
👀 1. 들어가며
우리 서비스를 사용하는 고객을 분류하여 맞춤형 액션을 제시하는 것은 매우 중요합니다. 저 역시 배달 물류 플랫폼 회사에서 분석가로 일하면서, 우리 회사의 주요 고객인 라이더를 어떻게 나눌 수 있을지 고민하고 있습니다. 기존에 사용하고 있는 세그먼트를 어떻게 고도화할지, 혹은 새로운 서브 세그먼트를 만들어 기존 세그먼트와 함께 활용할 방법에 대해서도 많은 생각을 하는데요.
이 고민을 하면서 다른 회사 사례도 궁금하여 찾아봤습니다. 가장 많은 사례에 나온 것은 전통적인 세분화 방식인 RFM 방식인데요. 저희 서비스 특성상 RFM 방식이 맞지 않은 부분들이 있어서, RFM방식이 아니라 서비스의 핵심 지표를 토대로 세그먼트를 분류한 사례가 궁금했어요.
- Recency (최근성): 고객이 얼마나 최근에 구매했는지?
- Frequency (빈도) : 고객이 얼마나 자주 구매했는지?
- Monetary (금액) : 고객이 얼마나 많은 금액을 사용했는지?
기술 블로그를 찾아보다가 에어비앤비에서 숙소를 제공하는 '호스트' 유형을 세분화한 사례에 대한 글을 읽게 됐습니다. (에어비앤비는 숙소를 제공하는 호스트와 숙소를 이용하는 게스트를 연결해주는 서비스입니다)

에어비앤비는 RFM 방식이 아닌, 시간 기반으로 예약하는 서비스의 특성을 반영한 핵심 지표를 선정하고 이를 기반으로 세그먼트를 분류했습니다. 그들은 k-means clustering을 활용하여 8개의 호스트 유형으로 세분화한 뒤, 이를 어떻게 검증했고 전사적으로 어떻게 상용화했는지에 대한 내용을 설명했는데요.
오늘 글에서는 에어비앤비가 '호스트'를 세분화 한 방법을 번역하여 소개하고자 합니다. 에어비앤비 기술 블로그에 작성된 글을 스터디하면서 이해하기 쉽게 설명도 추가해서 정리했는데요. 작성자가 쓴 그대로 이해하고 싶으신 분들은 원문 확인하시는 것을 추천드립니다! 원문 : From Data to Insights: Segmenting Airbnb’s Supply
이 글에는 모델링 방법론이 아닌 어떤 논리로 지표를 선정했는지에 대한 내용이 담겨있어서, 기술적인 방법보다는 지표를 선정한 논리가 궁금하신 분들에게 추천드립니다.
❓ 2. 에어비앤비(airbnb)는 숙소를 제공하는 '호스트'를 어떻게 세분화 했을까?
에어비앤비에는 숙소 제공자인 '호스트'와 숙소 이용자인 '게스트'가 존재하는데요. '게스트'로 이용을 시도해보셨으면 느끼셨을거예요. 다양한 숙소가 존재할 수록 에어비앤비에 오래 머물게 되고, 그 중 후기와 높은 별점을 가진 곳을 예약하고 만족하면 다시 찾게 된 경험이요. 에어비앤비는 '호스트'가 많을 수록 더 많은 '게스트'를 유지할 수 있고, '호스트'의 서비스와 품질이 높을 수록 에어빈앤비의 신뢰도와 이용 가능성이 높아집니다. '호스트'에게 받는 수수료는 수익원이기도 하고요.
여기 Alice와 Max라는 두명의 '호스트'가 존재합니다. 이들은 동일하게 프랑스 파리에 2-bedroom 아파트를 에어비앤비에 등록했는데요. Alice는 여름에만 숙소를 임대하지만 Max는 일년 내내 숙소를 임대하고 있어요.

이들의 운영 스타일은 매우 다른데요. Alice는 에어비앤비에 등록한 아파트에 계속 거주하면서 여름에만 숙소를 임대하는 유형일 가능성이 높기에 에어비앤비는 계절별로 어떻게 가격을 책정하는 게 좋은지, 시즌 성으로 임대하는 사람들을 위한 온보딩 가이드 등을 제공할 수 있을 거예요.
반면에 Max는 일년내내 숙소를 임대하며 수입원으로 활용 하는 유형일 가능성이 높기에, 에어비앤비는 여러 예약을 어떻게 잘 관리할 수 있을지, 수익이나 세금 관련 가이드 등을 제공할 수 있습니다.
