운영체제
- Operating System
- ex) windows, android, linux
- 운영체제는 메모리를 이용해서 새로운 동작을 하고 그안에서 어떤 데이터를 다룰수 있게 인터페이스를 제공해주는 역할을 함
- 운영체제는 플랫폼
- 운영체제란, 컴퓨터에 포함된 CPU나 메모리, 입출력 기기 등이 사용자에 기대에 맞게 역할을 수행할 수 있도록 도와주는 창구 역할을 하는 소프트웨어
- 이러한 역할을
플랫폼 소프트웨어라고 부르기도 함 - 사용기기나 목적에 따라 필요한 운영체제의 유형이 다르기 때문에 운영체제의 종류가 다양함
📝 운영체제의 대표적인 역할들
- 프로세스 관리
- 메모리 관리 : 데이터 들을 필요한 공간에 맞게 사용
- 파일 시스템 관리
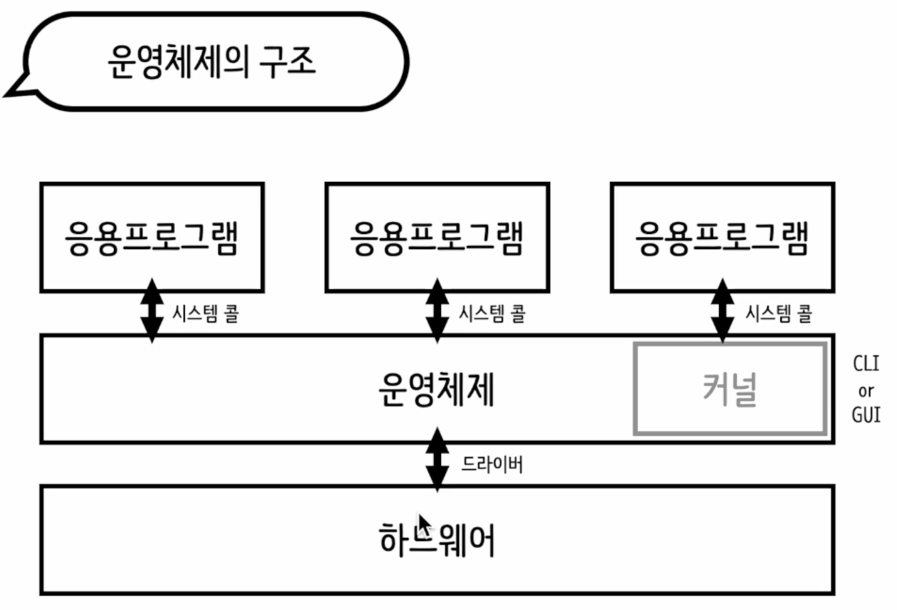
📝 운영체제의 구조
- 커널
- 커널: 사용자가 직접 접근 X, 아주 핵심적이고 중요한 파트이기에
- 사용자가 커널에 요청을 CLI(Command Line Interface)를 통해 할 수 있음
- 또는 GUI(Grapic User Interface) -> 데스크톱 컴퓨터를 키면 바탕화면 같은것이 GUI임
- 시스템 콜
- 어플리케이션이 컴퓨터의 자원에 접근할 떄 위험성 없이 적절한 방법으로 작업을 수행 할 수 있게 해주는 어플리케이션과 커널간의 인터페이스 이다.
- 쉽게 말해서 커널에서 정해준 함수만 사용할 수 있음
- 드라이버
- 그래픽카드, USB, 메로리 등 다양한 외부기기와 컴퓨터를 연결했을때 정상적으로 사용되려면 운영체제가 지원을 해줘야 사용을 가능
📝 컴퓨터 하드웨어 구조
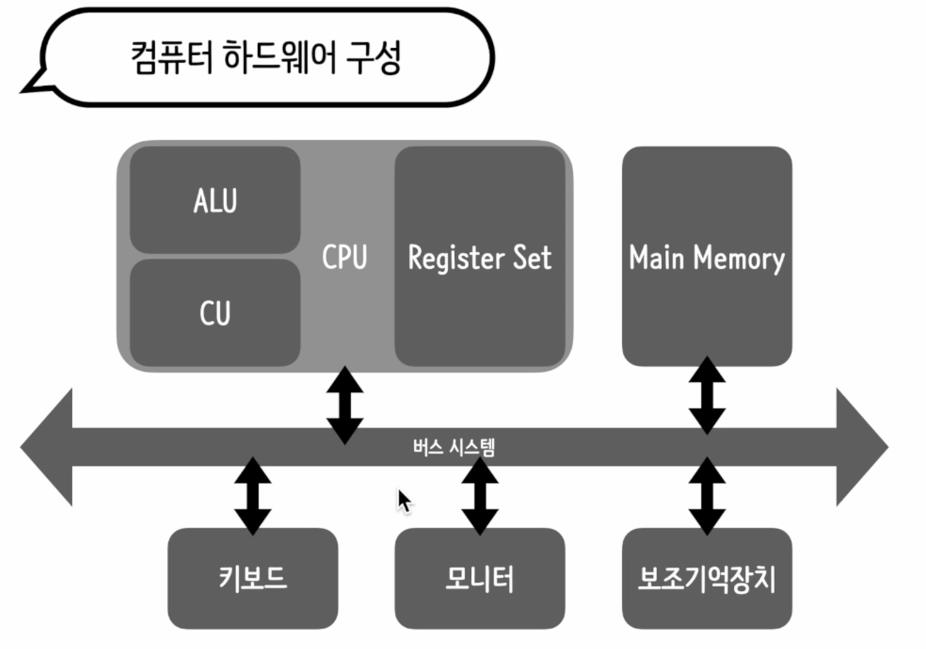
CPU(Central Processing Unit): 중앙 처리 장치
- 컴퓨터 내부에서 주요 연산을 처리하느 두뇌 역할
- ALU(Arithmetic Logic Unit, 산술 논리 연산 장치): 연산 담당 파트
- CU(Control Unit): 연산 명령을 해석
- Register Set: 데이터를 처리하기 위해 임시 저장 장치
Main Memory(Radom Access Memory : RAM)
- 프로그램의 실행 파일이 올라가서 실행되는 영역
- 프로세스 관리를 위해 존재하는 메모리
| 구분 | 메인 메모리 (주기억장치, RAM) | 보조 기억c 장치 (저장장치, HDD/SSD) |
|---|---|---|
| 역할 | 실행 중인 프로그램과 데이터 저장 | 데이터 및 파일을 영구적으로 저장 |
| 속도 | 빠름 (나노초 단위) | 느림 (밀리초 단위) |
| 휘발성 | 휘발성 (전원 OFF 시 데이터 삭제) | 비휘발성 (전원 OFF 후에도 데이터 유지) |
| 용량 | 보통 수 GB~수십 GB | 보통 수백 GB~수 TB |
| 예시 | RAM (DDR4, DDR5 등) | HDD, SSD, USB, 외장 하드 |
버스 시스템
컴퓨터를 구성하는 요소들 사이에서 데이터를 주고받기 위해 사용되는 경로
- 데이터 버스(Data Bus)
- 역할: CPU와 메모리, 입출력 장치 간 데이터를 전달
- 특징: 양방향 전송 가능
- 예시: CPU가 RAM에서 데이터를 읽거나 저장할 때 사용
- 주소 버스(Address Bus)
- 역할: CPU가 메모리나 입출력 장치의 특정 주소를 지정
- 특징: 단방향 전송 (CPU → 메모리/입출력 장치)
- 예시: CPU가 특정 메모리 주소에 접근할 때 사용
- 제어 버스(Control Bus)
- 역할: CPU가 시스템의 다양한 장치들을 제어하는 신호를 전달
- 특징: 양방향 또는 단방향 전송
- 예시: 읽기(Read), 쓰기(Write), 인터럽트(Interrupt) 신호 등
📌 한마디로 정리!
