MultiThreading / MultiProcessing
Multi-Threading / Multi-Processing
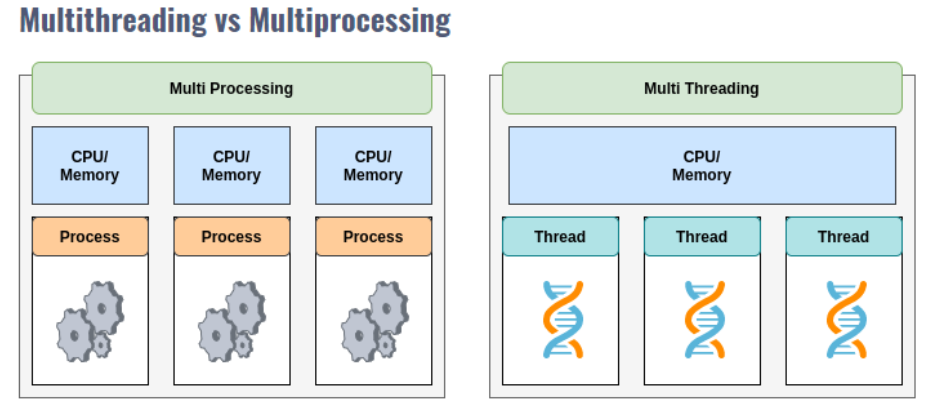
오늘의 주제는 멀티스레딩과 멀티프로세싱이다. 그간 프로젝트를 진행하면서 아름아름 알아가고 사용해보았지만, 다시 한번 진득하게 공부해보고 싶어 주제로 선택하게 되었다.
1. 개요 및 개념
1.1 멀티스레딩과 멀티프로세싱의 정의
멀티스레딩
멀티스레딩(Multithreading) 은 하나의 프로세스 내부에서 여러 스레드를 생성해 동시에 실행하는 방식으로, 프로세스의 메모리 공간을 공유하면서 작업을 병렬로 처리할 수 있다.
- 스레드는 "경량 프로세스" 로 불리며, 프로세스 내에서 실행되는 작업 단위이다.
- 멀티스레딩은 주로 I/O 바운드 작업(예: 파일 읽기/쓰기, 네트워크 요청)에서 성능을 극대화하는 데 효과적이다.
멀티스레딩
멀티프로세싱(Multiprocessing) 은 여러 프로세스를 생성해 독립적으로 실행하는 방식으로, 각 프로세스는 별도의 메모리 공간을 사용한다.
- 프로세스는 운영체제에서 관리하는 독립적인 실행 단위로, CPU를 효율적으로 활용할 수 있다.
- 멀티프로세싱은 CPU 바운드 작업(예: 복잡한 수학 연산, 데이터 분석)에 적합하다.
Python에서의 구현
- 멀티스레딩: Python의
threading모듈을 사용하여 구현 - 멀티프로세싱: Python의
multiprocessing모듈을 사용하여 구현
1.2 스레드와 프로세스의 차이점
스레드와 프로세스는 모두 병렬 처리를 수행하기 위한 실행 단위이지만, 메모리 사용 방식과 독립성에서 큰 차이가 있다.
| 특징 | 스레드 | 프로세스 |
|---|---|---|
| 독립성 | 동일한 프로세스 내부에서 실행, 메모리 공유 | 별도의 메모리 공간 사용, 완전히 독립적 |
| 메모리 사용 | 스택만 독립적으로 사용, 나머지는 공유 | 각각 독립된 메모리 공간 할당 |
| 통신 | 간단하며 빠름 (메모리 공유) | 느림 (IPC 기법 필요, 예: Queue, Pipe) |
| 운영체제 리소스 | 가벼움 (한 프로세스 내에서 관리) | 무겁고 리소스 소모가 큼 |
| 응용 사례 | I/O 바운드 작업 | CPU 바운드 작업 |
| Python에서의 제약 | GIL(Global Interpreter Lock)로 인해 성능 제한 | 프로세스 간 독립 실행으로 GIL의 제약 없음 |
예시
- 스레드: 웹 서버가 다수의 클라이언트 요청을 동시에 처리
- 프로세스: 데이터 분석 프로그램이 여러 CPU를 활용하여 데이터 처리
1.3 CPU 구조와 병렬 처리가 가능한 이유
병렬 처리는 현대 CPU 구조에서 지원하는 멀티코어 아키텍처 덕분에 가능하다.
멀티코어 CPU의 구조
- 코어(Core):
- CPU의 실행 단위로, 하나의 코어는 독립적으로 명령어를 처리할 수 있다.
- 예: 4코어 CPU는 동시에 4개의 작업을 병렬로 실행 가능.
- 스레드 지원:
- 하드웨어 수준에서 동시 멀티스레딩(SMT) 을 지원하여, 각 코어가 여러 스레드를 처리할 수 있다.
- 예: Intel의 Hyper-Threading 기술은 1코어가 2개의 스레드를 실행 가능.
병렬 처리의 원리
- CPU는 각 코어를 활용하여 여러 작업을 동시에 실행하며, 작업 간 문맥 교환(context switching)을 통해 효율적으로 자원을 분배
- 멀티코어 아키텍처는 작업을 병렬로 처리하여 성능을 크게 향상
- I/O 바운드 작업: CPU가 작업 대기 중일 때 다른 작업을 실행
- CPU 바운드 작업: 여러 코어를 사용하여 계산을 병렬로 처리
Python에서의 병렬 처리
- 멀티스레딩: GIL(Global Interpreter Lock)로 인해 한 번에 하나의 스레드만 실행
- 멀티프로세싱: GIL의 제약을 받지 않고, 다중 프로세스를 통해 실제 병렬 처리 가능
한계
- 병렬 처리의 성능은 코어 수와 작업 특성에 따라 제한될 수 있음
- 문맥 교환 비용이 과도할 경우, 오히려 성능이 저하될 가능성도 있음
예시: 멀티코어 활용
Python의 multiprocessing을 사용한 간단한 병렬 처리 예제. 4개의 프로세스가 동시에 실행되어 작업 시간이 병렬로 분배되며, 총 작업 시간이 단축된다.
from multiprocessing import Pool
import time
def square(n):
time.sleep(1) # 작업 지연 시뮬레이션
return n * n
if __name__ == "__main__":
with Pool(4) as pool: # 4개의 프로세스 생성
results = pool.map(square, range(10))
print(results) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]2. 멀티스레딩과 GIL(Global Interpreter Lock)
2.1 GIL의 개념과 Python에서의 역할
GIL(Global Interpreter Lock) 은 Python 인터프리터에서 동시에 실행되는 스레드가 하나의 바이트코드만 실행할 수 있도록 제한하는 메커니즘이다. Python의 기본 구현인 CPython에서 주로 사용되며, 메모리 관리와 데이터 무결성을 보장하기 위해 설계되었다.
GIL의 동작 원리
- GIL은 Python 인터프리터가 한 번에 하나의 스레드만 실행하도록 강제
- 스레드가 작업 중일 때, GIL은 해당 스레드가 작업을 완료하거나 일정 시간(기본적으로 100 바이트코드 실행) 후 다른 스레드로 전환
GIL이 필요한 이유
- Python은 메모리 관리를 위해 레퍼런스 카운팅(Reference Counting) 을 사용한다.
- 여러 스레드가 동시에 메모리를 관리하면 데이터의 무결성이 깨질 수 있다.
- GIL은 이러한 경쟁 상태를 방지하여 안전한 메모리 관리를 보장한다.
