
🌟 개요
Ollama는 로컬 환경에서 대규모 언어 모델(LLM, Large Language Model)을 간단히 실행하고 Python 프로젝트에 통합할 수 있도록 도와주는 프레임워크입니다. 해당 포스트에서는 Ollama의 설치 방법부터 Python SDK 사용법, 실제 활용 예제(챗봇 구현, 자동화 에이전트 개발)까지 단계별로 살펴봅니다. (사용 모델은 국산 LLM인 exaone3.5:7.8b입니다.)
Ollama와 Exaone 3.5 소개
Ollama는 Docker처럼 사전 빌드된 모델 패키지를 로컬에서 pull 받아 실행할 수 있도록 설계된 오픈소스 플랫폼입니다. 모델 실행에 필요한 가중치, 설정, 데이터 등을 하나의 패키지(Modelfile)로 묶어 CLI나 REST API로 손쉽게 사용할 수 있습니다.
Exaone 3.5는 LG AI연구원에서 공개한 모델로 한국어에 최적화된 대형 언어 모델로, 문서 요약, 질의응답, 문맥 이해 등에서 높은 성능을 보입니다. LLM 엔지니어링 관점에서도 한글 기반 프로젝트에 적합한 선택지입니다.
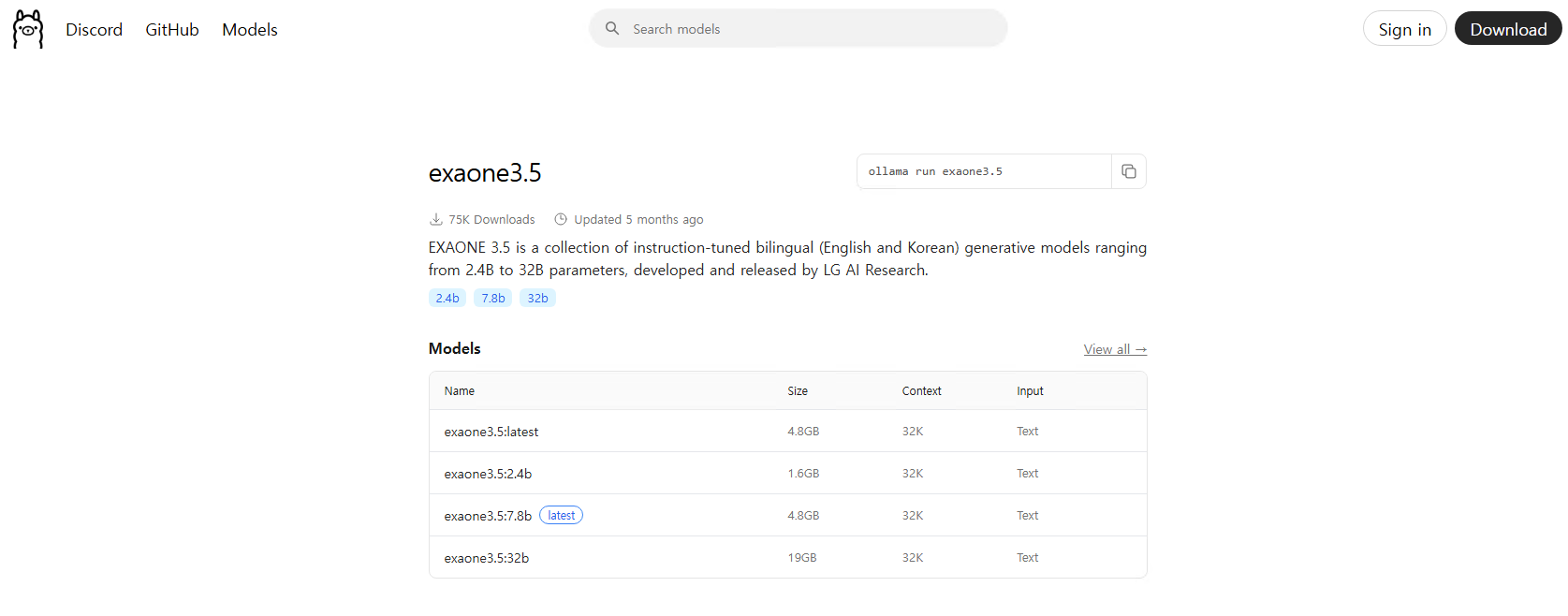
저는 가장 최신에 나온 EXAONE 3.5:7.8b 모델을 사용하여 실습을 진행해보도록 하겠습니다.