- 데이터 버스: 데이터 이동
- 주소 버스: 위치 지정
- 제어 버스: 명령 전달
📝 CPU 이해
- ALU(Arithmetic and Logic Unit, 산술 논리 연산 장치): 연산 담당 파트
- 산술 연산
- 논리 연산
- 바이너리 형태를 이해하는 능력이 없음 그래서 CPU에 등록된 명령어를 해석하기 위해 CU가 필요함
- CU(Control Unit): 연산 명령을 해석, C나 JAVA같은 compile 언어로 작성한 코드를 compile하면 실행 파일이 만들어짐, 실행 파일엔 CPU에 일을 시키기 위한 명령어가 저장되어 있음
- Register Set: 데이터를 처리하기 위해 임시 저장 장치
- 프로그램 카운터(Program Counter): 메모리에서 가져다 실행할 다음 명령을 일시적으로 저장하는 레지스터
- 인스터럭션 레지스터(Instruction Register): 이제 해석해야할 명령어를 저장하는 레지스터
- 어드레스 레지스터(Address Register): 메모리의 주소를 저장하는 레지스터, CPU가 읽어들이고자 하는 주소값을 어드레스 버스(Address Bus) 로 보낼때 거치는 레지스트
- 버퍼 레지스터(Buffer Register): 메모리의 읽거나 쓰려는 데이터나 명령을 일시적으로 저장하는 레지스터, 데이터를 주고받는 데이터가 바로 쏴지지않고 잠시 대기하는 상태
- 플래그 레지스터(Flag Register): 연산 결과, CPU상태에 대한 부가적인 정보를 저장하는 레지스터
- 스택 포인터(Stack Pointer): 스택의 꼭대기를 가리키는 레지스터, 스택이란 지역변수나 매개변수를 저장하기위해 사용하는 메모리 영역의 이름, 다음꺼내 써야할 데이터를 알려주기위해 사용하는 레지스터
- 플래그
- CPU 명령전달
- CU 명령 해석
- ALU 명령 실행
- 일을 하는 와중 중 명령이 들어오면 Register에서 대기
-
클럭 펄스(Clock Pulse)
- 시스템 동기화를 위해 존재하는 클럭 펄스
- 초당 처리할 수 있는 명령의 갯수, CPU는 그 클럭에 맞춰서 일을 진행함
- 동기 명령을 가지런히 정렬해서 처리하기 위해 클럭에 맞춰서 하는것
-
즉 이러한 시스템을 매끄럽게 진행되도록 도와주는 것이 운영체제 이다.
📝 프로그램 실행 과정
폰 노이만 구조
CPU <--> 메모리 <- 프로그램
프로그램 코드(인간친화적) -> 어셈블리 코드(컴퓨터 친화적) -> 바이너리 코드(1과 0으로 구성된 코드)
- 실행파일이 만들어짐 -> 하드디스크 같은 보조메모리에 저장
- 메인 메모리에 등록
- CPU에 의해 차레대로 실행(순차적, 스택으로 쌓여있음)
- Fetch: 메모리 상에 등록된 명렁어를 CPU로 가져옴(레지스트)
- Decode: 가져다 놓은 명령어를 CPU가 해석(CU)
- Execution: 수행(ALU)
버스 시스템
- 데이터 버스: 데이터 이동을 위해 필요한 버스
- 컨트롤 버스: CPU가 원하는 바를 메모리에 전달하기 위한 버스
- 어드레스 버스: 주소값을 이동하기 위해 필요한 버스
📝 프로그램 실행 중 돌발상황, 인터럽트
- CPU가 어떤 작업을 수행하고 있을 때
- CPU의 작업을 방해하는 신호를 가리켜 인터럽트
- -> CPU가 지금 하고있는 작업을 잠시 멈추고 우선적으로 처리해야할 작업이 생겼다라고 신호를 보내는 것
- 정상적으로 수행할 수 없는 명령어가 입력되면, CPU는 인터럽트를 발생시킨다 ->
예외Ex) ValueError, ZeroDivisionError... - 입출력 장치(하드웨어)로부터 발생하는 인터럽트는
비동기 인터럽트라고 표현 하기도 함 CPU가 발생시키는 인터럽트가 아니기에 Ex) KeyBoardInterrupt(ctrl+c) ...
인터럽트 핸들링
- 인터럽트가 발생하면, 인터럽트에 대응하는 무언가가 동작해야 한다. 이를
인터럽트 서비스 루틴이라한다.- 인터럽트 서비스 루틴은 이터럽트를 처리하기 위해 특정 인터럽트 신호에 대해 미리 정의되어 있는 프로그 또는 함수 이다.
import time
import signal
def handler(signum, frame):
print("키보드 인터럽트 감지")
print("신호 번호: ", signum )
print("스텍 프레임:", frame)
exit()
signal.signal(signal.SIGINT, hanlder)
while True:
print("5초 간격으로 출력중...")
time.sleep(5)📝 프로세스
- 프로세스란
실행중인 프로그램을 뜻함. 운영체제는 필요한 자원을 할당하고 관리, 그렇게 시작한 프로그램은 프로세스 가 됨
프로세스 구조
- 명령어가 담긴 코드 영역
- 프로세스가 실행하는 코드 즉 명령어 집합이 저장되어 있는 영역
- 전역변수 등이 담긴 데이터 영역
- 지역변수 등이 담긴 스택 영역
- 휘발성 변수가 저장되어 있는 곳
- 동적 메모리 할당을 위한 힙 영역
레지스터
- 프로그램의 실행을 위해서는 절대적으로 레지스터가 필요
- 현재 실행중인 프로세스를 위한 데이터들로 채워짐
# 파이썬 프로그램도 프로세스가 될수 있음
import os
# getpid: 운영체제 관리를 위한 프로세스 ID
# 프로세스에는 ID가 할당됨
print("파이썬 코드 실행 중! 실행 중인 프로세스의 아이디는 :", os.getpid())
# 내 컴퓨터 운영체제 안에서 돌아가고 있는 프로세스를 조회하는 코드
# pip install psutil
import psutil
for proc in psutil.process.iter():
ps_name = proc.name()
print(ps_name)
if "Chrome" in ps_name :
print(ps_name, proc.pid)
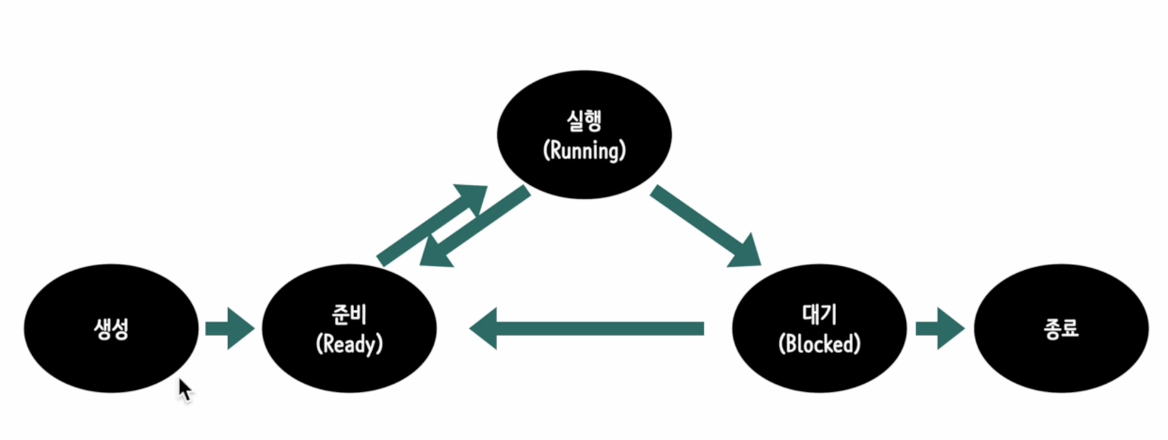
📝 프로세스 상태
-
CPU는 한 번에 하나의 연산밖에 수행할 수 있다.
-
CPU는 여러 개의 프로세스를 동시에 실행하지 않고, 빠르게 번갈아 가며 실행한다.
-
운영체제는 빠르게 번갈아 수행되는 프로세스의 순서를 관리하고 자원을 분배해야함
- PCB(Process Control Block): 프로세스와 관련된 자료구조를 저장하는 구조
- 프로세스를 식별하기 위해 필요한 정보들이 저장됨
- 프로세스 ID, 레지스터 데이터, 스케줄링 정보, 그리고 상태 ...
