
26. 아래 SQL을 순서대로 실행했을 때 최종적으로 반영되는 SQL을 모두 고른 것은?
(가) INSERT INTO emp (empno, ename, deptno) VALUES (999, 'Smith', 10);
SAVEPOINT a;
(나) DELETE emp WHERE empno = 202;
SAVEPOINT b;
(다) UPDATE emp SET ename = 'Clark'
ROLLBACK TO SAVEPOINT a;
(라) INSERT INTO emp (empno, ename, deptno) VALUES (300, 'Thomas', 30);
SAVEPOINT c;
(마) DELETE emp WHERE deptno = 20;
COMMIT;
④ (가), (라), (마)
-> (다)에서 SAVEPOINT A 이후의 모든 트랜잭션을 롤백했기 때문에, (나), (다) 트랜잭션은 모두 취소된다.
27. 아래 SQL의 실행 결과로 가장 적절한 것은?
[TABLE_A]
| TABKEY | COLA | COLB | COLC |
|---|---|---|---|
| 1 | NULL | 가 | NULL |
| 2 | 1 | 가 | 5 |
| 3 | NULL | 나 | 2 |
| 4 | 3 | 나 | 0 |
| 5 | NULL | NULL | 3 |
| 6 | 5 | 다 | 0 |
| 7 | NULL | 다 | NULL |
[SQL]
SELECT COLB
, MAX(COLA) AS COLA1
, MIN(COLA) AS COLA2
, SUM(COLA + COLC) AS SUMAC
FROM TABLE_A
GROUP BY COLB;| TABKEY | COLA | COLB | COLC |
|---|---|---|---|
| 1 | NULL | 가 | NULL |
| 2 | 1 | 가 | 5 |
| 3 | NULL | 나 | 2 |
| 4 | 3 | 나 | 0 |
-> GROUP BY 절은 NULL 데이터도 집계에 포함하기 때문에 colb 컬럼에 있는 NULL 행도 결과로 출력된다.
MIN, MAX 함수는 NULL 칼럼의 값이 NULL이 아닌 행 중에서의 최소, 최댓값을 추출한다.
NULL과의 사칙연산(+, -, *, /)은 결과가 NULL이므로 cola 또는 colb 둘 중 하나 칼럼의 값이 NULL이라면 NULL을 반환한다.
28. 아래 SQL의 실행 결과로 가장 적절한 것은?
[TBL]
| ID |
|---|
| 100 |
| 100 |
| 200 |
| 200 |
| 200 |
| 999 |
| 999 |
SELECT ID FROM TBL
GROUP BY ID
HAVING COUNT(*) = 2
ORDER BY (CASE WHEN IN = 999 THEN 0 ELSE ID END)| ID |
|---|
| 999 |
| 100 |
29. 오류가 발생하는 SQL은?
① SELECT 지역, SUM(매출금액) AS 매출금액
FROM 지역별매출
GROUP BY 지역
ORDER BY 매출금액 DESC;
② SELECT 지역, 매출금액
FROM 지역별매출
ORDER BY 년 ASC;
-> SQL 실행 순서에 의하면 SELECT절 이후에 ORDER BY 절이 수행되기 때문에 SELECT 절에 기술되지 않는 '년' 칼럼으로 정렬하는 것은 논리적으로 맞지 않다. 하지만 오라클은 행기반 DATABASE이므로 데이터를 엑세스할 때 행 전체 칼럼을 메모리에 로드한다. 이와 같은 특성으로 인해 SELECT 절에 기술되지 않은 칼럼으로 정렬을 할 수 있다. 단 아래와 같은 SQL일 경우에는 정렬을 할 수 없다.
SELECT 지역, 매출금액 FROM ( select 지역, 매출금액 from 지역별매출) ORDER BY 년 ASC;
③ SELECT 지역, SUM(매출금액) AS 매출금액
FROM 지역별매출
GROUP BY 지역
ORDER BY 년 DESC;
-> GROUP BY를 사용할 경우 GROUP BY 표현식이 아닌 값은 기술될 수 없다.