이렇게 에어비앤비는 '호스트'를 잘 이해하고 개별화된 전략으로 대응하며 '호스트'가 계속해서 에어비앤비를 이용할 수 있도록 세분화를 진행했습니다. '호스트'의 차이를 포착할 수 있는 (2.1) 데이터 셋을 만들고, (2.2)K-means clustering을 적용하여 클러스터를 8개로 나눈뒤, (2.3) 세그먼트를 검증하며 (2.4) 검증 한 결과를 확장하고 상용화 했습니다. (2.5) 상용화한 결과를 어떻게 에어비앤비 내에서 활용하고 있는지도 소개하고 있습니다.
2.1. 데이터셋 만들기
(1) 이용 가능 비율 (Availability Rate)(%)
첫 번째 지표는 '이용 가능 비율 (Availability Rate)(%)'인데요. '호스트'가 1년(365일) 동안 얼마나 자주 숙소를 제공했는지 비율을 계산한 지표입니다.
이용 가능 비율 (Availability Rate)(%) = (이용 가능했던 날(빈숙박일 + 예약된 숙박일) / 365) X100
- 빈 숙박일 (Nights Vacant): 에어비앤비에 예약 가능한 상태로 등록되었지만, 실제로 예약되지 않은 날들
- 예약된 숙박일 (Nights Booked): 에어비앤비에 예약 가능한 상태로 등록되었고, 실제로 예약이 이루어진 날들
'이용 가능 비율'로 호스트가 얼마나 자주 숙소를 제공할 수 있는지 알수 있어요. Alice는 여름 한 달 만 제공해서 이용가능 비율이 8%((30/365)x100)인데, Max는 일년내내 제공하니 이용 가능 비율은 100%((365/365)x100)입니다.
작년의 숙소를 '이용 가능 비율'로 시각화해 봤을 때, 아래와 같은 그래프가 나왔다고 가정해볼게요. 양극단에 있는 이용 가능 비율이 0%와 100%와 가까운 경우는 Alice와 Max사례 처럼 쉽게 해석할 수 있을거예요. 하지만 중간 범위에 속하는 경우는 어떻게 해석할 수 있을까요?
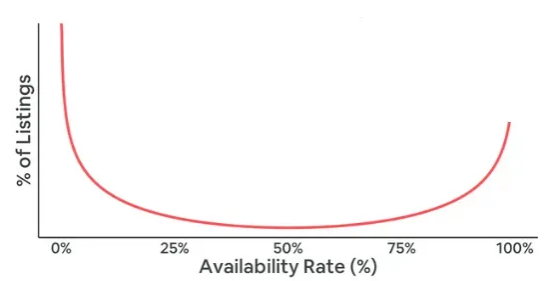
(2) 연속성(Streakiness) 비율(%)
'이용 가능 비율' 만으로 중간 범위에 속하는 숙소 유형의 세부적인 차이를 해석하기는 어려워요. 예를 들어 A와 B라는 두 숙소가 있습니다. 두 숙소 모두 특정 월의 '이용 가능 비율'이 50%입니다. '이용 가능 비율' 지표만 보면 두 숙소는 비슷한 유형으로 여겨지겠지만 패턴을 보면 전혀 다를 수 있습니다.
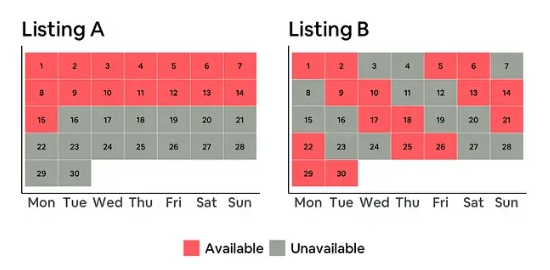
- 숙소 A : 한 달 중 일부 기간에만 집중적으로 이용 가능합니다.
- 숙소 B : 매주 일정한 빈도로 이용 가능합니다.
이렇게, 두 숙소의 '이용 가능 비율'이 같더라도 실제 제공되는 패턴이 전혀 다를 수 있습니다. 숙소 A를 운영하는 '호스트'에게는 주간으로 숙박을 예약할 경우 할인을 해주도록 추천할 수 있지만 이는 숙소 B를 운영하는 '호스트'에게는 적합하지 않은 제안일 수 있어요. '이용 가능 비율'로 확인 할 수 없는 차이를 이해할 수 있도록 '연속성(Streakiness)'이라는 개념을 도입했습니다.
