[SQLD] 2024 노랭이 개정판 :: 데이터 모델과 SQL 오답노트
34. 속성(a,b,c,d,e)로 구성된 릴레이션에서 아래와 같은 함수 종속성이 존재할 때, 이 릴레이션의 후보 키로 가장 적절하지 않은 것은?
ab -> cde, e -> b, d -> ab
① d
② ab
③ ac
④ ae
36. 아래 엔터티에 필요한 정규화와 분리된 스키마 구조로 가장 적절한 것은?
[보관금원장]
관서번호
납부자번호
.............................
관리점번호
관서명
상태
관서등록일자
직급명
통신번호
함수종속성(FD) :
{관서번호, 납부자번호} -> {직급명, 통신번호}
{관서번호} -> {관리점번호, 관서명, 상태, 관서등록일자}
③ 2차 정규화 - 정규화테이블{관서번호, 관리점번호, 관서명, 상태, 관서등록일자}
-> 관리점 번호는 관서 번호와 연관성이 없으니 별도 엔터티로 분류해도 된다.
38. 아래와 같이 전제조건이 있을 때 테이블에서 나타날 수 있는 현상으로 가장 적절한 것은?
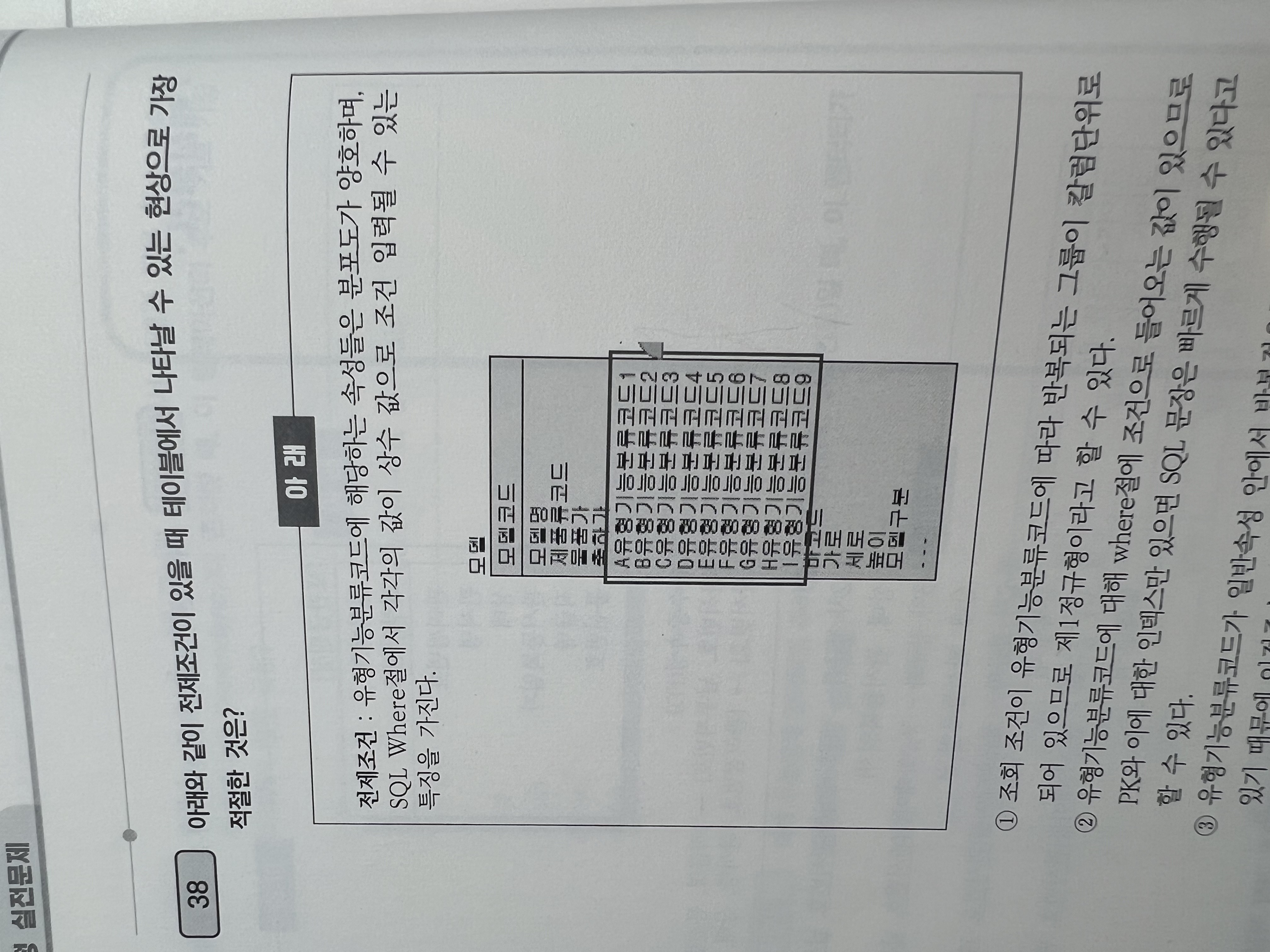
① 조회 조건이 유형기능분류코드에 따라 반복되는 그룹이 칼럼단위로 되어 있으므로 제1정규형이라고 할 수 있다.
-> 칼럼에 의한 반복적인 속성값을 갖는 형태는 속성의 원자성을 위배한 1차 정규화의 대상이 된다.
