-one 패러다임의 SOTA few-shot 방법들과 비교했을 때 유사하거나, 더 나은 성능을 보였음
- 이는 IIPAD가 단일 모델로 여러 카테고리를 처리하면서도, 클래스별 맞춤 모델에 필적하거나 그 이상의 정밀한 이상 탐지 능력을 보여준다는 점에서 주목할 만 함
Comparison with One-for-All Full-Shot Methods
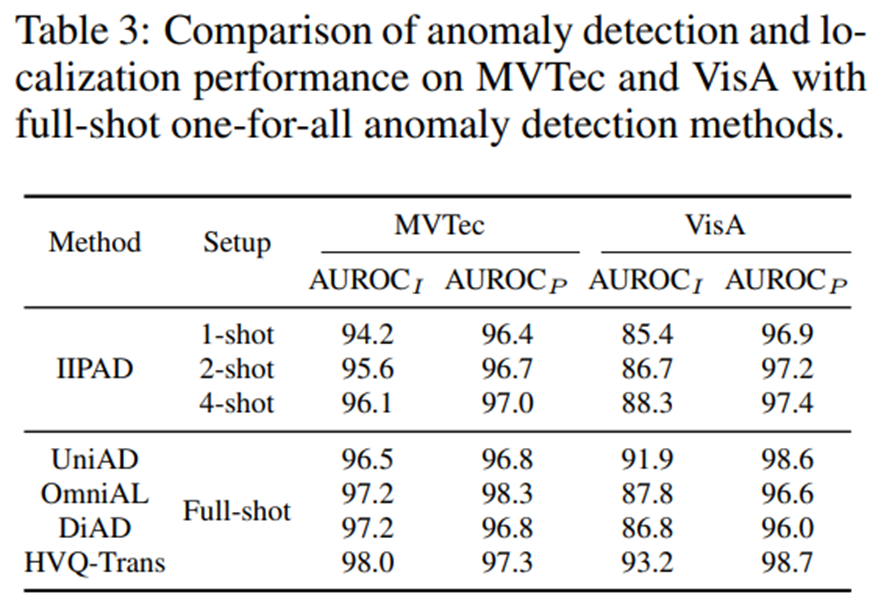
- IIPAD는 단 몇 장의 정상 이미지만을 사용하여 학습했음에도 불구하고, 많은 양의 정상 이미지를 활용하는 full-shot one-for-all 이상 탐지 방법들과 유사한 성능을 보임
- 이는 IIPAD가 제한된 데이터로부터도 매우 효율적으로 정보를 활용하여 SOTA full-shot 모델에 근접하는 일반화 성능을 이끌어냈음을 보여줌
Visualization Results

Ablation Study
Prompt Generator Ablation
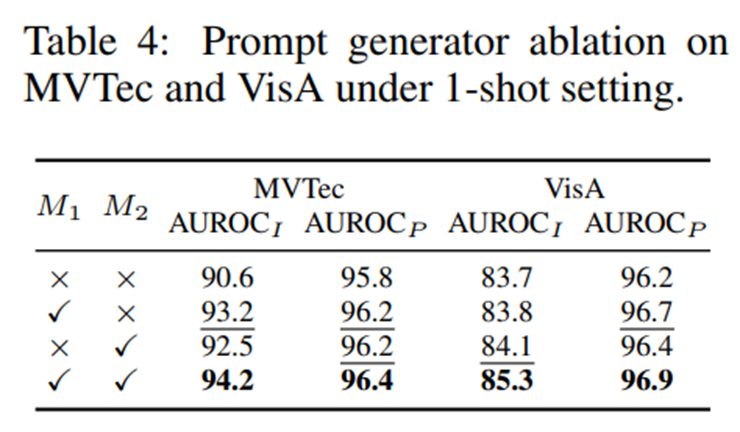
- 인스턴스 별 시각 토큰 ()와 객체 토큰 () 모두 prompt generator의 성능에 영향을 미치며, 둘 다 쓰는 것이 최상의 결과를 보여주었음.