-
운영체제는 CPU가 여러개의 프로세스를 번갈아 수행할수 있게 해야함, 그래서 각 프로세스는 각 상황에 따라 상태정보를 가짐
-
생성 -> 준비 <--> 실행 -> 대기 -> 종료, 또는 다시 준비 -> 실행 -> 대기 -> ...종료(소멸)
- 대기상태는 대기상태가 된 이유가 사라지고 다시 준비상태가 되어야 다시 실행될 수 있음
프로세스 계층
- 부모 프로세스 -> 자식 프로세스 (부모 프로세스에 의해 생성된 프로세스): 독릭적이며 자신만의 ID를 가지고 있음
# 계층을 확인하는 코드
import psutil
for proc in psutil.process_iter():
ps_name = proc.name()
if "Chrome" in ps_name :
child = proc.children()
print(ps_name, proc.status(), proc.parent(), child)
if child :
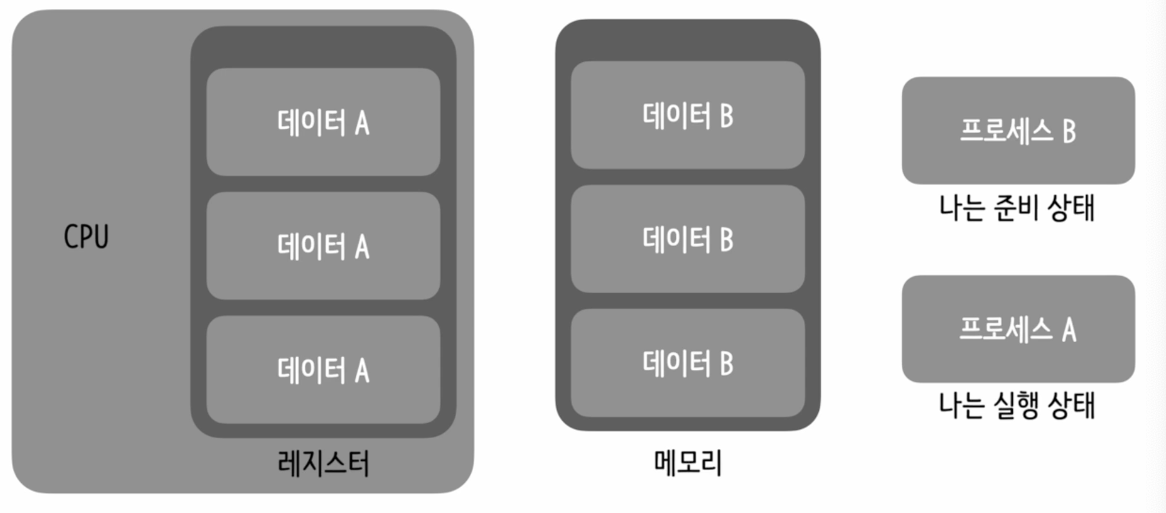
print(f"{ps_name}의 자식 프로세스", child)📝 컨텍스트 스위칭
멀티 프로세스 운영체제
- 여러개의 프로세스를 관리해가며, 마치 동시에 실행되는 것처럼 운영할 수 있는 운영체제
- 운영체제가 실행 중일때 다른 프로세스를 여러개를 실행한다는 의미임
- 운영체제에 매우 부담되는 작업
컨텍스트 스위칭
- 프로세스를 실행하는 중에 다른 프로세스를 실행 하기 위해 실행중인 프로세스의 상태를 저장하고 다른 프로세스의 데이터 상태로 교체하는 것을 컨텍스트 스위칭 이라함
문맥 교환
- 현재 실행중인 상태의 레지스터를 다 저장해서 프로세스로 넣어 준비상태의 프로세스를 만들고 백업 해둠
- 그리고 실행중인 상태의 프로세스와 번갈아 가면서 사용하는 것임
프로세스 생성
- 프로그램 실행 시, 운영체제는 코드 영역과 데이터 영역을 메인 메모리에 올리고 빈 스택과 빈 힙을 만들어 공간을 확보한다. 이는 시스템에게 상당한 부담을 주는 일
- 새로운 프로세슽를 생성하는 것보다, 기존 프로세스를 복사하는 것이 빠름, 따라서 모든 프로세스는 최초의 프로세스로부터 복사된다 -> 부모 프로세스 로부터 자식 프로세스가 생성
- 부모 프로세스를 복사하는 시스템 함수를
fork()함수라 함fork()를 통해 만들어진 함수를exec()시스템 함수를 이용해 코드 영역과 데이터 영역을 원하는 내용으로 덮어쓰기 위한 작업을 해줘야함- 그러면 부모 프로세스와 다른 프로세스가 만들어지고 동작하게 됨
# 멀티 프로세싱을 위한 작업
from multiprocessing import Process
import os
def func():
print("안녕, 함수야!")
print("나의 프로세스 아이디: ", os.getpid())
pirnt("나의 부모 프로세스 아이디:", os.getppid()) # 부모 프로세스
if __name__ == "__main__" :
print("앱 프로세스 아이디 : ", os.getpid())
child1 = Process(target=func).start()
child1 = Process(target=func).start()
child1 = Process(target=func).start()
# 부모 프로세스는 전부 같은 값이 나올것이고 자식은 다르레 나옴
# 만약 함수를 여러개 만들어서 다른것을 출력하더라도 아이디 값은 다르게 나오겟지만
# 한 모듈에서 파생되어서 나오는 것이니 부모 프로세스는 동일하게 나온다📝 스레드의 이해
- 컨텍스트 스위칭으로 인한 부하를 줄이기 위한 답은 프로세스를 줄이는 것이다.
- 프로세스는 슬하에 스레드를 두어 작업을 처리할 수 있다.
- 모든영역을 공유하지만 스택 영역많은 공유하지 않는다.(지역변수, 매개변수를 저장하는 영역)
- 작업마다 따로 가지지않으면 제대로 작업이 처리되지 않음 -> 개별적 쓰레드 할당
- 스택은 함수 호출시 전달되는 인자, 되돌아갈 주소값, 및 지역변수등을 저장하는 메모리 함수이다. 그 구조조차 스택의 구조이다, 따라서 메모리 공간이 독립적이지 않으면 추가적인 실행 흐름을 만들수 없음
- 처리할 작업이 많아져도 프로세스를 늘리는 것이 아닌 스레드를 늘려 효율적으로 처리 가능
- 스레드도 개별적으로 구분이 되어야 하기에 개별 ID가 존재
메모리 구조 관점에서 본 스레드 특징
- 스레드는 스레드가 하나 생성될 때마다 스레드를 위한 스택영역이 추가로 생성될 뿐, 그 이외의 영역은 프로세스 영역을 공유
- 스레드는 프로세스가 처리해야 할 작업을 수행하기 위해 존재하는 것이므로, 코드 영역을 공유해 명령어에 접근할 수 있어야 한다.
- 명령어 실행 시 전역변수, 정적변수, 지역변수 등의 데이터에 접근해야 하므로 데이터 영역과 힙 영역과 공유해야 한다.
# 하위 쓰레드 만들기
import threading
import os
def func():
print("안녕, 함수야!")
print("나의 프로세스 아이디: ", os.getpid())
print("스레드 아이디:", threading.get_native_id())
if __name__=="__main__" :
print("기존 프로세스 아이디 :", os.getpid())
thread1 = threading.Thread(target=func) # target에 맡길 작업 투척
thread1.start()
---
import threading
import os
import time
def something(word):
while True:
print(word)
time.sleep(3)
if __name__=="__main__" :
print("기존 프로세스 아이디 :", os.getpid())
t = threading.Thread(target=something, args=("happy",))
t.daemon = True # 메인 기능이 끝나면 같이 끝나게 만드는 기능(자기의 메인)
t.start()
print("메인 스레드에서 반복문 시작")
while True:
try:
print("daily...')
time.sleep(1)
except KeyBoardInterrupt:
print("goodbye")
break
# daily의 메인 쓰레드 안에서 something의 하위스레드가 실행되는것(3초) 메인은 1초CPU 스케줄링
CPU는 여러개의 프로세스를 빠르게 번갈아 실행하기 위해, 각프로세스를 위해 일하는 시간을 조금씩 나누어 배분한다
-
프로세스 스케줄링: 프로세스의 CPU 점유 순서 및 방법을 결정짓는 일을 가르킴, 알고리즘을 통해 분류
-
프로세스 우선순위
- 프로세스 별로 요구하는 자원이 상이하기 때문에, 운영체제(스케줄러)가 모든 프로세스에 동일한 빈도로 CPU를 할당한느 것은 비합리적임
- 운영체제는 프로세스마다 우선순위를 부여하고 이를 기준으로 프로세스를 실행한다.