② 유형기능분류코드에 대해 where절에 조건으로 들어오는 값이 있으므로 PK와 이에 대한 인덱스만 있으면 SQL문장은 빠르게 수행될 수 있다고 할 수 있다.
-> 반복적인 속성 나열 형태에서는 각 속성에 대해 'or' 연산자로 연결된 조건들이 사용된다. 어느 하나의 속성이라도 인덱스가 설정되어 있지 않으면 모든 조건절들이 전체 데이터 스캔으로 처리되기 때문에 성능 저하가 나타날 수 있다.
③ 유형기능분류코드가 일반속성 안에서 반복적으로 속성이 구분되어 있기 때문에 이전종속을 수행해야 하는 제2정규형이라 할 수 있다.
④ 조회 성능을 위해 유형기능분류코드 각각에 대하여 개별로 인덱스를 모두 생성할 경우 입력, 수정, 삭제 때 성능이 저하되므로 제1차 정규화를 수행한 후 인덱스를 적용하는 것이 좋다.
39. 아래 논리 데이터 모델을 3차 정규화까지 수행했을 때 도출되는 엔터티 수로 가장 적절한 것은?

③ 7
-> 학과, 학생, 교수, LAB실 이용신청, (도서)대출, 대출도서, 도서 총 7개
40. 아래에서 빈칸 ㉠, ㉡에 들어갈 용어로 가장 적절한 것은?
어떤 릴레이션 R이 ㉠이고, 기본키에 속하지 않은 속성 모두가 기본키에 이행적 함수종속이 아닐 때 ㉡에 속한다.
③ ㉠ 제2정규형, ㉡ 제3정규형
41. 데이터 모델링의 정규화에 대한 설명으로 가장 적절하지 않은 것은?
① 정규화는 개념 데이터 모델의 일관성을 확보하고 중복을 제거하여 속성들이 가장 적절한 엔터티에 배치되도록 한다.
-> 정규화는 논리 데이터 모델 상세화 과정의 대표적인 활동으로, 논리 데이터 모델의 일관성을 확보하고 중복을 제거하여 속성들이 가장 적절한 엔터티에 배치되도록 함으로써 보다 더 신뢰성 있는 데이터구조를 얻는 데 목적이 있다.
② 제1정규형은 모든 인스턴스가 반드시 하나의 값을 가져야 함을 의미한다.
③ 제3정규형을 만족하는 엔터티의 일반속성은 주식별자 전체에 종속적이다.
④ 반정규화는 성능을 위해 데이터 중복을 허용하는 것이지만 성능의 향상을 항상 보장하는 것은 아니다.
42. 관계와 조인에 대한 설명으로 가장 적절하지 않은 것은?
① 조인이란 식별자를 상속하고, 상속된 속성을 매핑키로 활용하여 데이터를 결합하는 것을 의미한다.
② 부모의 식별자를 자식의 일반속성으로 상속하면 식별 관계, 부모의 식별자를 자신의 식별자에 포함하면 비식별 관계라고 할 수 있다.
-> 부모의 식별자를 자식의 식별자에 포함하면 식별관계, 부모의 식별자를 자식의 일반속성으로 상속하면 비식별관계라고 할 수 있다.
③ 관계를 맺는다는 것은 식별자를 상속시키고 해당 식별자를 매핑키로 활용해 데이터를 결합해 보겠다는 것을 의미한다.
④ "SELECT B.고객명 FROM 주문 A, 고객 B WHERE A.고객번호 = B.고객번호" 쿼리에서 조인키는 "고객번호"이다.
44. 아래와 같이 수강지도 엔터티를 만들었을 때 이에 해당하는 정규형과 정규화의 대상으로 가장 적절한 것은?
[수강지도]
학번
과목코드
...................
성적
지도교수명
학과명
[함수종속성(FD)]
1. 학번 || 과목코드 -> 성적
2. 학번 -> 지도교수명
3. 학번 -> 학과명
① 1차 정규형, 2차 정규화 대상
-> PK에 대해 반복이 되는 그룹이 존재하지 않으므로 1차 정규형이라고 할 수 있다.
부분함수종속의 규칙을 가지고 있으므로 2차 정규형이라고 할 수 없음.
2차 정규화의 대상이 되는 엔터티이다.
49. NULL 값에 대한 설명으로 가장 적절한 것은?
개발자로서 이걸 틀리다니...
① NULL 값에 어떤 숫자를 더해도 결과는 항상 NULL 이다.
② NULL 값과 어떤 숫자의 크기를 비교해도 결과는 항상 NULL 이다.
-> NULL 값과 어떤 숫자의 크기를 비교한 결과는 항상 unknown이다.
③ "NULL = NULL" 연산의 결과는 TRUE 이다.
-> "NULL = NULL" 연산의 결과는 FALSE 또는 unknown이다.
④ 집계 함수를 계산할 때 NULL 값은 0으로 처리된다.
-> 집계 함수를 계산할 때 NULL 값은 0이 아니라 계산에서 제외된다.
추가로 아래 사항을 기억하자.
컬럼이 총 14개이고 NULL인 컬럼이 4개 있을 때,
AVG(컬럼) = 10개 컬럼의 평균값
SUM(컬럼)/COUNT(*) = 14개 컬럼의 평균값-> 상황에 따라 집계 함수를 다르게 사용할 줄 알아야함