Ollama 설치 및 Python 연동
1. Ollama 엔진 설치
macOS / windowsOS
위 링크에서 해당 OS에 맞는 installer를 설치하실 수 있습니다.
Linux
리눅스는 아래 코드를 실행해서 설치하실 수 있습니다.
# Linux
curl -sS https://ollama.ai/install.sh | bash2. 모델 다운로드
(터미널에서 실행)
ollama pull exaone3.5:7.8b3. 모델 실행하기
(터미널에서 실행)
ollama run exaone3.5:7.8b
3. Python SDK 설치
ollama를 파이썬에서 실행하기 위해서는 아래 라이브러리를 설치해야 합니다.
pip install ollama첫 번째 예제: 프롬프트 기반 텍스트 생성
import ollama
result = ollama.generate(model='exaone3.5:7.8b', prompt='우주는 왜 어두운가요?')
print(result['response'])실전 활용 1: 프라이빗 AI 챗봇 구축
아래 함수를 통해 chatSLM.py를 정의하면 바로 챗봇처럼 사용하실 수 있습니다!
import ollama
model_name = 'exaone3.5:7.8b'
messages = [
{"role": "system", "content": "당신은 친절한 인공지능 어시스턴트입니다."},
{"role": "user", "content": "안녕하세요!"},
]
response = ollama.chat(model=model_name, messages=messages)
print("Bot:", response.message.content)
while True:
user_input = input("You: ")
if not user_input:
break
messages.append({"role": "user", "content": user_input})
response = ollama.chat(model=model_name, messages=messages)
answer = response.message.content
print("Bot:", answer)
messages.append({"role": "assistant", "content": answer})Run python file
$ python chatSLM.py🤖 대화 예시
Bot: 안녕하세요! 👋 어떻게 도와드릴까요? 무엇이 궁금하신가요? 😄
You: 안녕! 반가워
Bot: 안녕하세요! 👋 환영합니다! 무엇을 도와드릴까요? 😊
어떤 주제에 대해 이야기하고 싶으신가요? 🗣️
You: 스콜이 뭐야?
Bot: "스콜"이라는 용어가 문맥에 따라 조금 다를 수 있지만,
주로 두 가지 의미로 이해될 수 있습니다:
1. **동물**: 스콜은 아프리카와 아시아 일부 지역에 서식하는
작은 포식자 동물로, 종종 "작은 고양이"라고 불리며
정확한 학명은 _Felis serval_입니다.
2. **언어/속어**: 특정 지역에서 쓰이는 속어나 별칭일 수도 있습니다.
구체적인 맥락이 있다면 더 정확히 설명해 드릴 수 있어요.
You: 비 엄청 오는 것도 스콜 아닌가?
Bot: 맞아요! 🌧️ "스콜"은 특히 **짧고 강렬한 집중 호우**를 가리키는 말로도 자주 사용됩니다.
아프리카 열대 기후에서 흔히 볼 수 있는 현상으로,
갑자기 시작되어 몇 분에서 몇 시간 동안 굉장히 세게 쏟아지다가
급작스럽게 멈추는 특성을 가지고 있습니다.
이런 특징적인 날씨 현상을 설명할 때 "스콜"이라는 단어가 쓰입니다! 👍실전 활용 2: 문서 자동 요약
코드:
import ollama
text = '''
Ollama는 대규모 언어 모델(LLM)을 로컬에서 직접 실행할 수 있도록 도와주는 오픈소스 도구입니다.