# ps -el | grep python: mac에서 가능한 현재 돌아가고 있는 프로세스 를 볼수있음(파이썬 이름을 가진)
📝 스케줄링 알고리즘
Queue
운영체제는 준비 상태의 프로세스와 대기 상태의 프로세스를 관리하기 위해 큐(Queue) 자료구조를 사용
-
준비 Q: CPU를 이용하고 싶은 프로세스들이 줄을 서기 위해 존재하는 Q
-
대기 Q: 입출력 장치를 이용하기 위해 대기상태에 있는 프로세스들이 줄을서기 위해 존재
-
Q: 프로세스의 정보를 가지고 있는 프로세스 컨트롤 블록들이 줄을서고 운영체제는 줄을 서 있는 컨트롤 블록을 참고해서 어떤 프로세스를 실행할지 결정
스케줄링 알고리즘시 고려사항
- 부하가 최소화되어야 함
- 컴퓨팅 자원을 효율적으로 사용해야 함
- 균형잡힌 스케줄링을 해야 함
- 대기 및 응답 시간이 너무 길어서는 안됨
- 선입선출(First In First Out)
- 단순하고 직관적이지만 실행시간이 짧은 프로세스가 실행 시간이 긴 프로세스 뒤에서 한참 기다리는 상황이 벌어질 수 있음,
- (우선순위가 같다면)순서대로 작업하는 것
- 최단 작업 우선(Shortest Job First)
- 프로세스의 실행 시간을 정확히 예측할수 없다는 문제가 있어 현실적이지 않음
- (우선순위가 같다면)실행시간이 짧은 것부터 실행
- 라운드 로빈(Round Robin)
- (우선순위가 같다면)정해진 시간 만큼만 CPU를 점유하고, 시간이 다지나면 컨텍스트 스위칭하는 방식
- 우선순위 스케줄링(Priority Scheduling)
- 앞선 알고리즘의 기반이 되는 아이디어, 우선순위만 고려할 경우 우선순위가 낮은 프로세스가 배제되어 버리는 '기아' 상태에 빠질 수 있음
- 각 프로세스마다 우선순위를 부여해서 우선순위를 먼저 처리하는 과정
📝 프로세스 간 통신
- 프로세스는 독립적으로 실행되지만, 필요시 다른 프로세스와 데이터를 주고받으며 통신하는 경우도 있음
- 이를 가르켜 IPC(Inter-Process Coummunication)라 한다
통신을 하려면, 통신의 각주체가 만날 수 있는 매개체가 필요
- 기본적으로 프로세스는 독립적이기에 서로 통신을 할 수가 없음
- 메일슬롯 방식(IPC)(프로세스 간에 관계가 없는 관계에서)
- 데이터를 받기 위해서 프로세스가 우체통 역할을 하는 객체를 마련하고 이를 통해 데이터를 주고 받는 방식, 단방향이기에 각각 만들어야 함
- 파이프 방식(IPC)(관계가 있는 파일)
- 익명파이프 또는 네임드 파이프를 통해 데이터를 주고 받는다
- 익명파이프는 서로 관계가 있는 프로세스 간에 통신을 할떄 사용하는 단방향 파이프
- 네임드 파이프는 프로세스 간에 양방향 통신을 할떄 사용하는 파이프
# 파이프 기반 통신
from multiprocessing import Process, Pipe
import os
def send(conn):
print(f"{os.getpid()}가 {os.getppid()}에게 데이터를 보낸다")
conn.send("Hello Parent!") # 부모 프로세스에게 메시지 전송
conn.close() # 파이프 닫기
if __name__=="__main__":
parent, child = Pipe() # 양방향 통신이 가능한 파이프 생성
p = Process(target=send, args=(child,))
p.start()
print("기존 프로세스 아이디:", os.getpid())# 부모 프로세스 ID 출력
print(parent.recv()) # 자식 프로세스로부터 데이터 받기
p.join() # 프로세스가 작업을 종료할떄까지 기다림
# 기존프로세스 아이디:
# 자식이 부모에게 보낸다
# hello parent # recv 에서 받은 것
# 실행 흐름
1. 부모 프로세스(main)가 실행되며 Pipe()를 생성
2. 새로운 프로세스(send 함수)가 실행되면서 자식 프로세스가 생성됨
3. 자식 프로세스가 부모에게 데이터 전송 (conn.send())
4. 부모 프로세스가 데이터를 수신 (parent.recv())
5. 자식 프로세스 종료 후 p.join()을 통해 대기 후 종료
--- 추가예제
from multiprocessing import Process
import os
import time
def writer() :
print(f"{os.getpid()}가 파일에 쓴다")
with open("13.txt", "w") as f: # 파이썬의 w는 생성도 포함 없으면 알아서 파일만듬
f.write("hello")
def reader() :
print(f"{os.getpid()}가 파일을 읽는다")
with open("13.txt", "r") as f:
print(f.read())
if __name__ == "__main__":
p1 = Process(target=writer) # 읽을게 있어야 읽으니까 writer먼저
p1.start()
time.sleep(2) # 딜레이를 줌으로써 쓰는중에 접근할 수 없게
p2 = Process(target=reader)
p2.start()
p1.join()
p2.join()
# 7756가 파일에 쓴다
# 7759가 파일을 읽는다
# HELLO📝 동기화
- 프로세스들은 서로 독립적이지만, 프로세스 간 통신을 하거나 같은 대상에 대한 작업을 함으로써 협력할 수 있다. 그런데 이때, 동시다발적으로 작업을 처리하면 문제가 발생한다.
- 한 파일을 두고 같이 작업을 시행하려 할때 문제 발생
- 프로세스 + 스레드 둘다 적용
- 공유 자원: 프로세스 간 통신에서 공동으로 이용하는 변수가 파일, 입출력 기기등이 존재
- 각 프로세스의 접근 순서에 따라 결과가 달라질 수 있는데, 프로세스가 동시에 실행할 경우 문제가 발생할 수 있는 영역을
임계구역이라 한다.
- 각 프로세스의 접근 순서에 따라 결과가 달라질 수 있는데, 프로세스가 동시에 실행할 경우 문제가 발생할 수 있는 영역을
상호배제
- 동기화 기법은 임계구역에서 발생할 수 있는 문제를 해결하기 위한 기법
- 동기화 기법 구현 시에는
상호배제라는 조건을 만족시켜야 한다.
- 상호배제란 하나의 프로세스가 임계구역에 들어갔다면 다른 프로세스는 임계구역에 들어갈 수 없다는 조건
뮤텍스 락
- 동시에 접근해서는 안되는 자원에 동시접근 못하도록 막는 동기화 도구
- 임계구역에 접근하는 프로세스는 뮤텍스 락을 통해 다른 프로세스에서 접근하지 못하도록 막을수 있음
- 공유 자원이 하나인 경우
acquire(): 진입 시 문을 잠그는 함수release(): 다쓰고 나올떄 문잠금을 해제하는 함수
from multiprocessing import Process, Value # 프로세스간의 값을 공유하게 만들고 싶을때 사용하는 파이썬 생성자 함수
def counter1(share_num, cnt):
for i in range(cnt):
share_num.value += 1
def counter2(share_num, cnt):
for i in range(cnt):
snum.value -= 1
if __name__=="__main__":
shared_number = Value('i', 0)
p1 = Process(target=counter1, args=(shared_number,5000))
p1.start()
p2 = Process(target=counter2, args=(shared_number,5000))
p2.start()
p1.join()
p2.join()
print("final num is:", shared_num.value)
# 0이 안됨 공유자원이여서 값이 꼬여버림
# 뮤텍스 락을 설정한후 실행
from multiprocessing import Process, Value, Lock # 뮤텍스 락 역할
def counter1(share_num, cnt, lock):
lock.acquire() # 문잠금
try :
for i in range(cnt):
share_num.value += 1
finally :
lock.release()
def counter2(share_num, cnt, lock):
lock.acquire()
try:
for i in range(cnt):
snum.value -= 1
finally:
lock.release()
if __name__=="__main__":
lock = Lock()1
shared_number = Value('i', 0)
p1 = Process(target=counter1, args=(shared_number,5000), lock)
p1.start()
p2 = Process(target=counter2, args=(shared_number,5000), lock )
p2.start()
p1.join()
p2.join()
print("finall num is:", shared_num.value)