④ SELECT 지역, SUM(매출금액) AS 매출금액
FROM 지역별매출
GROUP BY 지역
HAVING SUM(매출금액) > 1000
ORDER BY COUNT(*) ASC;
-> GROUP BY 표현식이기에 가능하다.
30. 아래 SQL의 실행 결과로 가장 적절한 것은?
SELECT TO_CHAR(TO_DATE('2019.02.25', 'YYYY.MM.DD') + 1/12/(60/30), 'YYYY.MM.DD HH24:MI:SS) FROM DUAL;
③ 2019.02.25 01:00:00
->1/12/(60/30) 은, 하루(24시간)을 12시간으로 나누면 2시간이고, (60/30)은 2니까 2시간을 2로 나누면 1시간이다. 2019.02.25 00시 00분 00초에 1시간을 더하면 3번이 된다.
31. 실행 결과가 NULL인 SQ은? (단, DBMS는 오라클로 가정)
① SELECT COALESCE(NULL, 'A') FROM DUAL;
-> COALESCE 함수는 주어진 인수 목록에서 NULL이 아닌 첫 번째 값을 반환한다.
② SELECT NULLIF('A', 'A') FROM DUAL;
-> NULLIF(표현식1, 표현식2) 함수는 표현식1과 표현식2가 같으면 NULL, 아니면 표현식1을 리턴한다.
③ SELECT NVL('A', NULL) FROM DUAL;
-> NVL 함수는 주어진 첫 번째 인수가 NULL인 경우 두 번째 인수를 반환하고, 첫 번째 인수가 NULL이 아닌 경우에는 그대로 첫 번째 인수를 반환하는 오라클의 함수다. 따라서 A를 반환한다.
④ SELECT NVL(NULL, 0) + 10 FROM DUAL;
-> 두 번째 인수 0을 반환하고 + 10을 하기 때문에 정답이 아니다.
32. SELECT 문장의 실행 순서를 올바르게 나열한 것은?
④ FROM-WHERE-GROUP BY-HAVING-SELECT-ORDER BY
35. 아래에서 JOIN에 대한 설명을 가장 적절한 것은?
(가) 일반적으로 조인은 PK와 FK값의 연관성에 의해 성립된다.
(나) DBMS 옵티마이저는 FROM 절에 나열된 테이블들을 임의로 3개 정도씩 묶어서 조인을 처리한다.
(다) EQUI JOIN은 조인에 관여하는 테이블 간의 칼럼 값들이 정확하게 일치하는 경우에 사용되는 방법이다.
(라) EQUI JOIN은 '=' 연산자에 의해서만 수행되며, 그 이외의 비교 연산자를 사용하는 경우에는 모두 NON EQUI JOIN이다.
(마) 대부분 NON EQUI JOIN을 수행할 수 있지만, 때로는 설계상의 이유로 수행이 불가능한 경우도 있다.
④ (가), (다), (라), (마)
-> DBMS 옵티마이저는 FROM 절에 나열된 테이블이 아무리 많아도 항상 2개의 테이블씩 짝을 지어 JOIN을 수행한다.
37. 순수 관계 연산자로 가장 적절하지 않은 것은?
① SELECT
② UPDATE
③ JOIN
④ DIVIDE
-> 순수 관계 연산자에는 SELECT, PROJECT, JOIN, DIVIDE가 있다.
39.
