https://arxiv.org/pdf/2407.11384v2
The AAAI 2025 Workshop on Advancing LLM-Based Multi-Agent Collaboration (WMAC)
Introduction
Supply chain management (SCM)은 공급업체에서 소비자까지 다양한 상호 연결된 주체 간의 상품, 정보 및 자금 흐름을 조정하고 관리하여 제품을 효율적이고 효과적으로 전달하는것을 포함.
재고 관리에 대한 이전 연구에서는 다양한 휴리스틱 방법과, 분산 재고 관리 및 적응형 공급망 동기화를 포함하여 강화 학습 모델에 관한 것들이 수행되었으며, 최근 연구에서는 공급망 연구에서 LLMs를 활용하기 시작하였음.
본 연구에서는 LLMs를 활용하는 발전된 zero-shot multi-agent 재고 관리 시스템인 InvAgent를 제안함.
본 연구의 기여는 아래와 같음.
- LLM을 zero-shot learners로서 multi-agent inventory system을 관리하여 사전 학습이나 특정 예제 없이 적응적이고 정보에 입각한 의사 결정을 가능하게 함.
- InvAgent는 Chain-of-thought (CoT)에 의해 향상된 설명 가능성과 명확성을 제공하여 이해하고 신뢰하기 쉽고, 기존의 휴리스틱 및 강화학습 모델에 비해 안정적인 성능을 보임.
- InvAgent는 다양한 수요 시나리오에 동적으로 적응하여 비용을 최소화하고 품절을 방지하며, 다양한 시나리오에 대한 광범위한 평가를 통해 공급망 관리 효율성을 입증하였음.
Related Work
LLM-Based Multi-Agent System Applications in Economics
- LLM 기반 Multi-Agent Systems (MASs)는 인간 행동을 모델링하기 위해 경제 및 금융 거래 시뮬레이션에 사용되었음. 이러한 에이전트는 협력적 환경과 분산 환경 모두에서 작동하며 경제 연구에서 다양한 응용 분야를 보여줌.
Multi-Agent System Applications in Supply Chain
기존 연구에서는 공급망 효율성과 대응성을 향상시키기 위한 MAS의 잠재력을 탐구하였음.
- Nissen (2001)은 에이전트 기반 기술을 사용한 공급망 통합을 조사하여 에이전트가 보다 효율적이고 대응적인 공급망 통합을 조사하여 에이전트가 보다 효율적이고 대응적인 공급망 운영을 어떻게 촉진할 수 있는지 강조
- Kaihara (2003)은 동적 환경에서 작동하는 공급망 모델링에서 MAS의 응용에 대해 논의하고 에이전트가 변화와 불확실성에 어떻게 적응할 수 있는지에 중점을 둠.
- Moyaux, Chaib-Draa, and D’Amours (2003)은 다중 에이전트 조정 메커니즘이 공급망에서 채찍 효과를 줄이는 데 어떻게 도움이 되는지 탐구하고, 에이전트 간의 협업 및 정보 공유를 향상시키기 위해 토큰 기반 접근 방식을 사용
Multi-Agent Reinforcement Learning Applications in Supply Chain
SCM을 위한 multi-agent 강화학습 연구는 여러 에이전트 간의 상호 작용 및 협력을 최적화하는 데 중점을 둠
- Oroojlooyjadid et al. (2022)는 맥주 유통 게임에서 강화학습을 위한 Shaped-Reward Deep Q-Network (SRDQN)를 제안하며, 여기서 에이전트는 보상과 처벌을 통해 행동을 최적화하여 성능을 향상시킴
- Hori and Matsui (2023)는 SRDQN에 적용된 메커니즘 설계를 기반으로 보상 형성 기술을 사용하여 맥주 게임에서 협력 정책을 개선하여 multi-agent 설정에서 성능을 향상시킴.
- OR-Gym은 SCM을 포함한 운영 연구 문제에서 휴리스틱 모델에 대한 강화학습 솔루션을 벤치마킹하는 오픈소스 라이브러리임.
Methodology
Problem Definition
시스템 구조
- 본 논문에서는 단일 non-perishable (비소모성) 제품에 대한 multi-period, multi-echelon 재고 시스템을 모델링함.
- 총 M개의 stage로 구성되며, 각 stage는 0부터 M-1까지 순서대로 번호가 매겨지고, 단계 0은 소매업체
- 각 단계는 inventory holding area와 production area로 이루어져 있음.