Loss Ablation
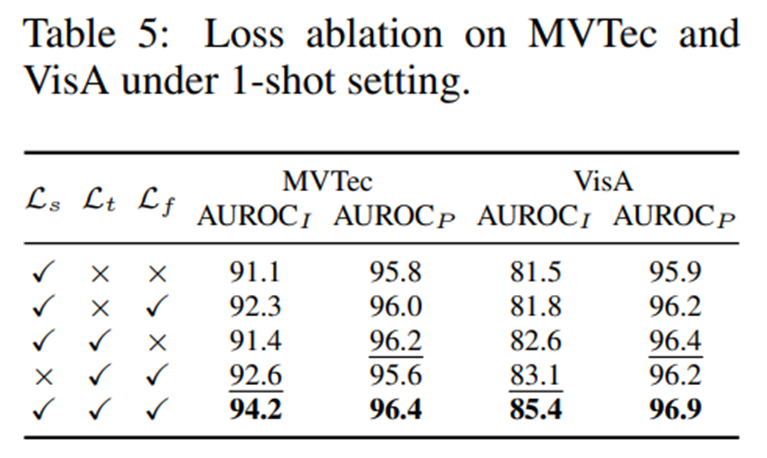
- 프롬프트 학습의 핵심이었던 Semantic-level alignement loss 를 제거했을 때 가장 큰 성능 하락이 발생
- Token-level alignment loss 는 localization 성능에 기여하였음 (사실 큰 기여를 하는진 잘 모르겠다)
- Textual guidance 는 image level의 성능에 크게 기여함
Category-Aware Memory Bank
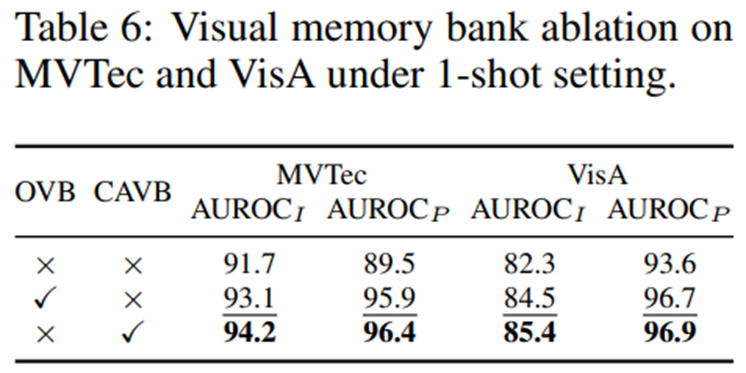
- Category-aware visual memory bank를 사용함으로써 이상 탐지 성능에 결정적인 성능 향상을 가져옴
- 일반적인 visual bank에 비해 우수한 성능을 보여주는 것으로 보아, mismatch problem을 해결하는데 효과적이었음
그 외에도 synthetic visual features, projection network, cross attention 등등에 관한 ablation을 진행했는데, 결과는 논문의 appendix 참고.
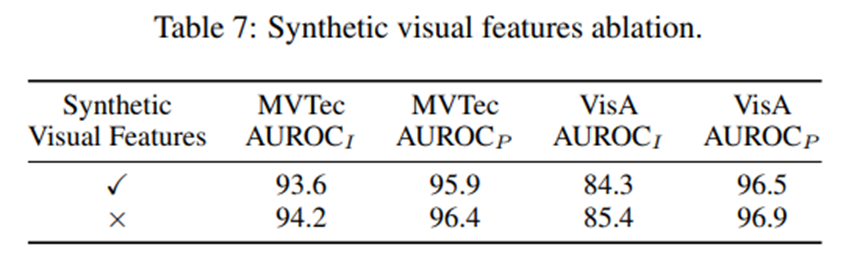
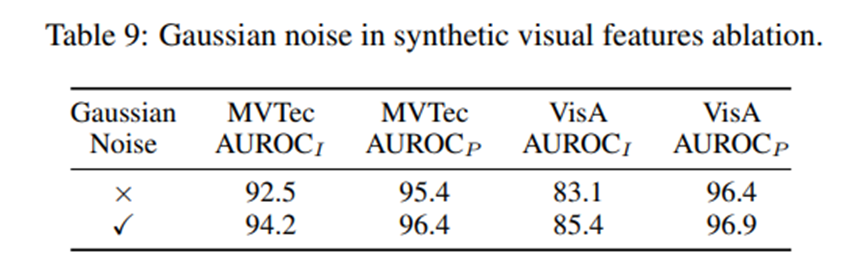
다만 한가지 이상했던 부분은, synthetic visual features ablation의 결과인 Table 7에서는 synthetic visual features를 사용하지 않았을 때 성능이 사용했을 때보다 일관적으로 좋게 나와서 뭐지? 싶었는데, Table 9에서 Gaussian Noise를 사용했을 때의 성능과 같은 값인 것을 보니, Table 7의 체크박스가 반대로 들어간 것 같다.
Review
진짜 프롬프트 디자인부터 해서 이것저것 온갖 것 다 들어가는 느낌인데, 살을 하나하나 붙여가는 식으로 실험 다 해서 성능 최대한 끌어 올려본 것 같다. Novel하거나 수학적인 아이디어가 들어가진 않아도 이정도 정성 들여야 ICLR 가는건가 싶다.. 본 논문을 기점으로 앞으로 unified VAD (one-for-all) 방법론들은 few-shot이 가능해야 경쟁력을 가질 수 있을 것 같고, 앞으로의 visual anomaly detection에서의 패러다임은 one-for-all (few-shot), one-for-all (zero-shot), one-for-more (continual) 분기로 크게 나뉘어서 연구가 진행되지 않을까 싶다. 세 가지 모두 한 끗 차이인 느낌이지만, 확실한 차이가 있다.
현재까지의 zero-shot 연구는 본 논문의 few-shot 설정과는 다르게 정상/이상 이미지가 모두 포함된 auxiliary dataset으로 한 번 학습한 후 target dataset에서 추가 학습 없이 성능 평가가 이루어지지만, 본 논문의 few-shot 설정에서는 auxiliary dataset 없이 바로 target dataset의 소수 데이터의 학습만으로 성능 평가가 이루어진다는 차이가 있다. One-for-more 패러다임의 경우엔 기존의 one-for-all(full shot 포함) 상황에서 이전 클래스 혹은 task의 학습 데이터에 접근이 불가하다는 가정이 추가된다.