GIL의 단점
- GIL은 멀티코어 CPU 환경에서 병렬 처리를 제한한다.
- 멀티스레딩을 사용하더라도, GIL로 인해 동시에 하나의 스레드만 실행 되므로 성능이 저하될 수 있다.
Python에서의 역할
- Python은 GIL 덕분에 개발자가 데이터 경쟁이나 잠금 문제를 신경 쓰지 않아도 된다.
- 그러나 GIL은 CPU 바운드 작업에서는 성능 병목을 일으키며, 병렬 처리가 필요한 경우 멀티프로세싱을 선호하게 만든다.
2.2 멀티스레딩의 제약과 실제 동작 방식
멀티스레딩의 제약
-
GIL로 인한 동시 실행 제한
- Python 멀티스레딩은 GIL로 인해 동시 실행 이 아닌 순차 실행 처럼 동작한다.
- 하나의 스레드가 GIL을 점유하면 다른 스레드는 GIL이 해제될 때까지 대기해야 한다.
-
CPU 바운드 작업에서의 비효율성
- GIL은 멀티코어 환경에서 CPU 바운드 작업의 병렬 성능을 제한한다.
- 예: 대규모 수학 연산을 멀티스레딩으로 실행해도 성능 이점이 거의 없다.
-
I/O 바운드 작업에서의 효율성
- 멀티스레딩은 GIL이 활성화된 상태에서도 I/O 작업 중 GIL이 해제되므로 효율적으로 동작할 수 있다.
- 예: 파일 읽기/쓰기, 네트워크 요청 처리
실제 동작 방식
멀티스레딩은 Python의 threading 모듈을 사용해 구현한다.
기본 스레드 실행 예제
import threading
import time
def worker(task_id):
print(f"Task {task_id} started")
time.sleep(2) # 작업 지연
print(f"Task {task_id} finished")
threads = []
for i in range(3):
thread = threading.Thread(target=worker, args=(i,))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()출력 예시
Task 0 started
Task 1 started
Task 2 started
Task 0 finished
Task 1 finished
Task 2 finished동작 설명
- 3개의 스레드가 동시에 실행되지만, GIL로 인해 하나의 스레드만 CPU를 사용할 수 있다.
- 작업이 I/O 대기 상태로 들어가면 GIL이 해제되어 다른 스레드가 실행된다.
2.3 멀티스레딩이 유용한 경우와 한계점
유용한 경우
-
I/O 바운드 작업
- GIL은 I/O 작업 중 자동으로 해제되므로, 파일 처리, 네트워크 요청, 데이터베이스 작업에서 효율적이다.
- 예: 웹 스크래핑, 비동기 로그 기록
-
배경 작업 처리
- UI와 같은 메인 스레드에서 작업을 방해하지 않고, 배경에서 작업을 실행할 수 있다.
- 예: GUI 애플리케이션에서 데이터를 주기적으로 백업
-
경량 작업
- 작업이 짧고 반복적인 경우, 멀티스레딩은 빠르고 간단하게 구현할 수 있다.
한계점
-
병렬 처리 성능 제한
- GIL로 인해 멀티스레딩은 CPU 바운드 작업에서 거의 성능 이점을 제공하지 않는다.
- 예: 대규모 데이터 분석, 수학 연산은 멀티스레딩보다 멀티프로세싱이 적합하다.
-
데이터 경쟁과 데드락
- 여러 스레드가 동일한 자원을 공유할 경우, 경쟁 상태와 데드락이 발생할 수 있다.
- Python은 이를 방지하기 위해 Lock 객체를 제공하지만, 추가적인 코드 작성이 필요하다.
데드락 방지 예제
with lock구문을 사용하여 하나의 스레드만counter변수에 접근 가능하도록 보장
import threading
lock = threading.Lock()
def safe_increment(counter):
with lock: # 자원을 안전하게 보호
counter[0] += 1
counter = [0]
threads = [threading.Thread(target=safe_increment, args=(counter,)) for _ in range(10)]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print(counter[0]) # 출력: 103. 멀티스레딩 실습
3.1 Python의 threading 모듈 소개
Python의 threading 모듈은 멀티스레딩 작업을 수행할 수 있도록 설계된 표준 라이브러리이다. 이 모듈을 사용하면 여러 스레드를 생성하고 관리하며, 동시 실행 작업을 처리할 수 있다.
주요 클래스 및 메서드
Thread클래스: 스레드를 생성하고 실행하는 데 사용- 주요 메서드:
start(),join(),is_alive()
- 주요 메서드:
Lock클래스: 스레드 간 데이터 충돌을 방지하기 위한 잠금 메커니즘 제공Condition클래스: 스레드 간 신호 및 상태를 관리하는 데 사용current_thread()함수: 현재 실행 중인 스레드 객체 반환
3.2 스레드 생성 및 실행 예제
Python의 threading.Thread 클래스를 사용하여 스레드를 생성하고 실행하는 방법은 다음과 같다.
기본 스레드 생성 및 실행
import threading
import time
def print_numbers():
for i in range(5):
print(f"Number: {i}")
time.sleep(1)
# 스레드 생성
thread = threading.Thread(target=print_numbers)
# 스레드 시작
thread.start()
# 메인 스레드 작업
print("Main thread is running.")
# 스레드가 종료될 때까지 대기
thread.join()
print("Thread finished.")출력 예시
Main thread is running.
Number: 0
Number: 1
Number: 2
Number: 3
Number: 4
Thread finished.- 설명
-thread.start()메서드는 스레드를 시작하고,thread.join()은 해당 스레드가 종료될 때까지 기다린다.
- 메인 스레드와 작업 스레드가 동시에 실행되며, 서로 독립적으로 작업을 수행한다.
클래스를 사용한 스레드 생성
class PrintNumbersThread(threading.Thread):
def run(self):
for i in range(5):
print(f"Class-based Number: {i}")
time.sleep(1)
thread = PrintNumbersThread()
thread.start()
thread.join()- 설명
-Thread클래스를 상속받아 사용자 정의 스레드를 생성
-run메서드에 작업 내용을 정의하여, 스레드의 주요 동작을 구현한다.
3.3 Lock과 Deadlock 방지
멀티스레딩 환경에서는 공유 자원에 여러 스레드가 동시에 접근하면서 데이터 충돌 또는 데드락(Deadlock) 이 발생할 수 있다. 이를 방지하기 위해 Lock 객체를 사용한다.
Lock 사용 예제
import threading
lock = threading.Lock()
counter = 0
def increment():
global counter
for _ in range(100000):
with lock: # 공유 자원 보호
counter += 1
threads = [threading.Thread(target=increment) for _ in range(2)]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print(f"Final counter value: {counter}")출력
Final counter value: 200000- 설명
with lock을 사용하면 하나의 스레드만counter에 접근 가능- Lock을 사용하지 않을 경우, 데이터 충돌로 인해 값이 예상치 못하게 변경될 수 있다.
데드락 방지
- 데드락은 여러 스레드가 서로의 자원을 기다리며 무한 대기에 빠지는 현상.
- Python에서는
RLock(Reentrant Lock)을 사용해 데드락 문제를 완화할 수 있다.
rlock = threading.RLock()
def task():
with rlock:
with rlock: # 동일한 스레드에서 재진입 가능
print("Task executed safely.")
thread = threading.Thread(target=task)
thread.start()
thread.join()3.4 Producer-Consumer 패턴 구현
Producer-Consumer 패턴 은 한쪽에서 데이터를 생성(Producer)하고, 다른 쪽에서 이를 소비(Consumer)하는 멀티스레딩 작업에서 자주 사용되는 패턴이다. Python에서는 queue.Queue 를 사용해 간단히 구현할 수 있다.