- Stage i에서 생산되는 제품은 i-1 stage의 생산에 필요한 재료로 사용됨. 즉, upstream은 downstream에 재료를 공급하는 구조
- Stage 간 제품의 이동에는 lead time ()이 존재
- 각 stage의 생산량은 해당 stage의 생산 능력과 사용 가능한 재고량에 의해 제한됨.
시뮬레이션 과정
각 시뮬레이션에는 T 기간이 있으며, 1부터 시작하여 t=0은 공급망의 초기 조건에 사용됨. 각 기간의 시작 부분에서 아래 이벤트 시퀀스 발생
- 납품 확인
- 각 stage는 해당 lead time이 지난 후 도착한 재고 보충 선적(inventory replenishment shipments)를 받음
- 주문 및 수요 확인
- 각 stage는 해당 공급업체에 보충 주문(replenishment orders)을 함. 주문은 공급업체의 가용 생산 능력과 재고에 따라 처리됨. 고객 수요는 stage 0 (소매업체)에서 발생하며, 소매업체의 가용재고에 따라 충족됨.
- 주문 및 수요 납품
- 각 stage는 하위 stage의 수요나 보충 주문을 충족시키기 위해 가능한 만큼 제품을 배송함. 충족되지 않은 판매 및 보충 주문은 backlog로 기록되며, 다음 기간에는 backlog된 판매 주문이 우선적으로 처리됨.
- 이익 계산
- 각 단계는 제품 판매, 재료 주문, backlog 페널티, 재고 유지 비용에 대한 이익과 비용을 계산함.
수학적 모델링
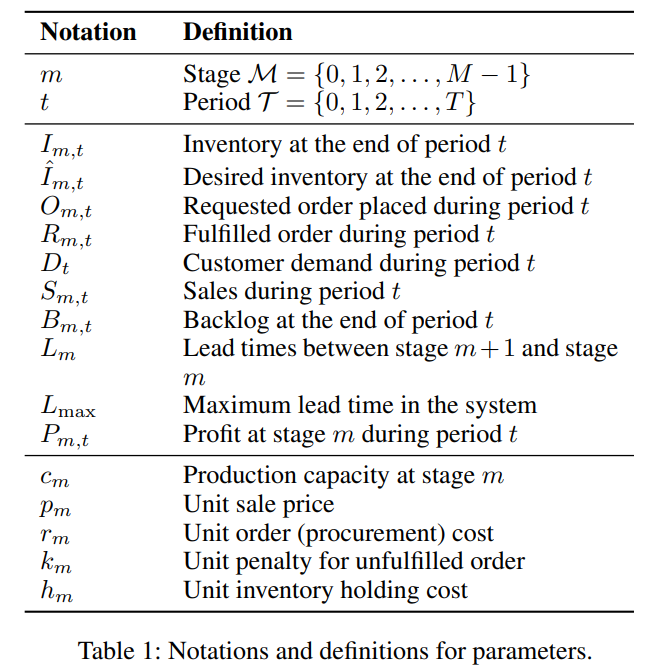
위 테이블에 정의된 notation에 따라 inventory management problem (IMP)는 아래와 같은 방정식으로 표현됨.
(1) 재고 변화
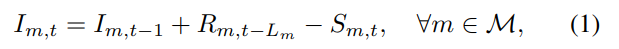
- 재고 변화로, 기간 t 말의 stage m의 현재 재고량 ()를 계산
- : 이전 기간인 t-1 말의 최종 재고량.
- : 기간 전에 주문되어 현재 기간 t에 도착한 충족된 주문량.
- : 현재 기간 t 동안의 판매량.
- 즉, 이전 재고에 도착한 주문량을 더하고 판매량을 빼서 현재 재고를 구함.
(2) 처리된 주문 (상위 stage 공급)
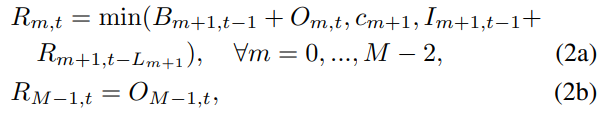
- (2a)는 stage m이 상위 단계 m+1에 주문한 양 중 기간 t에 충족된 양()을 계산 (최상위 단계 m-1 제외)
- 충족된 주문량은 다음 세 가지 조건 중 최솟값으로 결정
- : 상위 단계 m+1의 이전 기간 backlog()와, stage m이 새로 요청한 주문 ()의 합. 즉, 상위 stage가 처리해야 할 총 주문량.
