AI
How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers [3]

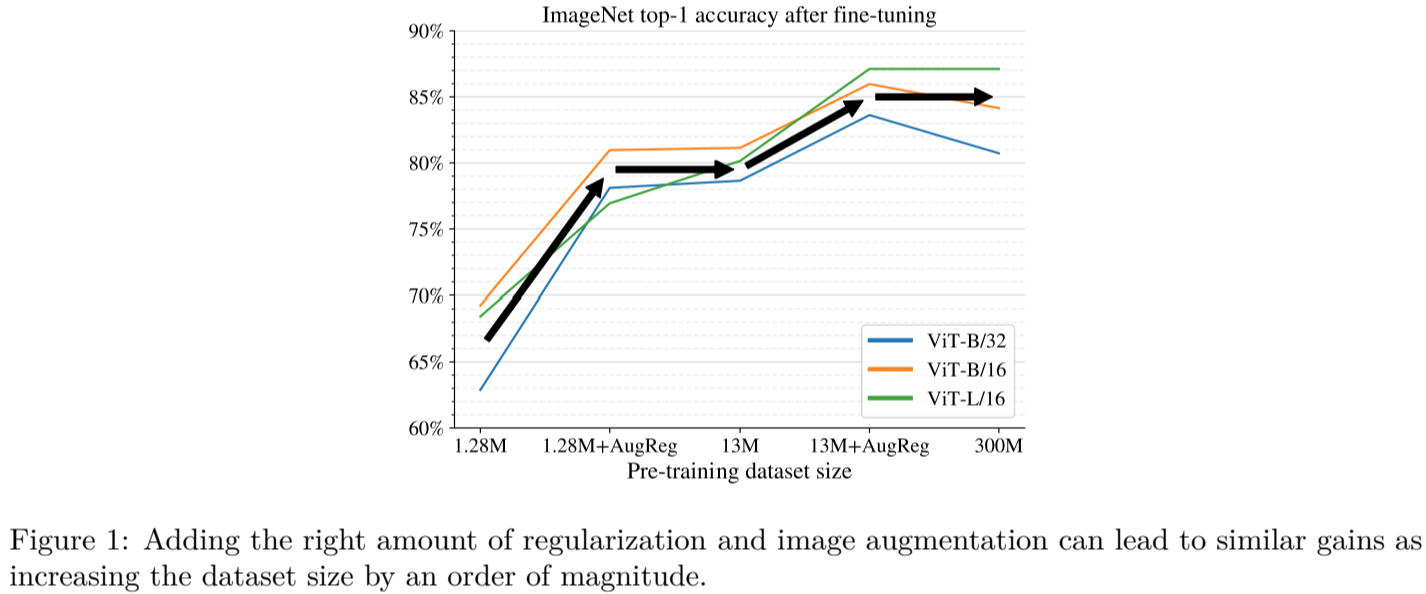
ViT는 image classification, object detection, semantic image segmentation등 광범위하게 CV 분야에 적용되어 높은 성능을 보였다. CNN과 비교했을때, ViT의 약한 inductive bias는 학습하거나 더 작은 데이터셋을 사용할 때, 모델 정규화(model regularization) 또는 데이터 증강(data augmentation) (=AugReg)에 의존적이라고 일반적으로 생각된다. 이 논문에서는 systematic empirical study를 통해서 training dta와, AugReg, model size, compute bugdget(자원)을 더 잘 이해하였다. 증가한 compute와 AugReg의 조합은 모델이 훈련 데이터가 한 자릿수(10배) 더 많은 모델과 동일한 성능을 낼 수 있었다. 즉 적절한 정규화와 데이터 증강에 의존하지 않고 좋은 성능을 낼 수 있는 연구이다.
Reference
[1] Alexey Dosovitskiy, et al, An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR, 2021.
[2] Ilya Tolstikhin, et al, MLP-Mixer: An all-MLP Architecture for Vision, CVPR, 2021.
[3] Andreas Steiner, et al, How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers, CVPR, 2022.
[4] Xiangning Chen, et al, When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations, CVPR, 2022.
[5] Xiaohua Zhai, et al, LiT: Zero-Shot Transfer with Locked-image text Tuning, CVPR, 2022.
[6] Juntang Zhuang, Surrogate Gap Minimization Improves Sharpness-Aware Training, ICLR, 2022.