이를 통해 사용자는 인터넷 연결 없이도 고성능 언어 모델을 실행할 수 있으며,
외부 API 호출 없이 텍스트 생성, 문서 요약, 질문 응답 등의 다양한 자연어 처리(NLP) 작업을 수행할 수 있습니다.
특히, 민감한 데이터를 다루는 환경에서는 데이터 프라이버시를 보장할 수 있고,
클라우드 기반 요금 부담 없이 자원의 효율적 사용이 가능해 비용 절감에도 큰 도움이 됩니다.
Ollama는 다양한 오픈소스 모델을 지원하며, 명령줄 인터페이스(CLI) 및 Python SDK를 통해 손쉽게 통합할 수 있습니다.
'''
prompt = f"""
다음 텍스트를 한 문장으로 요약해 주세요:
\"\"\"\n{text}\n\"\"\"
"""
result = ollama.generate(model='exaone3.5:7.8b', prompt=prompt)
print("Summary:", result['response'])출력:
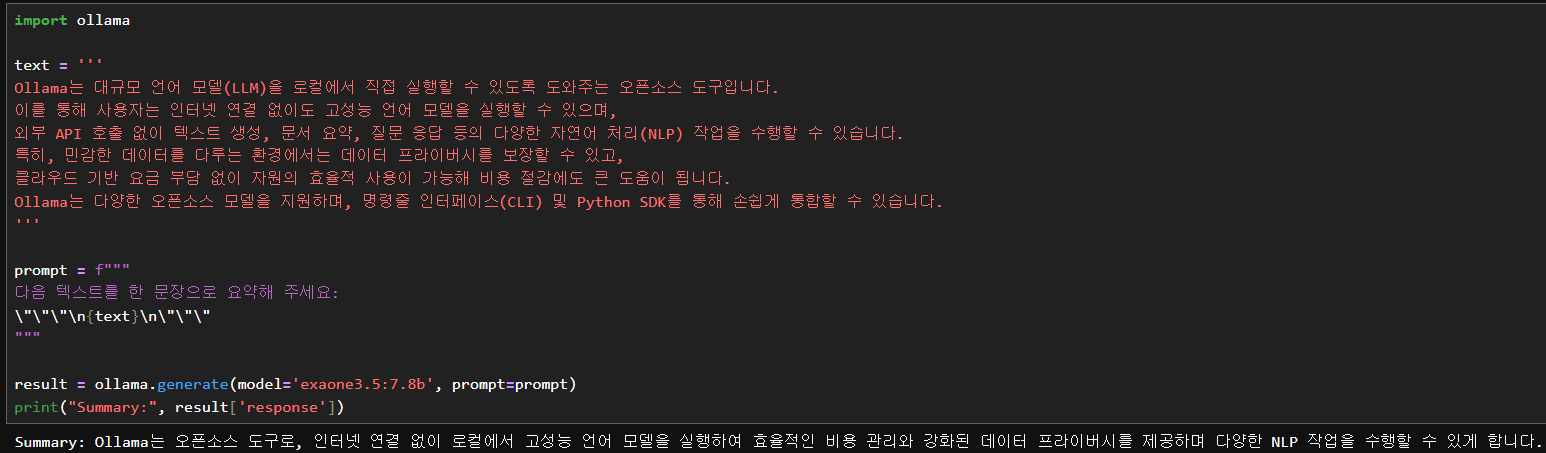
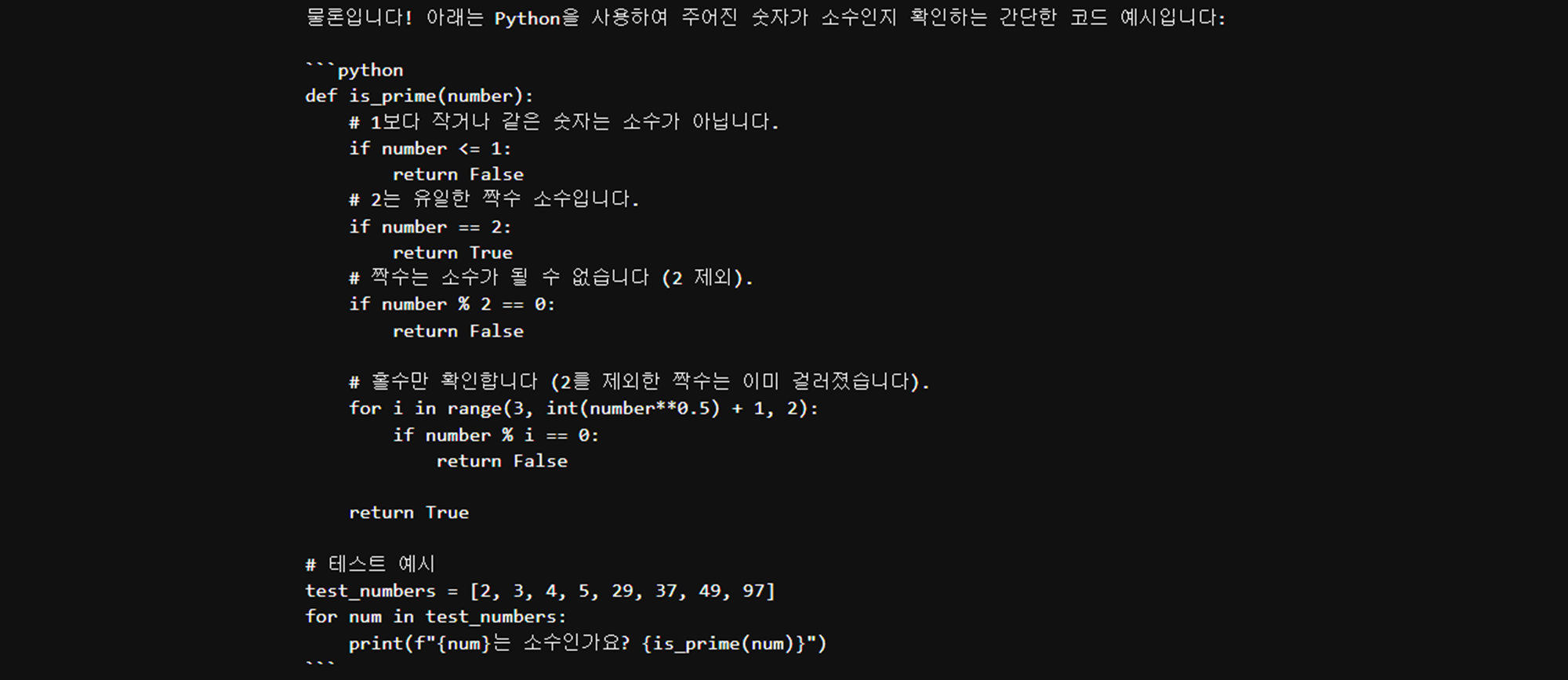
실전 활용 3: 코드 요청하기
코드:
import ollama
code_prompt = "숫자가 소수(Prime Number)인지 확인하는 코드 작성해줘"
response = ollama.generate(model='exaone3.5:7.8b', prompt=code_prompt)
print(response['response'])출력:
실전 활용 4: 함수 호출 기반 AI 에이전트 만들기
1. 툴 함수 정의 (계산 기능 예시)
def add_two_numbers(a: int, b: int) -> int:
"""두 숫자를 더해 반환합니다."""
return a + b2. 시스템 메시지 + 사용자 질문 입력
system_message = {
"role": "system",
"content": "당신은 수학 계산을 도와주는 AI입니다. 필요시 'add_two_numbers' 함수를 호출해 계산하세요."
}
user_message = {
"role": "user",
"content": "10 + 10은 얼마인가요?"