연속성(Streakiness) 비율(%) = (연속성/ 이용 가능했던 날(빈숙박일 + 예약된 숙박일)) X100
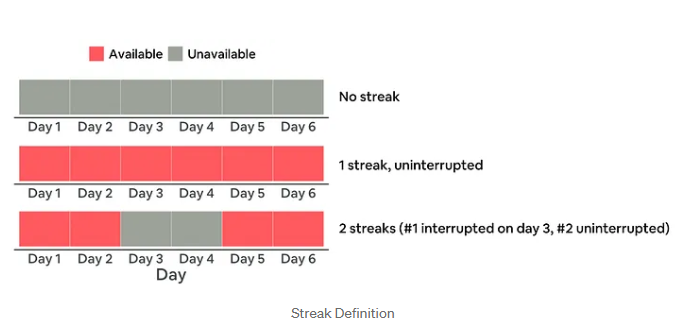
- 연속성: 최소 2일 이상, 연속으로 예약 가능한 날이 이어지는 구간 수
'이용 가능 비율'이 50%로 동일했지만, 이용 가능한 패턴이 달랐던 두 숙소의 '연속성 비율'을 계산하면 다음과 같습니다.
- 숙소 A : 연속성 비율(%)은 6% (1/16 *100)
- 연속성 : 16일 동안 예약가능 한 날이 이어졌기에 연속성은 1
- 이용 가능했던 날 : 16일
- 숙소 B : 연속성 비율(%)은 50% (8/16 *100)
- 연속성 : 2일 동안 예약가능 한 구간이 8번이어서 8
- 이용 가능했던 날 : 16일
'연속성' 지표를 사용하여 '이용 가능 비율'로만 설명할 수 없었던 숙소가 어떻게 예약 가능한지 패턴을 더 정확하게 구분할 수 있게 됐어요. 에어비앤비는 '이용 가능비율'과 '연속성 비율'이라는 두가지 지표를 결합해서 '호스트'과 관리하는 숙소에 대해 더 깊이 이해하고 세밀한 분석이 가능해지게 만들었어요 예를 들어, 어떤 '호스트'는 '이용 가능 비율'이 높지만 '연속으로 예약가능 한 날'이 이어지지 않을 수 있고, 다른 '호스트'는 '연속으로 예약가능 한 날'이 일정하고 꾸준히 나타날 수 있는데요. 이렇게 두 가지 특성을 함께 고려하면 '호스트'의 행동을 더 정확하게 이해하고, 그에 맞는 전략을 제시할 수 있습니다.
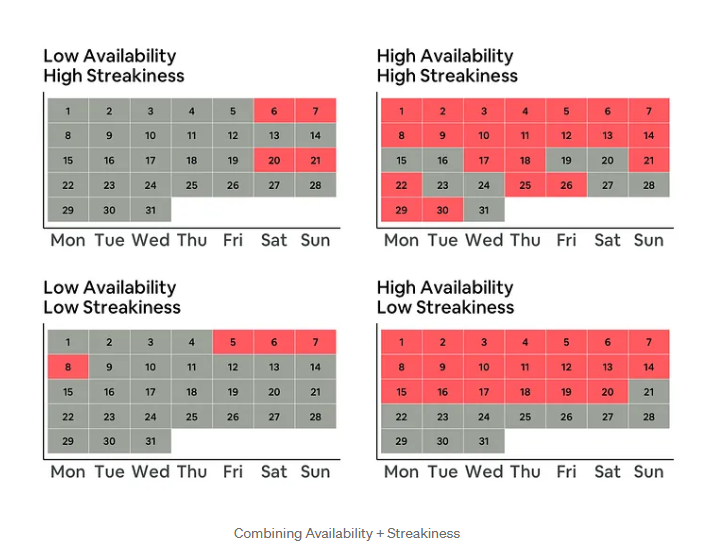
(3) 시즌성 (Seasonality)
'이용 가능 비율'과 '연속성 비율'은 '호스트'가 얼마나 자주, 어떤 패턴으로 숙소를 제공했는지 측정하는데 좋은 기준이 되지만, 캘린더에서 특정 계절에 몰려있는지 넓게 분포되어있는지는 계절성을 반영하지는 못합니다.
숙소 C와 숙소 D는 각각 약 15%의 '이용 가능 비율'과 14개의 '연속성'을 가지고 있지만, 그들의 예약 가능 기간은 다릅니다.

- 숙소 C : 6~8월 여름 시즌이라는 좁은 기간에 예약이 가능합니다.
- 숙소 D : 여러 분기(여러 시즌) 에 걸쳐 고르게 예약이 가능합니다.
