
AI
Vision Transformer(ViT)[1]
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE_Alexey Dosovitskiy, et al

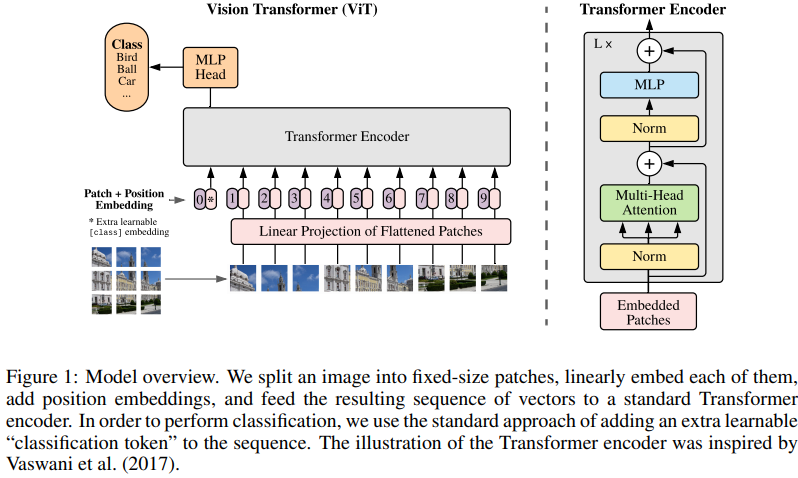
Transformer는 NLP의 기준이 되었고, vision에 적용하는 데는 한계가 있었다. Attention 메커니즘은 Convolutional networks와 연결하거나 특정 요소를 대체하면서 구조를 유지했다. 이 논문에서는 CNN에 의존하지 않고, 순수한 Transformer를 직접 적용하면서 이미지를 잘 분류할 수 있고, 상당히 적은 리소스를 활용하는 것이 contribution이다.
Reference
[1] Alexey Dosovitskiy, et al, An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR, 2021.
[2] Ilya Tolstikhin, et al, MLP-Mixer: An all-MLP Architecture for Vision, CVPR, 2021.
[3] Andreas Steiner, et al, How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers, CVPR, 2022.
[4] Xiangning Chen, et al, When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations, CVPR, 2022.
[5] Xiaohua Zhai, et al, LiT: Zero-Shot Transfer with Locked-image text Tuning, CVPR, 2022.
[6] Juntang Zhuang, Surrogate Gap Minimization Improves Sharpness-Aware Training, ICLR, 2022.