예제 코드
import threading
import queue
import time
q = queue.Queue()
def producer():
for i in range(5):
item = f"Item {i}"
q.put(item) # 아이템 생성
print(f"Produced: {item}")
time.sleep(1)
def consumer():
while True:
item = q.get() # 아이템 소비
if item is None: # 종료 신호
break
print(f"Consumed: {item}")
q.task_done()
# 스레드 생성
producer_thread = threading.Thread(target=producer)
consumer_thread = threading.Thread(target=consumer)
producer_thread.start()
consumer_thread.start()
producer_thread.join()
q.put(None) # 종료 신호 전달
consumer_thread.join()출력 예시
Produced: Item 0
Consumed: Item 0
Produced: Item 1
Consumed: Item 1
Produced: Item 2
Consumed: Item 2
...- 설명
-queue.Queue를 사용해 생산자와 소비자 간 데이터 교환을 안전하게 관리
-task_done과join을 사용해 작업 완료를 추적
3.5 스레드 풀(Thread Pool) 활용
스레드 풀 은 일정한 수의 스레드를 미리 생성하여 작업을 분산 처리하는 방식이다. Python에서는 concurrent.futures.ThreadPoolExecutor 를 사용한다.
예제 코드
from concurrent.futures import ThreadPoolExecutor
import time
def task(n):
print(f"Task {n} started.")
time.sleep(2)
print(f"Task {n} finished.")
return n * 2
with ThreadPoolExecutor(max_workers=3) as executor:
futures = [executor.submit(task, i) for i in range(5)]
results = [future.result() for future in futures]
print(f"Results: {results}")출력 예시
Task 0 started.
Task 1 started.
Task 2 started.
Task 0 finished.
Task 1 finished.
Task 2 finished.
...
Results: [0, 2, 4, 6, 8]- 설명
-ThreadPoolExecutor는 최대 3개의 스레드를 생성하여 작업을 병렬로 실행
- 작업 완료 결과를future.result()를 통해 수집 가능
4. 멀티프로세싱의 원리와 응용
4.1 프로세스의 메모리 분리와 장점
멀티프로세싱(Multiprocessing)은 여러 프로세스를 생성해 병렬로 실행하는 기법으로, 각 프로세스는 독립적인 메모리 공간을 사용한다. 이는 멀티스레딩과는 다른 메모리 관리 방식으로, 다음과 같은 특징과 장점을 가진다.
프로세스의 메모리 분리
-
독립된 메모리 공간
- 각 프로세스는 자신만의 메모리 공간(Heap)을 사용하며, 다른 프로세스와 데이터를 공유하지 않는다.
- 한 프로세스의 충돌이나 메모리 손상이 다른 프로세스에 영향을 미치지 않음.
-
안전성 강화:
- 멀티스레딩에서 발생할 수 있는 데이터 경쟁(Race Condition)과 데드락(Deadlock) 문제를 피할 수 있다.
멀티프로세싱의 장점
-
GIL(Global Interpreter Lock) 회피
- Python의 GIL 제약을 받지 않으므로, CPU 바운드 작업에서도 병렬 처리가 가능.
- 멀티코어 CPU의 모든 코어를 활용할 수 있다.
-
데이터 보호
- 독립적인 메모리 구조로 인해 프로세스 간 데이터 충돌이 발생하지 않는다.
-
프로세스 충돌의 국지화
- 한 프로세스가 비정상적으로 종료되더라도, 다른 프로세스의 실행에는 영향을 미치지 않는다.
장점에 따른 응용 사례
- 대규모 데이터 처리
- 이미지 및 비디오 렌더링
- 복잡한 수학적 계산(예: 머신러닝 모델 학습)
4.2 Python의 multiprocessing 모듈 개요
Python의 multiprocessing 모듈은 멀티프로세싱 작업을 쉽게 구현할 수 있도록 설계된 표준 라이브러리이다.
주요 구성 요소
-
Process클래스- 새로운 프로세스를 생성하고 관리하는 기본 클래스
- 주요 메서드:
start(),join(),is_alive()
-
Pool클래스- 워커 프로세스를 관리하여 병렬 작업을 간단히 수행
-
IPC(Inter-Process Communication)
- 프로세스 간 데이터를 교환하기 위한 Queue, Pipe, Manager 제공
-
Lock 및 Semaphore
- 프로세스 간 동기화를 지원하여 데이터 충돌 방지
기본 프로세스 생성 예제
from multiprocessing import Process
def worker(task_id):
print(f"Task {task_id} is running.")
if __name__ == "__main__":
processes = [Process(target=worker, args=(i,)) for i in range(5)]
for p in processes:
p.start()
for p in processes:
p.join()출력 예제
Task 0 is running.
Task 1 is running.
Task 2 is running.
Task 3 is running.
Task 4 is running.- 설명
-Process객체를 사용하여 독립적인 프로세스를 생성
- 각 프로세스는 독립적인 메모리 공간에서 작업을 수행
4.3 프로세스 간 통신(IPC) 기법
멀티프로세싱 환경에서 데이터 공유가 필요한 경우, Python은 IPC(Inter-Process Communication) 를 지원한다. 주로 Queue, Pipe, Manager 를 사용하여 프로세스 간 데이터를 교환한다.
4.3.1 Queue
multiprocessing.Queue 는 프로세스 간 데이터를 안전하게 전달하기 위한 FIFO(First-In-First-Out) 큐이다.
예제
from multiprocessing import Process, Queue
def producer(q):
for i in range(5):
q.put(f"Data {i}")
print(f"Produced: Data {i}")
def consumer(q):
while not q.empty():
data = q.get()
print(f"Consumed: {data}")
if __name__ == "__main__":
q = Queue()
p1 = Process(target=producer, args=(q,))
p2 = Process(target=consumer, args=(q,))
p1.start()
p1.join() # Producer 완료 후 Consumer 시작
p2.start()
p2.join()출력 예시
Produced: Data 0
Produced: Data 1
Produced: Data 2
Produced: Data 3
Produced: Data 4
Consumed: Data 0
Consumed: Data 1
Consumed: Data 2
Consumed: Data 3
Consumed: Data 4- 설명
-Queue는 프로세스 간 데이터를 안전하게 전달하며, 데이터 소비 후 큐에서 제거
4.3.2 Pipe
multiprocessing.Pipe 는 두 프로세스 간 양방향 데이터 통신을 지원하는 간단한 방법이다.
예제
from multiprocessing import Process, Pipe
def sender(conn):
conn.send("Hello from sender!")
conn.close()
def receiver(conn):
message = conn.recv()
print(f"Received: {message}")
if __name__ == "__main__":
parent_conn, child_conn = Pipe()
p1 = Process(target=sender, args=(child_conn,))
p2 = Process(target=receiver, args=(parent_conn,))
p1.start()
p2.start()
p1.join()
p2.join()출력 예시
Received: Hello from sender!- 설명
-Pipe는 간단한 데이터 전송에 적합하며, 양방향 통신도 가능하다.
4.3.3 Manager
multiprocessing.Manager 는 여러 프로세스 간 데이터 구조(예: 리스트, 딕셔너리)를 공유할 수 있도록 지원한다.