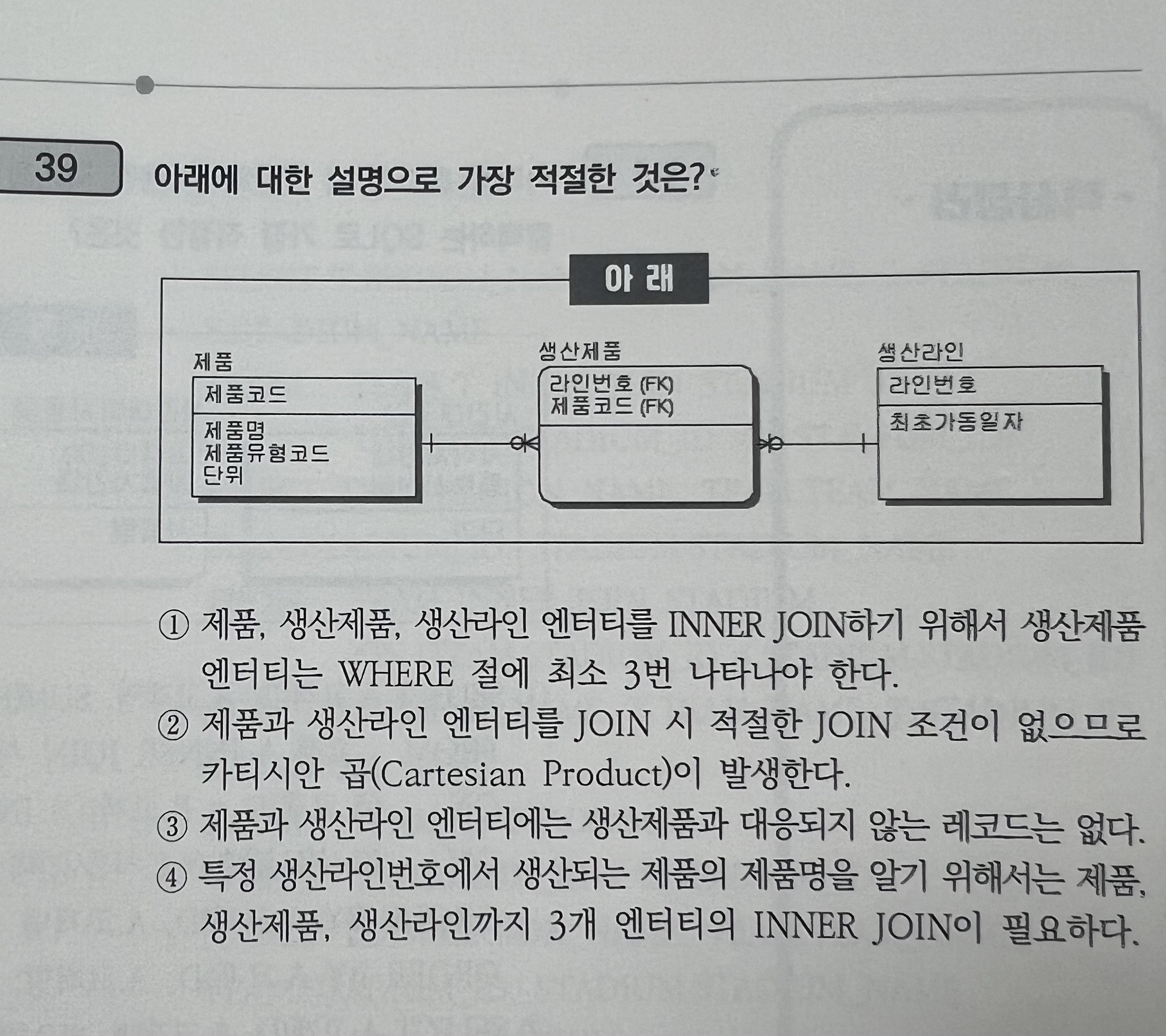
->
① 생산제품 엔터티는 WHERE절에 최소 2번 나타나야 한다.
③ 데이터 모델을 보면 제품과 생산라인 엔터티에는 생산제품과 대응되지 않는 레코드가 있을 수 있다.
④ 특정 생산라인에서 생산되는 제품의 제품며을 알기 위해서는 제품과 생산제품까지 2개의 엔터티만을 inner join하면 된다.