# 0으로 잘 나온다.
세마포어(key라 생각)
- 공유자원이 여러개
- 공유자원에 대하여 세마포어 즉 키를 전달해서 공유자원을 못쓰도록 막는것
wait(): 프로세스가 임계구역에 들어갈 수 있는지 기다려야 하는지 알려주는 용도signal(): 임계구역 함수에서 기다리고 있는 함수에서 이제 들어가도 된다고 신호를 보내는 함수
쓰레드 동기화 예시
import threading
from multiprocessing import Value, Lock # 뮤텍스 락 역할
def counter1(share_num, cnt, lock):
lock.acquire() # 문잠금
try :
for i in range(cnt):
share_num.value += 1
finally :
lock.release()
def counter2(share_num, cnt, lock):
lock.acquire()
try:
for i in range(cnt):
snum.value -= 1
finally:
lock.release()
if __name__=="__main__":
lock = Lock()1
shared_number = Value('i', 0)
t1 = threading.Thread(target=counter1, args=(shared_number,5000), lock)
t1.start()
t2 = threading.Thread(target=counter2, args=(shared_number,5000), lock )
t2.start()
t1.join()
t2.join()
print("finall num is:", shared_num.value)
# 0으로 잘 나온다.
📝 데드락(Deadlock)
- 기다리는 대상이 꼬리에 꼬리를 물고 이어져서 아무도 작업을 진행하지 못하는 상황을 데드락이라 한다.
- 공유자원으로 인해 발생
- 데드락 발생조건 4가지 중 모두 만족해야 발생 가능성이 생김
- 상호배제(Mutual exclusion) : 공유자원 같이 사용할 수 없어야 한다.
- 비선점(No preemption) : 공유자원을 가지고 있을때 빼았아서 사용할 수 없어야 한다
- 점유 및 대기(Hold and wait) : 쓰고있을 경우 사용하기 위해 기다리고 있어야 한다.
- 원형 대기(Circular waite) : 꼬리에 꼬리를 물어 둥글게 형성되어 있어야 한다.
식사하는 철학자 문제
📌 문제 개요
- N명의 철학자가 원형 테이블에 앉아 있음.
- 각 철학자는 생각(Thinking)하거나 식사(Eating) 함.
- N개의 포크(Fork)가 놓여 있으며, 각 철학자는 왼쪽과 오른쪽의 포크를 사용해야 식사할 수 있음.
- 문제: 모든 철학자가 교착 상태(Deadlock)나 기아 상태(Starvation) 없이 원활하게 식사할 수 있도록 동기화해야 함.
📌 문제 발생 가능성
-
경쟁 조건(Race Condition)
- 여러 철학자가 동시에 포크를 집으려고 하면 충돌이 발생할 수 있음.
-
교착 상태(Deadlock)
- 모든 철학자가 왼쪽 포크만 집고 오른쪽 포크를 기다리는 상황이 발생하면 영원히 대기하게 됨.
-
기아 상태(Starvation)
- 일부 철학자가 계속해서 포크를 획득하지 못하면 식사를 못하고 계속 굶는 상태가 됨.
📌 해결 방법
1. 순서 기반 해결법 (홀수-짝수 철학자)
- 짝수 번호 철학자: 왼쪽 → 오른쪽 포크 순서로 집음
- 홀수 번호 철학자: 오른쪽 → 왼쪽 포크 순서로 집음
📌 장점: 교착 상태(Deadlock) 방지 가능
2. 웨이터(Butler) 알고리즘
- 중앙 관리자(웨이터, Mutex)가 철학자들에게 최대 (N-1)개까지만 포크를 허용
- 철학자가 식사하려면 웨이터에게 허가 요청을 해야 함
📌 장점: Deadlock 예방 및 자원 사용 관리 가능
3. 개별 철학자 스레드 + 세마포어
- 각 철학자 스레드가 세마포어(Semaphore)를 사용하여 포크를 집도록 제한
- 두 개의 세마포어를 확보한 철학자만 식사 가능
📌 파이썬 코드 예제 (Semaphore 사용)
import threading
import time
N = 5 # 철학자 수
forks = [threading.Semaphore(1) for _ in range(N)] # 포크 세마포어 배열
def philosopher(i):
left = i
right = (i + 1) % N
while True:
print(f"철학자 {i} 생각 중...")
time.sleep(1)
# 포크 집기
forks[left].acquire() # 왼쪽 포크 획득
forks[right].acquire() # 오른쪽 포크 획득
print(f"🍽️ 철학자 {i} 식사 중...")
time.sleep(2)
# 포크 내려놓기
forks[left].release()
forks[right].release()
print(f"철학자 {i} 식사 완료. 다시 생각 시작...")
# 철학자 스레드 생성 및 실행
threads = []
for i in range(N):
t = threading.Thread(target=philosopher, args=(i,))
threads.append(t)
t.start()
# 모든 스레드가 종료될 때까지 대기
for t in threads:
t.join()📌 코드 설명
threading.Semaphore(1): 각 포크를 이진 세마포어로 설정 (한 번에 한 철학자만 사용 가능)- 각 철학자는 왼쪽과 오른쪽 포크를 집고 식사
- 식사가 끝나면 포크를 놓고 다시 생각 상태로 전환
- 스레드 기반 실행을 통해 병렬적으로 실행
📌 해결된 문제점
-
Deadlock 방지
- 두 개의 포크를 동시에 획득한 경우만 식사가 가능하여 교착 상태 예방
-
Starvation 해결 가능
- 웨이터 알고리즘 등 추가 적용 가능
-
경쟁 조건 방지
Semaphore.acquire()를 사용하여 한 번에 하나의 철학자만 포크를 획득
📌 결론
- 식사하는 철학자 문제는 동기화(Synchronization)의 대표적인 문제
- 세마포어, 웨이터 알고리즘 등을 활용하여 Deadlock과 Starvation을 방지 가능
- 멀티스레딩 환경에서 공유 자원(포크) 관리 방법을 학습하는 데 중요한 개념
📝 메모리
- 레지스터
- 가장 빠른 대신 용량이 적음
- 휘발성
- 캐시(L1/L2)
- CPU와 RAM사이에서 중간 저장소
- CPU에 가장 근접해 있는 메모리
- 레지스터와 RAM사이에 데이터 이동이 있을때 속도를 보완하는 역할을 하는 메모리
- CPU 입장에선 바로바로 데이터를 꺼내어 쓸쑤 있는 저장소 같은 느낌
- 휘발성
- 메인 메모리(RAM)
- 운영체제와 프로세서 들이 올라가는 공간
- 실행중인 프로그램을 올리기 위해 주로 사용
- 휘발성
- 보조기억장치(HDD/SSD)
- 크고작은 파일들을 저장하기 위한 용도
- 속도는 느리지마 용량은 큼
- 비휘발성
메모리 관리 방식
가변 분할 방식
- 프로세스의 크기에 따라 가변적으로 메모리 할당
- 연속메모리 할당
- segmentation
- 스와핑
- 실행 상태의 프로세스는 메인 메모리에 올리고, 실행 상태가 아닌 프로세스들은 보조 장치에 따로 마련된 스왑 영역에 올린 다음 프로세스의 상태 변화에 따라 두공간 사이에서 프로세스가 이동하는것을 가리켜 스와핑 이라한다.