- : 상위 stage m+1의 생산 능력. 상위 stage가 이 생산 능력 이상을 공급할 수 없음.
- : 기간 t 시작 시 상위 stage m+1의 총 가용 재고량(이전 기간 재고 + 해당 lead time 후 도착한 주문)
- (2b)는 최상위 stage m-1의 경우 요청한 주문()이 항상 충족된다고 가정(원자재 공급 무제한 가정)
(3) 판매량 (하위 stage 수요 충족)
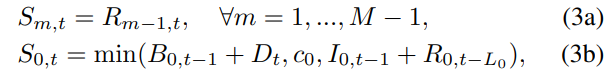
- 소매업체(stage 0)를 제외한 모든 stage의 판매량은 upstream stage m으로부터 받은 처리된 주문량()과 같음.
- 소매업체의 기간 t 판매량은 다음 세 가지 중 최솟값으로 결정
- 이전 기간의 backlog ()와 현재 고객 수요 ()의 합
- 소매업체(stage 0)의 생산 능력()
- 소매업체의 기간 t 시작 시점 총 가용 재고(이전 기간 재고 및 lead time 후 새로 도착한 처리된 주문 포함)
(4) Backlog
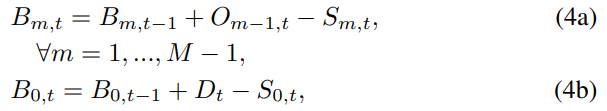
- 소매업체(stage 0)를 제외한 모든 stage에서 기간 t backlog는 이전 기간 backlog ()에 downstream stage m-1로부터 요청받은 주문량()을 더하고 해당 stage의 판매량 ()를 뺀 값임.
- 소매업체의 기간 t backlog ()는 이전 기간 backlog ()에 고객 수요()를 더하고 판매량()를 뺀 값
(5) 이익
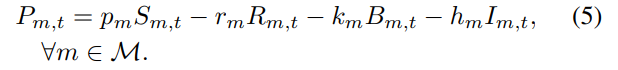
- 각 stage m의 기간 t 이익은 판매 수익()에서 조달 비용(), backlog 패널티(), 재고 유지 비용()를 뺀 값임.
InvAgent Model
시스템은 environment(환경)와 공급망 agents 사이의 중개자 역할을 하는 User Proxy와 공급망의 각 stage(소매업체, 도매업체 등)을 담당한 에이전트(LLM이 역할 수행)들인 Stage Agents로 구성됨.
InvAgent Model은 아래와 같이 작동함.
- 시뮬레이션 시작 시, user proxy가 환경을 초기화
- User proxy가 각 stage의 현재 상태 정보를 환경에 요청
- User proxy는 현재 상태 정보를 각 stage agent에게 제공하고, stage agent에게 다음 행동(주문량)을 요청
- User proxy는 모든 agent들의 행동을 환경으로 보내고, 다음 상태와 해당 stage에서의 보상(이익/비용)을 얻음.
- User proxy는 시뮬레이션이 종료되었는지 확인하고, 종료되지 않았으면 step2로 이동
Agent의 상태 와 액션 는 아래와 같이 정의.
- : stage m의 생산 능력
- : 단위 판매 가격
- : 단위 주문(조달) 비용
- : 미납 주문 단위 당 페널티
- : 재고 단위 당 보유 비용
- : stage m+1과 m 사이의 lead time
- : 이전 기간 t-1 종료 시점의 재고량
- : 이전 기간 t-1 종료 시점의 미납 주문량
- : 이전 기간 t-1 종료 시점의 upstream stage m+1의 미납 주문량
- : 최근 기간 동안의 판매량
- : 최근 기간 동안 도착한 주문량 (lead time 고려)
여기서 상태는 현재 stage 특징, 재고, backlog, upstream backlog, 최근 판매 및 왼쪽 0 패딩이 있는 도착 배송을 포함.
System Message
시뮬레이션 시작 시 agent에 대한 시스템 메시지를 생성하는데, 이는 공급망 정의, 역할 및 목표와 같은 필수 정보를 제공함.

Prompt
설계된 프롬프트는 각 agent에게 상태를 제공하고 액션을 요청하여 공급망 내에서 효과적인 의사결정과 명확한 커뮤니케이션을 보장하는 것을 목표로 하며 현재 기간, stage 및 공급망 내에서 모델의 위치를 지정하기 위한 stage 수와 같은 context 정보를 포함

State Description
State description은 재고 수준, backlog, 이전 판매 및 들어오는 배송에 대한 포괄적인 snapshot을 제공하여 정보에 입각한 결정을 내릴 수 있도록 함.