예제
from multiprocessing import Process, Manager
def worker(shared_list):
shared_list.append("Task Done")
if __name__ == "__main__":
with Manager() as manager:
shared_list = manager.list() # 공유 리스트 생성
processes = [Process(target=worker, args=(shared_list,)) for _ in range(3)]
for p in processes:
p.start()
for p in processes:
p.join()
print(f"Shared List: {list(shared_list)}")출력 예시
Shared List: ['Task Done', 'Task Done', 'Task Done']- 설명
-Manager는 동기화된 데이터 구조를 제공하여, 여러 프로세스 간 안전하게 데이터 공유 가능
4.3.4 IPC 기법 비교
| 기법 | 특징 | 적합한 상황 |
|---|---|---|
| Queue | FIFO 방식, 데이터 안전성 보장 | 다수의 프로세스가 데이터를 교환할 때 |
| Pipe | 양방향 통신, 간단한 데이터 전송 | 두 프로세스 간 데이터 교환이 필요한 경우 |
| Manager | 동기화된 데이터 구조 제공 | 복잡한 데이터 구조를 여러 프로세스가 공유할 때 |
5. 멀티프로세싱 실습
5.1 단일 작업을 병렬로 처리하는 예제
멀티프로세싱의 기본은 단일 작업을 병렬로 처리하여 성능을 극대화하는 것이다. 예를 들어, 수학적 계산 작업을 여러 프로세스에 분배하면 작업 시간이 크게 단축된다.
예제: 숫자 제곱 계산
from multiprocessing import Process
def square(n):
print(f"Processing {n}: Result = {n * n}")
if __name__ == "__main__":
numbers = [1, 2, 3, 4]
processes = []
for number in numbers:
process = Process(target=square, args=(number,))
processes.append(process)
process.start()
for process in processes:
process.join()출력 예시
Processing 1: Result = 1
Processing 2: Result = 4
Processing 3: Result = 9
Processing 4: Result = 16- 설명
- 각 숫자를 별도의 프로세스에서 계산하도록 분배
- 병렬로 실행되어 작업 시간이 단축된다.
5.2 워커 프로세스를 활용한 작업 분배
워커 프로세스는 반복적인 작업을 병렬로 처리할 때 유용하다. 워커는 주어진 작업을 병렬로 실행하며, 작업의 효율성을 극대화한다.
예제: 문자열 변환
from multiprocessing import Process, Queue
def worker(task_queue):
while not task_queue.empty():
task = task_queue.get()
print(f"Processed: {task.upper()}")
if __name__ == "__main__":
tasks = ["apple", "banana", "cherry", "date"]
task_queue = Queue()
for task in tasks:
task_queue.put(task)
processes = [Process(target=worker, args=(task_queue,)) for _ in range(2)]
for process in processes:
process.start()
for process in processes:
process.join()출력 예시
Processed: APPLE
Processed: BANANA
Processed: CHERRY
Processed: DATE- 설명
- 작업 큐에 데이터를 저장하고, 여러 프로세스가 이를 병렬로 처리
- 각 워커는 큐에서 작업을 가져와 실행
5.3 Shared Memory를 이용한 데이터 공유
멀티프로세싱 환경에서 데이터를 공유하려면 Shared Memory 또는 multiprocessing.Manager 를 사용해야 한다.
예제: 공유 리스트
from multiprocessing import Process, Manager
def worker(shared_list):
for i in range(5):
shared_list.append(i)
print(f"Appended {i}")
if __name__ == "__main__":
with Manager() as manager:
shared_list = manager.list()
processes = [Process(target=worker, args=(shared_list,)) for _ in range(3)]
for process in processes:
process.start()
for process in processes:
process.join()
print(f"Shared List: {list(shared_list)}")출력 예시
Appended 0
Appended 1
Appended 2
Appended 3
Appended 4
...
Shared List: [0, 1, 2, ..., 4, 0, 1, 2, ..., 4]- 설명
-Manager.list()를 사용하여 프로세스 간 데이터 공유를 안전하게 구현
- 여러 프로세스에서 동일한 리스트에 데이터를 추가
5.4 Map-Reduce 패턴 구현
Map-Reduce 패턴은 병렬 처리를 통해 대량의 데이터를 분산 처리하고, 결과를 집계하는 데 사용된다.
예제: 숫자 제곱 합계
from multiprocessing import Pool
def square(n):
return n * n
if __name__ == "__main__":
numbers = range(10)
with Pool(processes=4) as pool:
results = pool.map(square, numbers)
print(f"Squared Results: {results}")
print(f"Sum of Squares: {sum(results)}")출력 예시
Squared Results: [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
Sum of Squares: 285- 설명
-Pool.map메서드를 사용하여 입력 데이터를 병렬로 처리
- 각 프로세스가 숫자를 제곱한 결과를 반환하고, 최종적으로 합계를 계산
5.5 프로세스 풀(Process Pool) 활용
프로세스 풀은 여러 작업을 병렬로 실행하는 데 유용한 구조로, 작업 수에 따라 프로세스를 동적으로 관리한다.
예제: 워드 카운트
from multiprocessing import Pool
def word_count(text):
return len(text.split())
if __name__ == "__main__":
texts = ["Hello World", "Python is great", "Multiprocessing is powerful"]
with Pool(3) as pool:
results = pool.map(word_count, texts)
print(f"Word Counts: {results}")출력 예시
Word Counts: [2, 3, 3]- 설명
Pool은 최대 3개의 프로세스를 생성하여 작업을 병렬로 처리- 각 텍스트의 단어 개수를 계산하여 결과를 반환
비동기 작업 처리
from multiprocessing import Pool
def task(n):
return n * 2
if __name__ == "__main__":
with Pool(3) as pool:
results = [pool.apply_async(task, args=(i,)) for i in range(5)]
outputs = [result.get() for result in results]
print(f"Results: {outputs}")출력 예시
Results: [0, 2, 4, 6, 8]- 설명
-apply_async메서드를 사용하여 작업을 비동기로 처리.
- 작업 완료 후get()메서드를 호출해 결과를 가져온다.
6. 멀티스레딩과 멀티프로세싱의 성능 비교
6.1 I/O 바운드와 CPU 바운드 작업
멀티스레딩과 멀티프로세싱의 선택은 작업의 특성에 따라 달라진다. 작업은 크게 I/O 바운드(I/O-Bound) 와 CPU 바운드(CPU-Bound) 로 나뉜다.
I/O 바운드 작업
I/O 바운드 작업은 입출력 연산 (파일 읽기/쓰기, 네트워크 요청 등)에 의해 처리 속도가 제한되는 작업이다.
-
특징
- 작업 대부분이 I/O 대기 상태에서 이루어지므로, CPU 사용량이 낮다.
- GIL(Global Interpreter Lock)이 I/O 작업 중에는 해제되므로, 멀티스레딩이 적합하다.
-
예시
- 대규모 웹 크롤링
- 로그 파일 저장 및 네트워크 데이터 처리
I/O 바운드 작업: 멀티스레딩 예제
import threading
import time
def io_task(task_id):
print(f"Task {task_id} started.")
time.sleep(2) # I/O 대기 시간 시뮬레이션
print(f"Task {task_id} finished.")
threads = [threading.Thread(target=io_task, args=(i,)) for i in range(5)]
for thread in threads:
thread.start()
for thread in threads:
thread.join()- 설명
- 각 스레드는 독립적으로 I/O 작업을 수행하며, GIL의 제약을 받지 않는다.
CPU 바운드 작업
CPU 바운드 작업은 계산 연산 (복잡한 수학 계산, 데이터 처리 등)이 주를 이루는 작업이다.