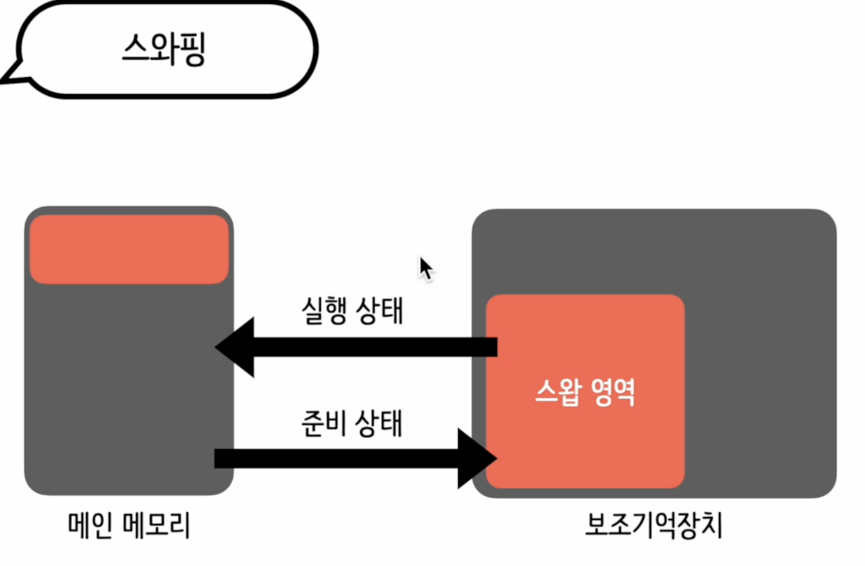
- 외부 단편화
- 프로세스를 메모리에 연속 배치하는 작업을 하다보면 메모리가 낭비되는 '외부 단편화' 상황이 발생하기도 함
- 기존의 메모리 들의 작업이 끝나고 분할되어 있는 공간은 충분하지만 쪼개어져 있어 외부의 큰 메모리를 요하는 작업을 실행할 수가 없을때 외부 단편화라 한다.
- 조각 모음 : 현재 실행중인 작업을 중단하고 빈공간을 모아서 다시 실행 하는 것을 의미함, 시스템에 큰 부하를 주어 빈번하게 사용하면 안됨
Garbage Collection 예제
# 문자열 객체를 변수 my_name이 참조했다
# 레퍼런스 카운트가 1인 상태
my_name = "Gookhee"
# 레퍼런스 카운트가 2인 상태 : 국희라는 이름을 참조할수 있는 변수가 2개란 뜻
your_name = my_name
my_name = 1 # 레퍼런스 카운트 1
your_name = 2 # 레퍼런스 카운트 0
# 레퍼런스 카운트가 0이된 것을 제거 대상이라 생각한다
# 이 것을 Garbage Collection 이라 생각한다 : 소멸 대상으로 등록let players ={
boys :{
Bregkamp: "Striker"
}
}
let persons = players
players = ["Son", "Park"]
let human = persons.boys
persons = "persons"
human = null // 비로소 레퍼런스 카운트 0 -> 소멸대상 -> 시스템의 여유가 생길때 삭제고정 분할 방식
- 메모리를 고정된 크기로 나누어 놓고 프로세스마다 필요한 칸만큼 할당
- 비연속 메모리 할당
- paging
-
외부 단편화
프로세스를 메모리에 연속 배치하는 작업을 하다보면 메모리가 낭비되는 '외부 단편화' 상황이 발생하기도 함
-
프로세스가 공간을 차지고 있다 작업이 종료되지만 공간이 쪼개
📝 가상 메모리 관리
작은 메인 메모리(RAM)이 프로세스를 실행한다?, 그렇다면 실행할 프로세스가 메인 메모리 보다 덩치가 큰경우엔 스와핑을 활용해 사용
페이징
- 고정 분할 방식
- 페이징 기법에서는 메모리 공간을 일정한 크기의 페이지로 나누어 다룬다.
- 페이지 안에서 빈공간이 남는 내부 단편화가 발생하는 문제
-
논리 주소 공간
- 사용자와 프로세스가 참조하는 공간
- 실제 메모리보다 더 큰 공간
- 보조 기억장치의 크기를 지원받아서 크기를 키운것
-
물리 주소 공간
- 실제 메모리의 공간
-
CPU가 논리주소를 통해 메모리에 접근하고 이를 물리주소로 변환하여 실제메모리에 올리는 것으로 프로세스를 실행 함
-
페이지 테이블
- 페이지 번호와 프레임 번호를 짝지어 주는 테이블
- CPU내에는 각프로세스 테이블이 적재된 주소를 가리키는 페이지 테이블 베이스 레지스터가 있음
-
페이지 테이블 엔트리
- 접근비트: 페이지가 메모리에 올라온 후 데이터에 접근이 있었는지, 1은 접근이 있었다 반대는 0
- 변경비트: 페이지가 메모리에 올라온 후 데이터의 변경이 있었는지, 1은 접근이 있었다 반대는 0
- 유효비트: 페이지가 어디에 있는지, 0이라면 스왑영역, 1이라면 물리영역에 있다. -> 메모리에 올라가 있지 않은 영역 즉 스왑영역에 접근하려 한다면 페이지폴트 라는 예외가 발생한다 -> 다른 처리가 필요
- 보호비트: 페이지에 대한 읽기, 쓰기, 실행 권한이 어떻게 되는지
-
페이지드 세그멘테이션
- 가변 분할 방식과 고정 분할 방식을 혼합한 가상 메모리 관리 방식
- 두 방식의 단점을 보완 - 세그먼트를 다시 페이지로 나누어 관리
foods =["햄버거", "샐러드", "비스킷"]
print(id(foods)) # 논리 메모리 주소 확인
mv = memoryview(b"happy day") # b: 바이트 형식으로 저장하겠다.
print(mv)
print(mv[0])
print(mv[1])
print(mv[2]) # 같은 p니까 같은 값 도출
print(mv[3])
# 메모리 사용 현황
import psutil
import os
print("메모리 사용량 조회하기")
memory_dict = dict(psutil.virtual_memory()._asdict()) # 시스템 사용량에 대해 튜플형식으로 반환해줌
print(memory_dict)
total = memory_dict["total"] # 메모리 총량
availabe = memory_dict["available"] # 메모리 즉시 제공 가능량
percent = memory_dict["percent"] # 메모리 사용률
pid = os.getpid()
current_process = psutil.Process(pid)
kb = current_process.memory_info()[0] / 2 ** 20 # 메모리 사용량
---
import tracemalloc # 메모리가 어떻게 할당되는지 추적하는 것, python 3.4 ~~
tracemalloc.start()
# 메모리 할당이 진행되는 작업 아무거나
data = [b'%d' % num for num in range(1, 10001)]
joined_data = b' '.join(data)
current, peak = tracemalloc.get_traced_memory()
print(f"현재 메모리 사용량 : {current / 10 ** 6} MB")
print(f"최대 메모리 사용량 : {peak / 10 ** 6} MB")
tracemalloc.stop()
tracemalloc.get_tracemalloc_memory() # 트레이스 말록 사용하느라 사용한 메모리 확인
print(traced / 10 ** 6)📝 페이지 교체
요구 페이징
- CPU가 특정 페이지에 접근하는 명령어를 실행 햇을때, 해당 페이지가 스왑 영역에 있어서 당장 실행시킬 수 없는 상태일 경우에는
'페이지 폴트'예외가 발생한다.- 페이지 폴트 예외가 발생하면 스와핑 작업이 먼저 진행된 후에 프로세스가 실행된다.
- 실행할 모든 프로세스를 메모리에 올려두는 것은 시스템에 부담이 될 수 있는 만큼 당장 필요한 페이지만을 메모리에 우선 적재하는 방법을 가리켜
'요구페이징'이라 한다
- 페이지 폴트시 -> 페이지 교체 정책 대표적인 3가지
- 선입선출: 가장 오래된 페이지 교체
- 최적 페이지 교체: 자주 사용될 예정인 페이지를 내버려두고 사용이 거의 안될 예정인 페이지를 교체, 실제로 구현하기 어려움 예상이 어려워서
- LRU(Least Recently Used): 최근 사용빈도가 가장 적은것을 교체하는 것, 구현하기 쉽고 성능도 좋음
# 선입선출 하나 만들어보기 운영체제라 생각하고
class PageReplacementFIFO:
def __init__(self, capacity):
self.capaciry = capacity
self.pages = []
def access_page(self, page) : # 4개째부터 교체가 이루어지게 하자
if page not in self.pages : # 기존의 페이지에 없으면 집어넣자
if len(self.pages) >= self.capacity:
self.pages.pop(0) # 제일 앞에 있는 페이지 제거
self.pages.append(page)
def status(self):
print("현재 페이지 상태 :", self.pages)
page_replacement = PageReplacementFIFO(capacity = 3)
page_replacement.status() # 빈상태 []
page_replacement.access_page(3)
page_replacement.status() # [3]
page_replacement.access_page(2)
page_replacement.status() # [3,2]
page_replacement.access_page(1)
page_replacement.status() # [3,2,1]
page_replacement.access_page(4)
page_replacement.status() # [2,1,4]
스래싱(thrashing)
- 모든것의 근본적인 이유는 메모리 공간의 부족, 즉 프레임 부족 때문
- 프레임이 부족하면 페이지 볼트가 자주 발생
- 페이지 폴트가 발생하면 잦은 스와핑 작업으로 인해 CPU 사용률이 떨어지게 된다.