Demand Description, Downstream Order Description
Demand 및 downstream order description은 공급을 즉각적인 요구와 일치시키는 데 도움이 되어 upstream 공급업체가 downstream order 또는 demand에 신속하게 대응할 수 있도록 함.


Strategy Description
Strategy description은 lead time을 고려하고 재고 균형을 유지하기 위해 과도한 주문을 피하는 것과 같은 지침을 간략하게 설명함. 액션을 지정하기 전에 추론을 요청함으로써 프롬프트는 의사 결정의 투명성과 해석 가능성을 촉진. 해당 설계는 LLM의 기능을 활용하여 재고 관리를 개선하고 결정이 정보에 입각하고 투명하며 공급망 전략에 부합하도록 보장함.

아래는 그렇게 6가지 정보를 포함하는 User proxy와 retailer agent의 대화 내용의 예시이다.

프롬프트 디자인의 특징은 다음과 같다.
- Zero-shot Learning: 저자들이 디자인한 프롬프트는 zero-shot 방식으로 작동하여 LLM이 사전 지식과 프롬프트에 제시된 정보만을 기반으로 응답을 생성하도록 요구함.
- Demand Description: 사전 학습 과정이 없으므로 정확한 이해와 효과적인 응답을 보장하려면 수요에 대한 명확하고 자세한 설명을 제공하는 것이 중요
- Downstream Order: 프롬프트는 downstream 주문을 고려하여 신속한 정보 전달과 다양한 stage 간의 효율적인 공유를 가능하게 함.
- Human-crafted Strategy: LLM의 고유한 전략을 일반적으로 간단한 시나리오에 충분하지만 계절적 수요와 같은 더 복잡한 시나리오에서는 추가적인 human-crafted 전략이 의사 결정을 향상시키는 것으로 가정됨.
- Chain-of-Thought (CoT): CoT는 LLM이 구조화된 추론 과정을 통해 LLM을 안내하여 결과의 설명 가능성을 향상시키고, LLM의 이해 및 추론 능력을 향상시키며, 더 정확하고 신뢰할 수 있는 결과를 도출함.
→ Retailer agent의 응답을 보면, 현재 재고가 최대 수요의 최대 3라운드와 2라운드 lead time에 충분하다고 판단하여 과도한 재고를 방지하기 위해 이번 라운드에서는 주문을 하지 않기로 결정하였음.
Experiment
Experiment Scenarios
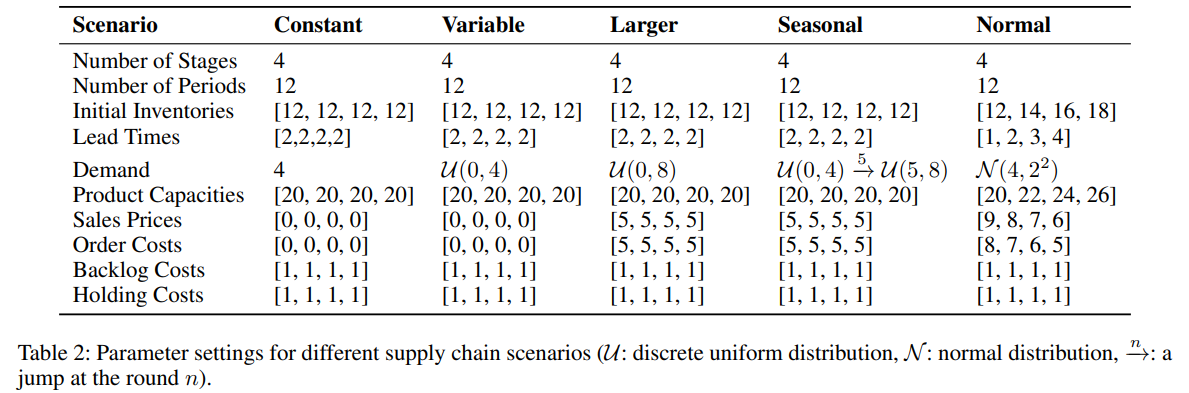
실험 시나리오는 아래와 같이 다단계 공급망에서 재고 관리 시스템의 성능을 평가하기 위해, 고정 수요가 있는 4단계 공급망에서부터 수요 변동성 증가, 계절적 패턴 및 정규 분포 수요가 있는 시나리오까지 다양하게 설정. 각 시나리오는 변동하는 수요, 재정적 영향 및 다양한 운영 제약 조건과 같은 특정 조건을 도입하여 제안된 모델의 견고성과 적응성을 엄격하게 테스트함. 이러한 포괄적인 시나리오는 다단계 공급망에서 동적 재고를 관리하는 데 있어 multi-agent 시스템의 효능 및 적응성을 평가하기 위한 철저한 테스트 베드를 제공함.