-
특징
- 대부분의 작업이 CPU를 집중적으로 사용하므로, GIL로 인해 멀티스레딩의 성능이 제한된다.
- 멀티프로세싱은 각 프로세스가 독립적으로 실행되므로, CPU 바운드 작업에 적합하다.
-
예시
- 머신러닝 모델 학습
- 대규모 행렬 연산
CPU 바운드 작업: 멀티프로세싱 예제
from multiprocessing import Pool
import math
def compute_factorial(n):
return math.factorial(n)
if __name__ == "__main__":
numbers = [100000, 200000, 300000, 400000]
with Pool(4) as pool:
results = pool.map(compute_factorial, numbers)
print("Factorials computed.")- 설명
- 멀티프로세싱을 사용해 각 숫자의 팩토리얼 계산을 병렬로 처리하며, CPU 코어를 효율적으로 활용한다.
6.2 벤치마킹을 통한 성능 차이 분석
성능 비교 실험
I/O 바운드와 CPU 바운드 작업에서 멀티스레딩과 멀티프로세싱의 성능을 비교해 보자.
벤치마크 코드
import threading
import multiprocessing
import time
def io_task(task_id):
time.sleep(2)
def cpu_task(n):
total = 0
for i in range(n):
total += i
def benchmark(task, worker_count, args, use_multiprocessing):
start_time = time.time()
workers = []
if use_multiprocessing:
for _ in range(worker_count):
p = multiprocessing.Process(target=task, args=args)
workers.append(p)
p.start()
else:
for _ in range(worker_count):
t = threading.Thread(target=task, args=args)
workers.append(t)
t.start()
for worker in workers:
worker.join()
end_time = time.time()
print(f"Time taken: {end_time - start_time:.2f} seconds")테스트 실행
if __name__ == "__main__":
print("I/O Bound - Multithreading")
benchmark(io_task, 5, (0,), False)
print("I/O Bound - Multiprocessing")
benchmark(io_task, 5, (0,), True)
print("CPU Bound - Multithreading")
benchmark(cpu_task, 5, (10**6,), False)
print("CPU Bound - Multiprocessing")
benchmark(cpu_task, 5, (10**6,), True)결과 모습
I/O Bound - Multithreading
Time taken: 2.00 seconds
I/O Bound - Multiprocessing
Time taken: 2.10 seconds
CPU Bound - Multithreading
Time taken: 8.50 seconds
CPU Bound - Multiprocessing
Time taken: 2.20 seconds- 분석
- I/O 바운드 작업에서는 멀티스레딩과 멀티프로세싱 모두 유사한 성능을 보인다.
- CPU 바운드 작업에서는 GIL의 제약으로 인해 멀티프로세싱이 압도적으로 빠르다.
6.3 파이썬에서의 효율적인 선택 기준
멀티스레딩이 적합한 경우
- I/O 바운드 작업: 네트워크 요청, 파일 읽기/쓰기
- 경량 작업: 짧고 빠르게 완료되는 작업
- 자원 공유가 필요한 작업: 스레드는 메모리를 공유하므로 통신 비용이 적다.
멀티프로세싱이 적합한 경우
- CPU 바운드 작업: 대규모 데이터 처리, 복잡한 연산
- 독립적 작업: 프로세스 간 데이터 의존성이 적을 때
- GIL 우회가 필요한 작업: Python의 GIL이 병목을 유발하는 경우
선택 가이드
| 작업 유형 | 적합한 방법 | 예시 |
|---|---|---|
| I/O 바운드 | 멀티스레딩 | 웹 크롤링, 비동기 파일 처리 |
| CPU 바운드 | 멀티프로세싱 | 머신러닝, 대규모 데이터 분석 |
| 독립적 작업 | 멀티프로세싱 | 비디오 렌더링, 병렬 데이터 처리 |
| 메모리 공유 필요 | 멀티스레딩 | 이벤트 처리, 상태 동기화 |
7. 병렬 처리와 비동기 처리의 차이
7.1 비동기 프로그래밍과 멀티스레딩의 비교
비동기 프로그래밍(Asynchronous Programming) 과 멀티스레딩(Multithreading) 은 병렬 처리와 유사한 목표(작업 시간 단축, 효율성 향상)를 가지고 있지만, 동작 원리와 적용 방식은 매우 다르다.
동작 방식의 차이
멀티스레딩
멀티스레딩은 여러 스레드를 생성하여 동시에 작업을 수행한다. 각 스레드는 독립적으로 실행되며, CPU와 메모리 리소스를 공유한다.
- 문맥 전환(Context Switching): 스레드 간 작업 전환은 CPU에서 문맥 전환이 필요하며, 이로 인해 오버헤드가 발생한다.
- 병렬 처리: 실제로 여러 작업이 동시에 실행된다(진정한 동시성)
비동기 프로그래밍
비동기 프로그래밍은 작업을 스케줄링하여 한 작업이 대기 상태에 있을 때 다른 작업을 실행한다. 단일 스레드에서 실행되며, 문맥 전환 없이 효율적으로 작업을 처리한다.
- 이벤트 루프(Event Loop): 작업을 처리하고 완료될 때까지 대기하지 않고, 다른 작업을 계속 실행하는 구조
- 협력적 동시성: 작업이 CPU를 점유하지 않고, 비동기 작업 완료 시점에 실행된다.
비교 표
| 특징 | 멀티스레딩 | 비동기 프로그래밍 |
|---|---|---|
| 동작 방식 | 여러 스레드에서 병렬로 작업을 실행 | 단일 스레드에서 이벤트 루프를 통해 작업 처리 |
| 동시 실행 여부 | 진정한 동시 실행 가능 | 동시 실행되지 않음 (작업을 협력적으로 전환) |
| 문맥 전환 | 스레드 간 문맥 전환으로 오버헤드 발생 | 문맥 전환 없이 이벤트 루프에서 처리 |
| 적합한 작업 | CPU 바운드 및 I/O 바운드 작업 | I/O 바운드 작업 (예: 네트워크 요청) |
| 복잡성 | 상태 동기화와 잠금 문제로 구현이 복잡 | 상대적으로 단순한 코드 구현 |
| Python에서의 GIL 영향 | GIL로 인해 멀티스레딩 성능 제한 | GIL 영향을 받지 않음 (I/O 바운드 작업에서 효율적) |
7.2 Python의 asyncio와의 차이점
asyncio 는 Python에서 비동기 프로그래밍을 구현하기 위한 표준 라이브러리이다. 이는 멀티스레딩이나 멀티프로세싱과는 다른 방식으로 동시성을 처리한다.
주요 특징
-
단일 스레드, 단일 프로세스
asyncio는 단일 스레드, 단일 프로세스에서 이벤트 루프를 사용해 동시 작업을 처리한다.
-
비동기 함수
async및await키워드를 사용하여 비동기 작업을 정의하고 실행한다.