시즌성은 에어비앤비 비즈니스에서 중요합니다. '게스트' 수요와 '호스트'의 공급은 계절, 휴일, 지역 행사 등의 영향을 많이 받기 때문입니다. 특정 계절이나 기간에는 여행 수요가 증가하거나 감소 할 수 있습니다. 예를들어 여름에는 바다나 산 등의 휴양지로 여행 가는 사람이 많아지고, 겨울에는 스키 리조트나 온천이 인기가 많을 거고, 연말, 추석, 설날 등 연휴를 활용하여 여행을 가는 사람이 많아 질거구요. 이런 시즌성에 따라 '게스트'의 수요가 달라지기 때문에 에어비앤비는 수요가 집중된 기간에 숙소 공급이 잘 이뤄지도록 해야하고, 더 많은 예약을 받을 수 있게 도와주는 것이 중요합니다.
'이용 가능 비율'과 '연속성 비율'은 동일하지만 시즌성 패턴이 다른 경우를 설명하기위해, 에어비앤비는 두 가지 지표를 도입했습니다.
'하루 이상 예약 가능 날짜가 있는 분기 수' (Quarters with at Least One Night of Availability):
- 숙소가 하루 이상 예약 가능 날짜를 갖고 있는 분기 수를 계산합니다.
'최대 연속 예약 가능 월 수' (Maximum Consecutive Months)
- 연간 기준으로 연속적으로 숙소가 예약 가능한 월 수를 계산합니다.
'이용 가능 비율'은 15%, '연속성'은 14개로 동일하지만, 예약 가능 기간이 달랐던 두 숙소의 '시즌성' 지표를 계산하면 다음과 같습니다.
- 숙소 C
→ '하루 이상 예약 가능 날짜가 있는 분기 수'는 6~8월인 2분기와 3분기에만 예약 가능하므로 2개
→ '최대 연속 예약 가능 월 수' : 6~8월(3개월) 동안 연속으로 예약 가능하므로 3개 - 숙소 D
→ '하루 이상 예약 가능 날짜가 있는 분기 수'는 모든 분기에 예약 가능하므로 4개
→ '최대 연속 예약 가능 월 수' : 1~8월(8개월) 동안 연속으로 예약 가능하므로 8개
'하루 이상 예약 가능 날짜가 있는 분기 수'와 '최대 연속 예약 가능 월 수' 로 숙소의 시즌성 패턴을 더 명확하게 이해할 수 있고,'호스트'에게 시즌을 고려한 효과적인 전략을 제안할 수 있게됩니다.
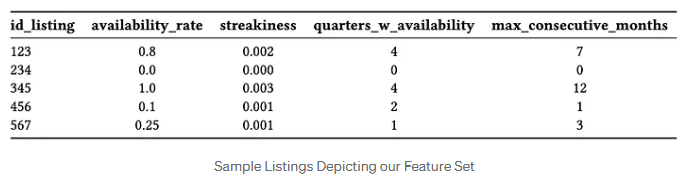
(4) 최종 데이터 셋
여러 날짜에 등록된 모든 숙소별로 각 지표를 계산하여 최종 데이터 셋을 만듭니다. 그리고 다양한 날짜 중에 랜덤으로 많은 샘플을 뽑고 서로 비교할 수 있도록 크기를 맞춥니다.
- 이용 가능 비율 (availability Rate) = (이용 가능했던 날(빈숙박일 + 예약된 숙박일) / 365) X100
- 연속성 (Streakiness) 비율 = (연속성/ 이용 가능했던 날(빈숙박일 + 예약된 숙박일)) X100
- 하루 이상 예약 가능 날짜가 있는 분기 수 (quarters_w_availability) : 숙소가 하루 이상 예약 가능 날짜를 갖고 있는 분기 수를 계산합니다.
- 최대 연속 예약 가능 월 수 (max_Consecutive_months) : 연간 기준으로 연속적으로 숙소가 예약 가능한 월 수를 계산합니다.
2.2. 세그먼트 모델
에어비앤비는 K-means clustering을 적용하여, 클러스터를 나눴습니다. k값을 2에서 10까지 테스트하여 Elbow plot을 사용해 8개로 나누는 것이 최적의 클러스터 수라는 것을 찾았습니다.
참고) 해당 용어에 대한 자세한 설명이 작성 된 블로그 링크 : https://ben8169.tistory.com/25
1) K-means clustering 이란? 데이터를 비슷한 특성을 가진 그룹(군집)으로 나누는 방법
2) Elbow plot 이란? 최적의 세그먼트 개수를 결정하는데 사용하는 방법 중 하나
8개 클러스터로 나눈뒤, 각 특징을 분석하고 유관 부서와 이야기 나누며 알맞은 이름을 정해줍니다.
- 각 클러스터의 지표 분포를 확인하면서 큰 차이가 보이는 특징을 찾습니다. 예를들어, "클러스터 1은 가장 높은 '이용 가능 비율을 보인다"는 식으로 특징을 파악합니다.