Experiment Baselines
실험의 베이스라인은 총 네가지로, 이는 두가지 휴리스틱 정책과 두가지 강화학습 정책을 포함. 휴리스틱 baseline은 고객 수요 또는 downstream order를 충족하기에 충분한 재고 수준을 유지하도록 설계되었음.
Experiment Settings
InvAgent의 성능은 한 번의 시뮬레이션동안 모든 stage의 모든 기간에서 얻은 총 보상을 사용하여 평가되며, 불확실성을 줄이기 위해 각 실험에 대해 5개의 episode에 걸쳐 보고된 숫자를 평균함. Baseline 모델의 성능은 100개의 episode에 걸쳐 평균된 보상을 기준으로 평가.
Experiment Results
InvAgent 모델은 variable scenario에서 특히 경쟁력 있는 성능을 보여주며, 다른 대부분의 시나리오에서는 MAPPO 모델이 최고의 성능을 보이지만, InvAgent의 zero-shot 기능과 적응성은 상당한 이점을 제공함. 이러한 적응성을 통해 InvAgent는 특정 예시 없이도 합리적인 결정을 내리고 개념을 이해할 수 있어 인간의 직관과 유사한 수준의 일반화 및 적응성을 보여줌.
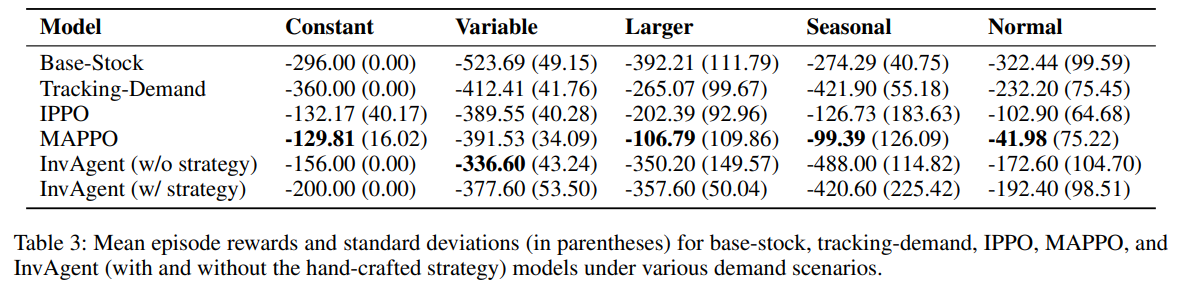
- 휴리스틱 baseline과 비교하여 InvAgent는 실시간 조건에 동적으로 적응하여 재고 비용을 최소화하고 품절을 방지함으로써 상당한 이점을 보여줌.
- MAPPO나 IPPO같은 강화학습 모델은 광범위한 훈련으로 인해 일부 시나리오에서 더 높은 메트릭을 달성하지만 복잡성 증가, 잠재적 불안정성 및 상당한 계산 요구 사항도 함께 제공됨. 이에 대조적으로 InvAgent는 사전 훈련 없이도 설명 가능성, 구현 용이성, 안정성 및 합리적인 의사 결정에 강점을 가지며, 항상 강화학습 모델보다 성능이 뛰어나지는 않더라도 동적 재고 관리를 위한 가치 있는 대안이 됨.
Ablation Studies
InvAgent 모델에서 prompt를 구성하는 다양한 요소들(demand description, downstream order description, strategy description, CoT 사용 여부, 이전 대화 기록 유지 여부(history))이 모델의 성능에 각각 어떤 영향을 미치는지, 그리고 어떤 LLM 모델이 가장 적합한지 탐색하였음. 다양한 시나리오 중 variable 시나리오를 선택하여 진행함. strategy만 제외한 GPT-4 모델을 베이스라인으로 설정하고 성능 하락 결과를 보았음.