-
콜백 기반 처리
- 작업 완료 시 콜백을 실행하여 효율적으로 작업을 스케줄링
asyncio와 멀티스레딩의 차이
| 특징 | asyncio | 멀티스레딩 |
|---|---|---|
| 동작 구조 | 이벤트 루프를 사용하여 작업 스케줄링 | 여러 스레드가 병렬로 작업 수행 |
| 사용 자원 | 단일 스레드, 메모리 사용량 적음 | 여러 스레드, 메모리 사용량 많음 |
| 복잡성 | 상대적으로 간단, async/await 사용 | 잠금(Lock) 및 동기화 코드 필요 |
| 적합한 작업 | I/O 대기 작업 (예: HTTP 요청) | 병렬로 실행할 CPU 집약 작업 |
| 성능 | GIL 영향을 받지 않음 (I/O 바운드 작업) | GIL로 인해 성능 제한 |
예제 비교: 파일 다운로드
asyncio를 사용한 비동기 작업
import asyncio
async def download_file(file_id):
print(f"Downloading file {file_id}...")
await asyncio.sleep(2) # I/O 대기 시뮬레이션
print(f"File {file_id} downloaded.")
async def main():
tasks = [download_file(i) for i in range(3)]
await asyncio.gather(*tasks)
asyncio.run(main())- 멀티스레딩을 사용한 동시 작업
import threading
import time
def download_file(file_id):
print(f"Downloading file {file_id}...")
time.sleep(2) # I/O 대기 시뮬레이션
print(f"File {file_id} downloaded.")
threads = [threading.Thread(target=download_file, args=(i,)) for i in range(3)]
for thread in threads:
thread.start()
for thread in threads:
thread.join()- 비교
-asyncio는 코드가 직관적이고 간결하며, 단일 스레드에서 실행되므로 메모리 사용량이 적다.
- 멀티스레딩은 복잡하지만 I/O와 CPU 작업이 혼합된 경우에도 사용할 수 있다.
7.3 적합한 기술 선택을 위한 기준
작업의 특성에 따라 멀티스레딩, 멀티프로세싱, 비동기 프로그래밍 중 적합한 기술을 선택해야 한다.
선택 기준
- 작업 유형
- I/O 바운드 작업:
asyncio또는 멀티스레딩 - CPU 바운드 작업: 멀티프로세싱
- I/O 바운드 작업:
- 리소스 사용
- 메모리 사용량이 제한적일 경우:
asyncio - 다중 코어를 활용해야 하는 경우: 멀티프로세싱
- 메모리 사용량이 제한적일 경우:
- 복잡성
- 코드가 간단해야 하는 경우:
asyncio - 상태 동기화가 필요하지 않은 경우: 멀티프로세싱
- 코드가 간단해야 하는 경우:
선택 시나리오
| 시나리오 | 적합한 기술 | 이유 |
|---|---|---|
| 웹 크롤링 | asyncio | 많은 네트워크 요청을 효율적으로 처리 가능 |
| 이미지 처리 | 멀티프로세싱 | CPU 집약 작업으로, GIL을 우회하여 병렬 처리 |
| 파일 다운로드 | 멀티스레딩 | I/O 대기 시간이 많으며, 상태 동기화가 필요 없. |
| 대규모 데이터 분석 | 멀티프로세싱 | 다중 코어를 활용하여 계산 작업 병렬화 |
| 실시간 이벤트 처리 | asyncio | 이벤트 루프를 사용하여 응답성과 효율성 극대화 |
8. 멀티스레딩과 멀티프로세싱의 보안 이슈
8.1 Deadlock과 Race Condition
Deadlock(교착 상태)
Deadlock은 두 개 이상의 스레드 또는 프로세스가 서로 자원을 점유하고 있으며, 서로의 자원이 해제되기를 기다리며 무한 대기에 빠지는 상태를 의미한다.
Deadlock 발생 조건
- 상호 배제(Mutual Exclusion): 한 번에 하나의 스레드/프로세스만 자원을 점유
- 점유 대기(Hold and Wait): 자원을 점유한 상태에서 다른 자원을 기다림
- 비선점(Non-preemptive): 자원을 강제로 해제할 수 없음
- 순환 대기(Circular Wait): 여러 스레드가 자원을 순환적으로 기다림
Deadlock 방지 방법
- 자원 순서 정하기: 모든 스레드가 자원을 요청하는 순서를 정하여, 순환 대기를 방지
- 타임아웃 설정: 일정 시간이 지나면 대기를 중단하고 작업을 종료
- 교착 상태 감지 알고리즘: 시스템이 Deadlock 상태를 감지하고, 자원을 강제로 해제
Race Condition(경쟁 상태)
Race Condition은 두 개 이상의 스레드가 동일한 자원에 동시에 접근하려고 하여, 결과가 실행 순서에 따라 달라지는 문제를 의미한다.
Race Condition 예제
import threading
counter = 0
def increment():
global counter
for _ in range(1000000):
counter += 1
threads = [threading.Thread(target=increment) for _ in range(2)]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print(f"Final Counter: {counter}")출력 예시
Final Counter: 1689537 (예상값 2000000과 다름)Race Condition 방지
- Lock 사용:
threading.Lock을 사용하여 공유 자원을 보호
import threading
lock = threading.Lock()
counter = 0
def increment():
global counter
for _ in range(1000000):
with lock: # Lock으로 자원 보호
counter += 1
threads = [threading.Thread(target=increment) for _ in range(2)]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print(f"Final Counter: {counter}") # 출력: 20000008.2 프로세스 간 데이터 보호와 검증
멀티프로세싱은 각 프로세스가 독립적인 메모리 공간을 사용하지만, 프로세스 간 데이터를 공유할 경우 적절한 검증과 보호가 필요하다.
데이터 보호의 필요성
- 데이터 무결성: 프로세스 간 데이터가 손상되거나 변경되지 않아야 한다.
- 경쟁 상태: 동시에 같은 데이터를 읽고 쓰면, 예상치 못한 결과가 발생할 수 있다.
보호 기술
- IPC(Inter-Process Communication): Queue 또는 Pipe를 통해 데이터를 안전하게 교환
- Manager 사용: 공유 데이터 구조를 동기화하여 보호
예제: Queue를 이용한 데이터 보호
from multiprocessing import Process, Queue
def worker(queue):
while not queue.empty():
data = queue.get()
print(f"Processing: {data}")
if __name__ == "__main__":
q = Queue()
for i in range(5):
q.put(i)
processes = [Process(target=worker, args=(q,)) for _ in range(2)]
for p in processes:
p.start()
for p in processes:
p.join()8.3 스레드와 프로세스 사용 시 보안 강화 방법
스레드 사용 시 보안 강화
-
Lock과 RLock 사용
- 공유 자원을 동기화하여 데이터 무결성을 보호
-
상태 동기화
Condition또는Semaphore를 사용하여 작업 흐름을 제어
-
Deadlock 방지
- 타임아웃 설정 및 순서 기반 자원 접근
프로세스 사용 시 보안 강화
-
데이터 검증
- 프로세스 간 데이터를 전송하기 전에 무결성을 검증
- 예: 데이터에 해시 값을 추가하여 손상 여부 확인
-
독립된 자원 관리
- 각 프로세스가 자신의 메모리에서만 작업하도록 설계
-
관리자 객체 사용
multiprocessing.Manager를 활용해 공유 데이터 구조를 동기화
권장 사항
- 정기적인 코드 검토: 잠재적인 Deadlock과 Race Condition을 미리 식별
- 도구 사용:
PyLint나ThreadSanitizer와 같은 정적 분석 도구를 사용해 스레드/프로세스 오류 감지
9. 응용 가능한 사례
9.1 대규모 데이터 처리 (ETL 작업)
ETL(Extract, Transform, Load) 작업은 대규모 데이터를 추출, 변환, 적재하는 과정에서 멀티스레딩과 멀티프로세싱의 활용도가 매우 높다.
금융 데이터 처리
대형 금융 기관은 일일 거래 데이터를 분석하기 위해 ETL 작업을 수행한다. 이러한 작업에서는 대규모 데이터베이스에서 데이터를 추출하고, 여러 포맷으로 저장된 데이터를 정규화한 후, 분석 시스템에 적재한다.