- CPU 사용률이 떨어지면 운영체제는 더 많은 프로세스를 메모리에 올리려 하고, 이는 더 잦은 페이지 폴트로 이어져 악순환에 빠지게 된다.
- 이러한 문제를
스레싱이라고 한다.
📝 스래싱(Thrashing) 개요
- 스래싱(Thrashing) 은 가상 메모리 시스템에서 페이지 부재(Page Fault)가 너무 자주 발생하여 CPU가 메모리 스왑 처리에만 집중하고 실제 작업을 거의 수행하지 못하는 상태를 의미함.
- 스래싱이 발생하면 성능이 급격히 저하되며, 시스템이 비효율적으로 동작함.
📌 스래싱 해결책
| 해결 방법 | 설명 |
|---|---|
| 프레임 할당량 조정(Frame Allocation Adjustment) | 프로세스가 사용하는 물리 메모리 프레임 개수를 조절하여 스래싱 방지 |
| 워킹셋(Working Set) 기법 | 프로세스가 일정 시간 동안 자주 참조하는 페이지 집합(Working Set)을 유지하여 성능 향상 |
| 페이지 부하 제어(Page Load Control) | 한 번에 메모리에 올리는 페이지 수를 제한하여 과부하 방지 |
| PFF(Page Fault Frequency) 기법 | 페이지 부재(Page Fault) 발생 빈도를 기준으로 프레임 수를 동적으로 조정 |
| 로컬 프레임 할당(Local Allocation) vs. 글로벌 할당(Global Allocation) | 로컬 할당: 프로세스마다 고정된 프레임 수 할당 글로벌 할당: 모든 프로세스가 공유하는 프레임을 동적으로 할당 |
| 페이지 교체 알고리즘 최적화 | LRU(Least Recently Used), LFU(Least Frequently Used) 등의 효율적인 페이지 교체 알고리즘을 적용 |
📌 워킹셋(Working Set) 기법
1. 개념
- 워킹셋(Working Set) 이란 프로세스가 일정 시간 동안 자주 참조하는 페이지들의 집합을 의미함.
- 가상 메모리에서 프로세스가 일정 기간 내 참조한 페이지를 추적하여 자주 사용하는 페이지를 메모리에 유지하고, 사용하지 않는 페이지를 제거함으로써 스래싱을 방지.
2. 워킹셋의 정의
- W(Δ): 특정 시간 구간 Δ(델타) 동안 프로세스가 참조한 페이지 집합
- Δ 값 선택이 중요
- Δ 값이 너무 작으면 → 너무 많은 페이지가 제거됨 (과도한 페이지 부재)
- Δ 값이 너무 크면 → 불필요한 페이지까지 유지됨 (메모리 낭비)
3. 워킹셋을 활용한 스래싱 방지
- 워킹셋을 유지하며 최소한의 프레임을 확보하여 스래싱을 방지.
- 일정 시간 동안 참조되지 않은 페이지는 스왑 아웃(Swap Out)하여 메모리 활용도를 높임.
4. 워킹셋 기법의 장점
✔ 스래싱 방지: 자주 사용하는 페이지만 유지하여 CPU가 불필요한 스왑을 하지 않도록 함
✔ 메모리 효율 증가: 실제 필요한 페이지만 유지하므로 불필요한 페이지 사용 감소
✔ 동적 프레임 조정 가능: 프로세스의 실행 패턴에 따라 필요한 페이지를 동적으로 조절 가능
📝 파일
의미있는 정보들을 한덩어리로 모아 둔 논리적 단위, 보저기억 장치에 저장, 실행시 메인메모리 사용
- 파일이름, 파일 실행에 필요한 정보, 메타데이터
- 확장자 : 운영체제에게 있어 중요한 정보
- 응용 프로그램이 파일에 접근하려면 시스템 호출을 제공받아야 한다.
with open("number_one.txt", "w") as f:
f.write("one")
with open("number_two.txt", "w") as f:
f.write("two")
with open("number_three.txt", "w") as f:
f.write("three")
with open("number_four.txt", "w") as f:
f.write("four")
import glob # 파일네임의 패턴을 이용해 한꺼번에 접근
for filename in glob.glob("*.txt", recursive= True):
print(filename)
import fileinput # 내용들도 한번에 처리하기
with fileinput.input(glob.glob("*.txt")) as fi:
for line in fi :
print(line) # 모든 파일 내용 읽기
import fnmatch # filenamematch
import os
for filename in os.listdir('.'): # listdir: 현재 디렉토리에 있는것을 찾음
if fnmatch.fnmatch(filename, "??????_one.txt") :
print(filename) # number_one.txt
---
# 파일 관련 예외는 운영체제와 관계가 있음
try :
f = open("none.txt", "r") # 존재하지 않는것에 r을 하면 예러
print(f.read())
f.close()
except FileNotFoundError as e:
print(e)
issubclass(FileNotFoundError, OSError) # 첫번쨰 인자가 두번쨰 인자의 하위인자가 맞는지
const fs = require("fs")
fs.readFIle("number_one.txt", "utf8", (err, data) => {
if(err){
console.log("파일을 읽는 도중 오류가 발생.", err)
return;
}
console.log("파일 내용:", data)
})
let content = "four four four"
fs.writeFile("number_four.txt", content, (err) => {
if(err) {
console.log("파일을 쓰는 도중 오류가 발생.", err)
return;
}
console.log("파일쓰기 완료")
})
let content = "four four four"
fs.appendFile("number_four.txt", content, (err) => {
if(err) {
console.log("파일을 쓰는 도중 오류가 발생.", err)
return;
}
console.log("파일쓰기 완료")
})📝 디렉터리
- 운영체제는 파일을 정돈할 수 있도록 디렉터리를 지원
- 디렉터리도 파일의 일종
- 디렉터리에 저장된 파일 정보는 테이블 형태로 관리
- 테이블 행 하나하나를 가리켜 디렉터리 엔트리 라고 부른다
# os 파일 시스템 관련 함수
# pwd를 통해 현재 파일위치를 찾는다
pwd = "경로 복붙"
filenames = os.listdir(pwd) # 경로상의 파일들 반환
# 디렉터리인지 아닌지 여부
print(os.path.isdir(filenams[0])) # False
print(os.path.isdir(pwd + "/폴더") # True
# 파일인지 아닌지
print(os.path.isfile(filenams[0])) # True
print(os.path.isfile(pwd + "/폴더") # False
# 파일이름과 확장자 분리
filepath = pwd + "/" + filenames[0]
print(filepath)
os.path.splitext(filepath)
name, ext = os.path.splitext(filepath)
print(ext) # .txt
---
# 경로와 확장자 이요해 파일 찾고, 내용 읽기
import os
def searchFile(dirname, extension):
filenames = os.listdir(dirname)
for filename in filenames:
filepath = os.path.join(dirname, filename)
if os.path.isdir(filepath):
searchFile(filepath, extension)
elif os.path.isfile(filepath) :
name, ext = os.path.splitext(filepath) :
if ext == extension :
with open(filepathm, "r", encoding="utf-8") as f:
print(f.read())
searchFile("pwd경로", ".js") # 자바스크립트 코드 읽음
---
# 파일 복사 또는 이동
import os
import shutil
pwd = "/"
filenames = os.listdir(pwd)
for filename in filenames:
if "tokyo" in filename :
origin = os.path.join(pwd, filename)
print(origin)
shutil.copy(origin, os.path.join(pwd, "copy.txt")) # 원본 , 어디다가,
shutil.move(origin, os.path.join(pwd, "anony")) # 파일 이동
---
# 파일 경로를 문자열이 아닌 객체로 다루기
import os
import pathlib
for p in pathlib.Path.cwd().glob("*.txt"): # 현재 워킹디렉토리 cwd current working directory
print(p.parent) # 해당 텍스트들의 부모 경로가 나옴
new_p = os.path.join(p.parent, p.name)
print(new_p) # 내 파일의 총 경로
📝 파일과 메모리
- 하나의 파일은 여러개의 블록으로 이루어져 있다.