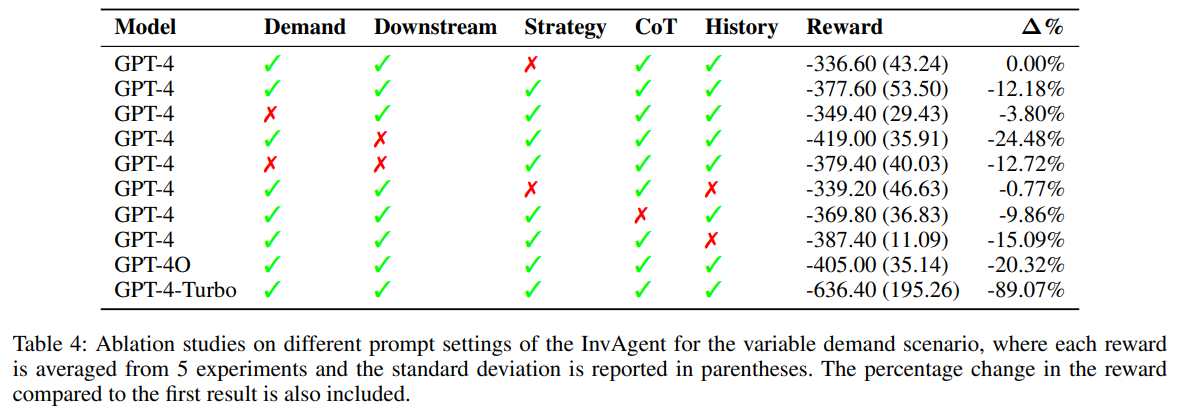
- Strategy description을 포함했을 때 성능이 베이스라인보다 낮아졌으며, 이는 variable demand 시나리오의 경우 prompt에 명시된 human crafted strategy가 LLM 자체의 추론 능력만 사용하는 것보다 덜효과적이었음을 보여줌. 하지만 Seasonal demand같은 다른 복잡한 시나리오에서는 strategy가 도움이 될 수도 있음.
- Downstream order description을 제거했을 때 성능이 가장 크게 감소하였음. 이는 공급망 내에서 downstream의 주문 정보를 upstream에게 빠르게 전달하는 것이 전체 시스템 성능에 매우 중요함을 보여줌.
- Demand description을 제거했을 때 성능이 약간 감소한 것으로 보아, variable demand 환경에서 수요 정보를 명확히 제공하는 것이 중요하긴 하지만, 치명적인 영향은 아님.
- CoT를 사용하지 않았을 때 성능이 감소한 것으로 보아, LLM이 의사결정 전 추론 과정을 거치도록 유도하는 것이 더 나은 결과를 도출하는 데 도움이 됨을 시사함.
- 이전 대화 기록을 유지하지 않았을 때 성능이 감소한 것으로 보아, agent가 과거의 상호작용 맥락을 기억하는 것이 현재 의사 결정에 긍정적인 영향을 미침을 보여줌.
- GPT-4가 아닌 다른 모델을 사용하였을 때 모두 성능이 낮게 나타남. 이는 동일한 프롬프트 설정이더라도 어떤 LLM 모델을 사용하느냐에 따라 결과가 크게 달라질 수 있음을 보여줌.
Conclusion
- 본 논문은 LLM을 multi-agent system 내의 자율 agent로 활용하여 공급망 재고 관리를 최적화하는 것의 효과를 성공적으로 보여주었음.
- 제안된 모델인 InvAgent는 LLM의 zero-shot learning 능력을 활용하여, 사전에 별도의 훈련 없이도 환경 변화에 적응적이고 정보에 기반한 의사결정을 내릴 수 있음. 또한, CoT 방법론을 통합함으로써 모델의 설명 가능성과 투명성을 높여 기존의 휴리스틱이나 강화학습 모델보다 더 신뢰할 수 있게 함.
- 다양한 수요 시나리오에 걸친 실험 결과로 경쟁력 있는 성능을 보여주며, 특히 비용 절감 및 품절 최소화 측면에서 효율적임을 입증함.
- 향후 연구 방향으로는 InvAgent 모델을 강화학습 기법과 결합하여 fine-tuning 함으로써 의사결정 능력을 더욱 향상시키고, 실제 공급망 데이터를 사용하여 모델의 효율성과 유용성을 평가하고자 함. 또한, 계절성 데이터 처리를 위한 분석 기법 탐색 및 인간 전문가의 전략과 LLM 능력을 더욱 효과적으로 결합하는 연구를 진행하고자 함.

유익한 글 잘 봤습니다.
사실 유익하진 않았습니다.
솔직히 말하자면 잘 보진 않았습니다.
더 솔직해지자면 보지도 않았습니다.
감사합니다.