}
messages = [system_message, user_message]3. 모델 실행 및 툴 호출 처리
model='exaone3.5:7.8b'
response = ollama.chat(
model=model,
messages=messages,
tools=[add_two_numbers]
)
if response.message.tool_calls:
for tool_call in response.message.tool_calls:
func_name = tool_call.function.name
args = tool_call.function.arguments
if func_name == "add_two_numbers":
result = add_two_numbers(**args)
print("Function output:", result)
messages.append({"role": "assistant", "content": f"The result is {result}."})
follow_up = ollama.chat(model=model, messages=messages)
print("Assistant (final):", follow_up.message.content)어? 안되는데요?
=> 네 맞습니다! tool을 사용할 수 있는 모델은 제한적인데요 😎

Ollama에 올라와 있는 엑사원 모델은 tool을 지원하고 있지 않습니다:
Ollama에 올라온 모델 중 tool을 지원하는 모델은 대표적으로 llama 모델이 있죠!
import ollama
model_name = 'llama3.1:8b'
response = ollama.chat(
model= model_name,
messages=messages,
tools=[add_two_numbers]
)
if response.message.tool_calls:
for tool_call in response.message.tool_calls:
func_name = tool_call.function.name
args = tool_call.function.arguments
if func_name == "add_two_numbers":
result = add_two_numbers(**args)
print("Function output:", result)
messages.append({"role": "assistant", "content": f"The result is {result}."})
follow_up = ollama.chat(model=model_name, messages=messages)
print("Assistant (final):", follow_up.message.content)llama3.1:8b를 사용해서 실행하면 함수가 제대로 실행되는 것을 확인할 수 있습니다.
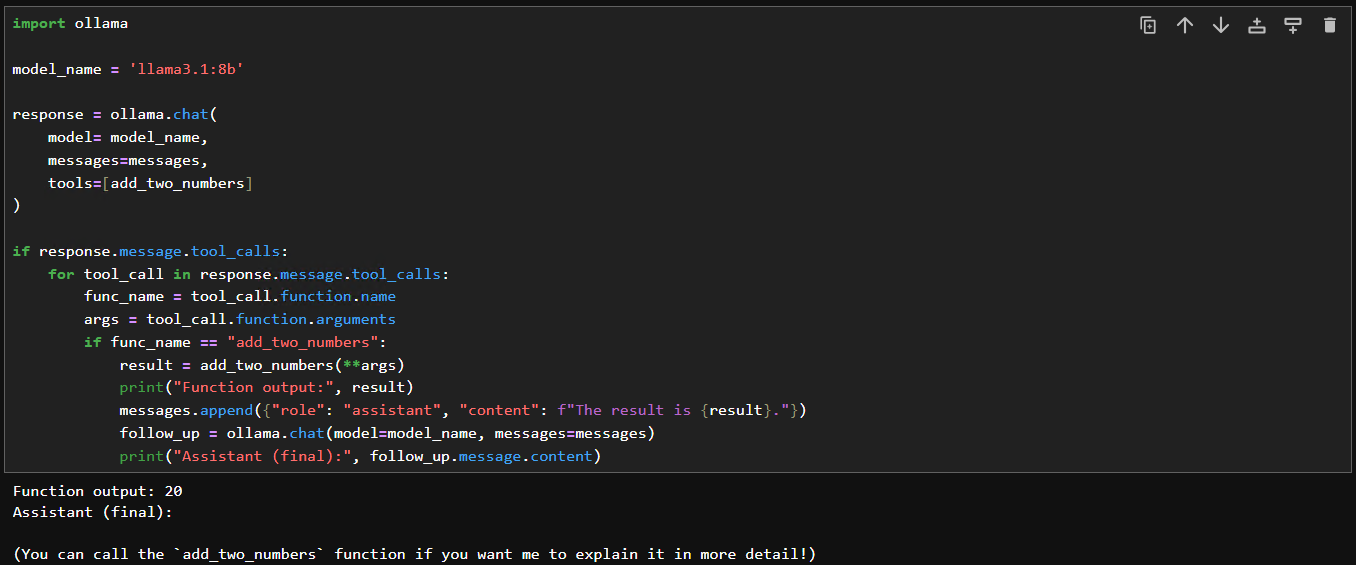
(참고) 🧠 작동 방식: Function Calling의 흐름
-
모델은 함수 호출을 “요청”합니다.