멀티프로세싱 적용
- 추출 단계: 데이터베이스에서 여러 테이블을 동시에 읽기 위해 각 테이블마다 별도의 프로세스를 할당
- 변환 단계: 데이터 정규화 및 결합 작업을 병렬로 처리하여 처리 시간을 단축
- 적재 단계: 병렬로 데이터를 적재하여 데이터베이스 쓰기 속도를 최적화
Python 코드 예제: 멀티프로세싱으로 CSV 파일 처리
from multiprocessing import Pool
import pandas as pd
def process_csv(file_name):
data = pd.read_csv(file_name)
# 데이터 정규화 작업 수행
data['processed'] = data['value'] * 2
data.to_csv(f"processed_{file_name}", index=False)
if __name__ == "__main__":
files = ["data1.csv", "data2.csv", "data3.csv"]
with Pool(processes=3) as pool:
pool.map(process_csv, files)9.2 웹 크롤링 및 데이터 수집
웹 크롤링(Web Crawling) 은 대규모 웹 데이터를 수집하는 작업에서 멀티스레딩과 비동기 처리가 필수적이다.
검색 엔진 크롤링
검색 엔진은 웹 페이지의 내용을 크롤링하고 색인화하기 위해 수천 개의 URL을 동시 처리해야 한다. 여기서 멀티스레딩은 네트워크 요청을 병렬로 실행하여 처리 속도를 크게 향상시킨다.
멀티스레딩 적용
- 여러 스레드를 생성하여 각 스레드가 다른 URL을 처리
- 데이터베이스에 크롤링한 데이터를 적재하기 위한 스레드 추가
Python 코드 예제: 멀티스레딩으로 웹 크롤링
import threading
import requests
def fetch_url(url):
response = requests.get(url)
print(f"Fetched {url} with status {response.status_code}")
if __name__ == "__main__":
urls = ["https://example.com", "https://example.org", "https://example.net"]
threads = [threading.Thread(target=fetch_url, args=(url,)) for url in urls]
for thread in threads:
thread.start()
for thread in threads:
thread.join()9.3 머신러닝 모델 학습 가속화
머신러닝 모델 학습 은 대규모 데이터를 반복적으로 처리하고 복잡한 연산을 수행하기 때문에 CPU 또는 GPU 기반 병렬 처리가 필수적이다.
이미지 인식 모델 학습
컴퓨터 비전 프로젝트에서 이미지 데이터셋을 학습하는 경우, 멀티프로세싱을 통해 데이터 로딩과 학습 단계를 병렬화하여 학습 속도를 개선한다.
멀티프로세싱 적용
- 데이터 전처리: 이미지 데이터를 여러 프로세스에서 병렬로 전처리
- 미니 배치 병렬 처리: 학습 데이터를 나누어 각 프로세스에서 처리한 후 결과를 병합
Python 코드 예제: 데이터 전처리 병렬화
from multiprocessing import Pool
import cv2
def preprocess_image(file_name):
image = cv2.imread(file_name)
processed = cv2.resize(image, (128, 128))
cv2.imwrite(f"processed_{file_name}", processed)
if __name__ == "__main__":
image_files = ["img1.jpg", "img2.jpg", "img3.jpg"]
with Pool(processes=3) as pool:
pool.map(preprocess_image, image_files)9.4 네트워크 서버 및 클라이언트 구현
네트워크 서버와 클라이언트 는 여러 요청을 동시에 처리해야 하기 때문에 멀티스레딩과 멀티프로세싱이 많이 사용된다.
채팅 서버
대규모 사용자 기반의 채팅 애플리케이션은 사용자의 메시지 전송과 수신을 실시간으로 처리해야 한다. 이를 위해 멀티스레딩 또는 비동기 I/O가 주로 사용된다.
멀티스레딩 적용
- 서버: 각 클라이언트 연결을 별도의 스레드로 처리하여 다수의 사용자 요청을 동시에 처리
- 클라이언트: 메시지 전송과 수신을 각각 별도의 스레드로 처리
Python 코드 예제: 멀티스레딩 채팅 서버
import socket
import threading
def handle_client(client_socket):
while True:
message = client_socket.recv(1024).decode()
if not message:
break
print(f"Received: {message}")
client_socket.send(f"Echo: {message}".encode())
client_socket.close()
if __name__ == "__main__":
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(("0.0.0.0", 9999))
server.listen(5)
print("Server listening on port 9999.")
while True:
client, addr = server.accept()
print(f"Accepted connection from {addr}")
client_handler = threading.Thread(target=handle_client, args=(client,))
client_handler.start()10. 최적화 전략과 고급 기법
10.1 작업 스케줄링과 로드 밸런싱
작업 스케줄링과 로드 밸런싱은 멀티스레딩 및 멀티프로세싱의 효율성을 극대화하기 위한 핵심 전략이다. 작업 스케줄링은 작업을 프로세스나 스레드에 적절히 분배하여 병목현상을 방지하며, 로드 밸런싱은 시스템 리소스(CPU, 메모리)의 사용을 균등하게 유지한다.
작업 스케줄링의 원리
-
Static Scheduling: 작업을 시작하기 전에 고정된 방식으로 작업을 스레드 또는 프로세스에 할당
- 장점: 구현이 간단하며 오버헤드가 적음
- 단점: 작업 부하가 동적으로 변할 경우 비효율적
-
Dynamic Scheduling: 작업 실행 중에 작업을 동적으로 분배
- 장점: 작업 부하에 따라 균형을 유지 가능
- 단점: 실행 중 추가 오버헤드 발생
로드 밸런싱 기술
- Round Robin: 각 프로세스나 스레드에 작업을 순차적으로 할당
- Weighted Scheduling: 작업 크기나 중요도에 따라 우선순위를 부여해 분배
- Work Stealing: 부하가 적은 스레드가 다른 스레드의 작업을 가져와 처리
Python 예제: Task Scheduling
from multiprocessing import Pool
import random
def process_task(task_id):
work = random.randint(1, 5)
print(f"Task {task_id} processing for {work} seconds")
time.sleep(work)
return f"Task {task_id} completed"
if __name__ == "__main__":
tasks = range(10)
with Pool(processes=4) as pool:
results = pool.map(process_task, tasks)
print(results)- 설명
- 작업을 동적으로 스케줄링하여, 프로세스 간 부하를 균등하게 분배
- 작업 시간이 랜덤하더라도 로드 밸런싱을 통해 효율적으로 처리
10.2 멀티스레딩과 멀티프로세싱의 하이브리드 접근
하이브리드 접근은 멀티스레딩과 멀티프로세싱의 장점을 결합하여, 복잡한 애플리케이션의 성능을 극대화한다.
왜 하이브리드 접근이 필요한가?
- 멀티프로세싱은 CPU 바운드 작업에 적합하지만, I/O 바운드 작업에서 비효율적일 수 있다.
- 멀티스레딩은 I/O 바운드 작업에 적합하지만, GIL로 인해 CPU 바운드 작업에 한계가 있다.
- 하이브리드 접근은 두 기술의 장점을 결합하여, 다양한 작업을 동시에 처리할 수 있다.