- 블록을 메미로에 할당할 때는 연속방식 또는 불연속방식을 사용할 수 있다.
🔗 연결 리스트 (Linked List) 자료구조
📌 개요
연결 리스트(Linked List)는 메모리의 불연속 할당을 기반으로 데이터를 저장하는 선형 자료구조입니다.
연결 리스트는 데이터를 노드(Node) 단위로 관리하며, 각 노드는 데이터와 다음 노드를 가리키는 포인터(Pointer)를 가지고 있습니다.
📌 연결 리스트의 구조
- 연결 리스트는 노드(Node)라는 단위로 구성됨
- 각 노드는 데이터 영역과 다음 노드를 가리키는 포인터로 구성됨
- 메모리에서 연속적이지 않은 영역을 사용 (불연속 메모리 할당)
🔹 기본적인 연결 리스트의 형태:
Head
|
▼
[Data | Next] -> [Data | Next] -> [Data | Next] -> NULL📌 연결 리스트의 특징
| 특징 | 설명 |
|---|---|
| 불연속 메모리 할당 | 노드가 메모리에 흩어져 저장되며 포인터로 연결 |
| 가변 크기 | 데이터를 동적으로 추가하거나 삭제 가능 |
| 동적 메모리 할당 | 실행 시간에 노드를 동적으로 생성 및 삭제 |
| 탐색 속도 | 순차 접근만 가능하여 탐색 속도는 느림 |
| 삽입·삭제 효율적 | 중간에 데이터를 삽입하거나 삭제할 때 매우 효율적 |
📌 연결 리스트의 종류
1. 단일 연결 리스트 (Singly Linked List)
- 한 방향으로만 다음 노드를 가리키는 포인터를 가짐
- Head 노드부터 순차적으로 접근 가능
2. 이중 연결 리스트 (Doubly Linked List)
- 양방향(앞, 뒤)으로 접근 가능한 포인터를 가짐
- 노드 탐색과 삭제가 더 쉬움
3. 원형 연결 리스트 (Circular Linked List)
- 마지막 노드가 첫 번째 노드를 가리키도록 구성
- 순환적인 데이터 구조를 나타낼 때 사용
📌 연결 리스트의 장점과 단점
장점
- 삽입과 삭제가 빠름 (O(1) 가능)
- 메모리 동적 할당으로 유연한 메모리 관리 가능
- 메모리의 낭비가 적음 (필요한 만큼만 사용)
단점
- 임의 접근(Random Access)이 불가능 (순차 접근만 가능)
- 탐색(Search)에 시간이 오래 걸림 (O(n))
📌 연결 리스트와 배열의 비교
| 구분 | 연결 리스트 (Linked List) | 배열 (Array) |
|---|---|---|
| 메모리 할당 | 불연속적 할당 (포인터로 연결) | 연속적 할당 |
| 데이터 접근 | 순차 접근만 가능 | 임의 접근 가능 (빠름) |
| 삽입 및 삭제 | 빠름 (O(1)) | 느림 (O(n)) |
| 탐색 속도 | 느림 (O(n)) | 빠름 (O(1)) |
| 크기 조절 | 쉬움 (동적 조정) | 어렵거나 비용이 큼 |
📌 결론
- 연결 리스트는 불연속 할당 방식을 사용하는 선형 자료구조로, 포인터를 이용하여 데이터 간 연결을 유지합니다.
- 삽입과 삭제가 효율적이며 동적 메모리 관리가 중요한 경우에 특히 유용합니다.
- 탐색 속도는 배열보다 느리기 때문에 상황에 따라 적합하게 선택하여 사용해야 합니다.
📌 전체 코드 (C언어)
#include <stdio.h>
#include <stdlib.h>
// 노드 구조체 정의
typedef struct Node {
int data;
struct Node* next;
} Node;
// 연결 리스트 함수들
void insertFront(Node** head, int value);
void deleteNode(Node** head, int key);
void printList(Node* head);
// 메인 함수
int main() {
Node* head = NULL; // 초기 연결 리스트는 비어 있음
// 노드 추가
insertFront(&head, 10);
insertFront(&head, 20);
insertFront(&head, 30);
printf("연결 리스트 출력: ");
printList(head);
// 노드 삭제
deleteNode(&head, 20);
printf("노드 삭제 후 출력: ");
printList(head);
return 0;
}
// 연결 리스트의 맨 앞에 노드 삽입
void insertFront(Node** head, int value) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = value;
newNode->next = *head;
*head = newNode;
}
// 특정 값 가진 노드 삭제
void deleteNode(Node** head, int key) {
Node* temp = *head, *prev = NULL;
if (temp != NULL && temp->data == key) {
*head = temp->next;
free(temp);
return;
}
while (temp != NULL && temp->data != key) {
prev = temp;
temp = temp->next;
}
if (temp == NULL) return;
prev->next = temp->next;
free(temp);
}
// 연결 리스트 출력
void printList(Node* head) {
Node* temp = head;
while (temp != NULL) {
printf("%d -> ", temp->data);
temp = temp->next;
}
printf("NULL\n");
}📌 실행 결과 예시
연결 리스트 출력: 30 -> 20 -> 10 -> NULL
노드 삭제 후 출력: 30 -> 10 -> NULL30 -> 20 -> 10 -> NULL순서로 추가됨20을 삭제한 후30 -> 10 -> NULL이 출력됨
📝 데이터 표현
- 컴퓨터는 모든 정보를 0과 1로 표현한다.
- 컴퓨터의 저장장치가 비트 단위로 구성되어 있기 때문이다
- 비트란, On과 Off상태만 표현할 수 있는 정보 단위이다.
-
부동 소수점: 컴퓨터에서 실수(Real Number)를 표현하는 방식
- 부호(Sign): 양수(0) 또는 음수(1)를 표현하는 부분
- 지수부(Exponent): 소수점 위치를 나타내는 부분
- 가수부(Mantissa or Fraction): 숫자의 정밀도를 나타내는 부분
-
컴퓨터가 읽고, 표현할 수 있는 문자의 모음인
문자 셋 charcter set이 있다- 문자 인코딩
- ex) UTF-8, 아스키코드, ...
📝 스레드 풀링
- 스레드는 프로세스의 작업을 나누어 관리하는 유용한 도구지만 스레드가 너무 많아지는 것은 바람직하지 않다.
- 스레드의 생성과 소멸은 시스템에 많은 부담을 준다.
- 스레드 풀은, 특정 개수의 스레드가 여러 개의 일을 차례대로 수행하는 기법이다.
# 개념은 같은 프로세스 풀 예제
import concurrent.futures
import time
def task(name) :
time.sleep(0.5)
return f"{name}의 작업 완료"
if __name__ == "__main__" :
with concurrent.futures.ProcessPoolExecutor(max_workers=3) as executor :
future_name = {executor.submit(task, f"Task-{i}") : f"Task-{i}" for i in range(5)}
print(future_name)
# 작업 완료된 순서대로 결과 출력, 작업이 들어간 순서대로 처리하지 않을 수도 있음
for future in concurrent.futures.as_complted(future_name):
name = future_name[future]
try :
result = future.result()
print(f"{name}의 결과 : {result}")
except Exception as e:
print(e)📝 라운드로빈 모델
선입 선출이지만 정해진 시간 만큼만 일하는 것
def roundrobin(processes, busrt_time, time_quantum) : n = len(processes) remaining_time = list(burst_time) turnaround_time = [0] * n waiting_time = [0] * n
time = 0
queue = []
while True :
all_completed = True # 모든 프로세스 종료 시 반복문 종료를 위한 플래그
for i in range(n) :
if remaining_time[i] > 0:
all_completed = False
if remaining_time[i] > time_quantum :
time += time_quantum
remaining_time[i] -= time_quantum
queue.append(i)
else :
time += remaining_time[i]
turnaround_time[i] = time
remaining_time[i] = 0
waiting_time[i] = turnaround_time[i] - burst_time[i]
if all_completed:
break
print("Process\tTurnaround Time\tWaiting Time")
for i in range(n):
print(f"P{i+1}\t\t{turnaround_time[i]}\t\t{waiting_time[i]}")함수 호출
processes = [1, 2 ,3]
burst_time = [10, 5, 8]
time_slice = 2
roundrobin(processes, burst_time, time_slice)