- 프롬프트나 대화 흐름을 통해 함수 이름과 파라미터를 JSON 형식으로 반환합니다.
- 예:
{"function": "add_two_numbers", "arguments": {"a": 10, "b": 10}}
-
Ollama SDK는 이 요청을
tool_calls형태로 포착합니다.response.message.tool_calls로 접근 가능- 이 단계에서는 모델은 단지 호출 “제안”을 한 상태입니다.
-
개발자(Python 코드)가 해당 요청을 파싱하여 실제 Python 함수 호출
- 예:
add_two_numbers(**tool_call.function.arguments)
- 예:
-
결과를 다시 LLM에 넘기고 후속 응답 생성
- 다시
ollama.chat()을 호출하여The result is 20.같은 후속 발화를 생성하게 합니다.
- 다시
(참고) 🔄 시퀀스 도식
도구 호출을 도식화해보면 다음과 같이 그릴 수 있습니다:
[User Message] ──▶ [LLM: I want to call add_two_numbers(10, 10)]
│
▼
[SDK detects tool_call]
│
▼
[Python code executes add_two_numbers(10, 10)]
│
▼
[Result (20) is inserted into conversation history]
│
▼
[LLM generates follow-up: "The result is 20."]마무리
이 글에서는 LLM 기반 애플리케이션을 빠른 건설으로 가능하게 해주는 Ollama의 헌신 기능과 Python 연동 방법을 살펴보였습니다. 특히 exaone3.5:7.8b와 같은 국사 LLM을 사용할 경우, 한국어 회신 성능을 높이며 더는 강한 프라이버시와 반성 속도를 확립할 수 있습니다.
마지막으로 Ollama 주요 API 및 Python 함수를 정리하고, 이번 포스트를 마무리해보겠습니다!! 💖
Ollama 주요 API 및 Python 함수 정보
🔢 1. 모델 생성 및 테스트 생성 (Text Generation)
-
/api/generate: 제공된 프롬프트에 기반하여 텍스트를 생성 -
주요 파라미터:
model: 사용할 모델 이름 (예:llama3,gemma)prompt: 입력 텍스트stream: 스트리밍 응답 여부 (기본값:true)options:temperature,top_k,top_p등 설정
-
/api/chat: 대화형 응답 생성 (문맥 유지용)model,messages,stream등 사용
📦 2. 모델 목록 및 정보 조회 (Model Info)
/api/tags또는/api/ps: 다운로드된 모델 목록 (docker ps 느낌)/api/show: 특정 모델 정보 (파라미터, 라이선스 등)
📥 3. 모델 다운로드 및 관리
-
/api/pull: 모델 다운로드name,stream,insecure등 설정
-
/api/push: 로컬 모델 업로드 (커스텀 공유 시) -
/api/copy: 로컬 모델 복사 -
/api/delete: 로컬 모델 삭제
🧠 4. 임베딩 생성 (Embeddings)
-
/api/embeddings: 입력 텍스트 임베딩 벡터 생성- 검색, 유사도 비교, 군집화 등에 활용
- 주요 파라미터:
model,prompt,options
🐍 주요 Python 함수 매핑
ollama.list()→/api/tags또는/api/ps(모델 목록)ollama.show(name)→/api/showollama.pull(name, stream=False)→/api/pullollama.generate(model, prompt, stream=False)→/api/generateollama.chat(model, messages, stream=False)→/api/chatollama.embeddings(model, prompt)→/api/embeddingsollama.ps()→/api/ps(실행 중 모델 확인)ollama.delete(name)→/api/deleteollama.copy(source, destination)→/api/copy
이 요약을 참고하여 Ollama SDK를 더 깊이 활용해 보세요!
읽어주셔서 감사합니다 🐶