하이브리드 접근 예제: 데이터 처리 및 네트워크 요청
데이터 처리(멀티프로세싱) + 네트워크 요청(멀티스레딩)
from multiprocessing import Process, Queue
import threading
import requests
def fetch_data(url, results):
response = requests.get(url)
results.append(response.text[:100]) # 첫 100자만 저장
def process_urls(queue):
while not queue.empty():
url = queue.get()
results = []
threads = [threading.Thread(target=fetch_data, args=(url, results)) for _ in range(3)]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print(f"Results for {url}: {results}")
if __name__ == "__main__":
url_queue = Queue()
urls = ["https://example.com"] * 5
for url in urls:
url_queue.put(url)
processes = [Process(target=process_urls, args=(url_queue,)) for _ in range(2)]
for process in processes:
process.start()
for process in processes:
process.join()- 설명
- 멀티프로세싱을 사용해 URL 작업을 분배
- 각 프로세스 내에서 멀티스레딩으로 병렬 네트워크 요청 처리
10.3 고성능 병렬 처리를 위한 C 확장(Python과 C/C++ 통합)
Python은 GIL로 인해 고성능 병렬 처리가 제한적이지만, C 확장을 통해 병렬 처리 성능을 대폭 향상시킬 수 있다.
C 확장을 사용하는 이유
- Python은 인터프리터 기반으로 실행되므로, CPU 집약 작업에서 속도가 느릴 수 있다.
- C/C++로 작성된 코드는 Python의 GIL을 우회하여 병렬 처리가 가능하다.
C 확장 기술
-
Cython
- Python 코드를 컴파일된 C 코드로 변환하여 성능 향상
- 멀티스레딩과 병렬 처리 기능을 추가로 지원
-
ctypes
- Python에서 C 라이브러리를 호출하여 병렬 연산 수행
-
C++ 확장(Pybind11)
- Python과 C++ 코드를 통합하여 복잡한 연산을 최적화
Cython을 사용한 병렬 처리 예제
# Cython 파일: parallel_sum.pyx
def parallel_sum(n):
cdef int i, total = 0
for i in range(n):
total += i
return total- Cython으로 컴파일한 후, Python에서 병렬 처리를 수행
from multiprocessing import Pool
from parallel_sum import parallel_sum
if __name__ == "__main__":
numbers = [10**6, 10**7, 10**8]
with Pool(3) as pool:
results = pool.map(parallel_sum, numbers)
print(results)11. 결론 및 미래 전망
11.1 멀티스레딩과 멀티프로세싱의 한계
멀티스레딩의 한계
-
Python GIL(Global Interpreter Lock):
- Python의 GIL은 멀티스레딩 환경에서 하나의 스레드만 실행되도록 제한한다. 이는 I/O 바운드 작업에는 적합하지만, CPU 집약적인 작업에서는 성능 병목을 초래한다.
-
복잡성:
- 멀티스레딩은 Lock, Semaphore, Condition 등 동기화 메커니즘을 필요로 하며, Race Condition과 Deadlock 같은 문제가 발생하기 쉽다.
-
디버깅 난이도:
- 멀티스레딩에서 상태 관리가 어려워 디버깅과 테스트가 복잡하다.
멀티프로세싱의 한계
-
높은 메모리 사용량
- 각 프로세스가 독립적인 메모리 공간을 사용하므로, 프로세스 수가 증가하면 메모리 사용량이 급격히 증가한다.
-
프로세스 간 통신(IPC) 오버헤드
- 프로세스 간 데이터를 공유하거나 전달할 때 Queue나 Pipe를 사용하는데, 이 과정에서 성능 저하가 발생한다. -
프로세스 생성 비용
- 프로세스를 생성하고 관리하는 데 시간이 많이 소요된다.
11.2 Python GIL 문제를 해결하려는 대안들(PyPy, Jython 등)
Python의 GIL 문제를 해결하려는 다양한 대안들이 존재하며, 이들 중 일부는 GIL의 제약을 완화하거나 완전히 우회한다.
1. PyPy
-
PyPy는 JIT(Just-In-Time) 컴파일러를 사용하여 Python 코드의 실행 속도를 크게 향상시키며, GIL 문제를 완화한다.
-
특징
- CPU 집약 작업에서 큰 성능 개선
- Python 코드를 런타임에 최적화하여 실행
-
한계
- 일부 Python 패키지(특히 C 기반)와 호환되지 않을 수 있다.
2. Jython
-
Jython은 Python 코드를 Java Virtual Machine(JVM)에서 실행할 수 있도록 변환한다.
-
특징
- Java 기반 멀티스레딩을 활용할 수 있어 GIL 제약이 없음
- Java 라이브러리와의 호환성 제공
-
한계
- Python의 최신 버전 지원이 제한적
- 일부 Python 패키지와 호환되지 않음
3. Cython
-
Cython은 Python 코드를 C로 변환하여 컴파일함으로써 GIL 문제를 우회할 수 있다.
-
특징
- 병렬 처리에서 GIL 해제를 명시적으로 구현 가능
- 고성능 병렬 처리가 필요한 애플리케이션에서 사용
-
한계
- 코드 작성 시 추가적인 Cython 문법을 배워야 한다.
4. Python Subinterpreters
-
Python의 미래 버전(PEP 554)에서는 서브 인터프리터를 통해 각 인터프리터가 GIL을 독립적으로 관리하도록 계획 중이다.
-
특징
- 동일 프로세스에서 GIL의 영향을 최소화
- 멀티스레딩과 멀티프로세싱의 장점 결합
11.3 병렬 프로그래밍의 최신 기술과 전망
최신 기술
-
병렬화 프레임워크와 라이브러리
- Ray: Python 기반의 고성능 병렬 컴퓨팅 프레임워크로, 머신러닝 모델 학습과 대규모 데이터 처리를 지원
- Dask: 대규모 병렬 처리 및 분산 처리를 간단히 구현 가능
- Numba: JIT 컴파일러를 통해 Python 코드를 병렬로 실행
-
GPU 기반 병렬 처리
- TensorFlow와 PyTorch와 같은 프레임워크는 GPU를 활용하여 대규모 병렬 처리를 수행
- GPU 기반 컴퓨팅은 딥러닝, 이미지 처리, 과학 시뮬레이션 등에서 높은 성능을 제공
-
Serverless Computing
- AWS Lambda, Google Cloud Functions 등의 서버리스 플랫폼은 병렬 작업을 자동으로 분산 처리하며, 사용자는 리소스 관리에 신경 쓸 필요가 없다.
전망
-
GIL 제거 노력:
- Python 커뮤니티는 GIL 문제를 해결하기 위한 지속적인 노력을 기울이고 있다. PEP 703(글로벌 인터프리터 락 제거)은 이러한 노력의 일부이다.
-
하드웨어 발전과의 융합:
- 멀티코어 CPU와 GPU의 발전은 병렬 프로그래밍의 중요성을 더욱 부각시키고 있다.
-
분산 시스템의 대중화:
- Apache Spark, Hadoop과 같은 분산 시스템이 대규모 병렬 처리의 표준이 되어가고 있으며, Python은 이들 시스템과 통합하여 높은 성능을 제공할 수 있다.
12. 마무리
장장 이틀에 걸쳐 작성한 주제가 드디어 끝이 났다. 일단 오늘까지 작성한 포스팅을 기점으로 2주간 재정비 및 파이널 프로젝트 준비로 데일리 CS를 잠시 쉬어갈 생각인데, 마무리 포스팅으로서 나름 무게감 있는 주제가 된 것 같아 기쁘다.
다만 주제가 좀 넓었던 만큼 양도 따라 늘어, 정말 이 주제가 깊숙히 체화되었는지는 잘 모르겠다. 가능하다면 추후 토이프로젝트를 만들어서라도 활용해보며 감을 잡아보고 싶다.