- 각 클러스터에서 몇개의 숙소를 random으로 샘플링하여, 예약 캘린더를 시각화하여 패턴을 파악합니다.
- 다양한 유관 부서와 이야기 나누며 각 클러스터의 이름을 계속 다듬고 수정해줍니다.
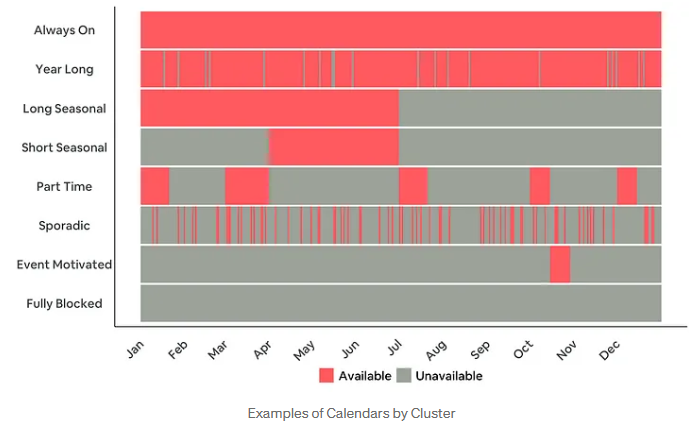
이 과정을 통해 각 클러스의 특징을 잘 나타낼 수 있는 이름을 정하고 예약 캘린더를 시각화하여 나타낸 에어비앤비의 클러스터는 아래와 같습니다.
| 이름 | 예약 가능성 패턴 | |
|---|---|---|
| 1 | 항상 열려 있음 (Always On) | 1년 내내 언제든지 예약 가능 |
| 2 | 연중 내내 (Year Long) | 거의 1년 내내 예약 가능 |
| 3 | 긴 시즌성 (Long Seasonal) | 긴 기간 예약 가능 |
| 4 | 짧은 시즌성 (Short Seasonal) | 짧은 기간 예약 가능 |
| 5 | 파트타임 (Part Time) | 예약가능 기간이 드물고, 공백이 많음 |
| 6 | 불규칙적 (Sporadic) | 예약가능 시기가 불규칙적임 |
| 7 | 이벤트 기반 (Event Motivated) | 특정 이벤트 때만 예약 가능 |
| 8 | 완전히 차단됨 (Fully Blocked) | 1년 내내 예약 불가능 |
2.3. 세그먼트 검증
세그먼트를 검증하면서 '호스트'의 행동 패턴이 우리가 정의한 것이 맞는지 확인하는 것은 중요합니다. 하지만 패턴은 정답이 없기에 완벽하게 검증은 불가능합니다. 그러나 세그먼트가 비즈니스 관점에서 합리적이고 실제 '호스트'의 패턴을 신뢰성있게 반영하는지를 확인하기 위해 에어비앤비는 세가지 방법을 사용했습니다.
2.3.1. A/B 테스트 (A/B Testing)
A/B 테스트에서는 각 세그먼트의 '호스트'가 에어비앤비가 제공하는 '추천 행동' 기능을 어떻게 사용했는지 평가했습니다. '추천 행동'은 '호스트'와 '게스트'가 더 나은 경험을 할 수 있도록 돕기위해 에어비앤비가 제공하는 기능인데요. 제안을 완료하면 인센티브를 받을 수 있어요. '호스트'를 대상으로 하는 '추천 행동'에는 이런 것들이 있어요.
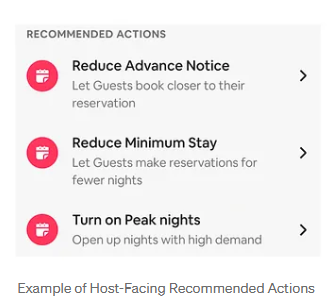
- 숙박 전 미리 예약 가능 조건 시간을 줄이세요.
→ 예를 들어, 현재 게스트가 숙박 전 7일 이전에 미리 예약해야 한다면, 2-3일 전 예약까지 가능하도록 예약 가능한 조건을 줄이세요 - 최소 숙박일 수를 줄이세요.
→ 예를 들어, 최소 3박을 요구하고 있다면 이를 1박 또는 2박으로 줄여서, 게스크가 더 짧은 기간으로도 예약할 수 있도록 하세요 - 게스트 수요가 높은 날짜의 예약을 열어두세요.
→ 지역 이벤트, 공휴일, 성수기 등 수요가 높은 날짜에 숙소 예약을 열어두세요!
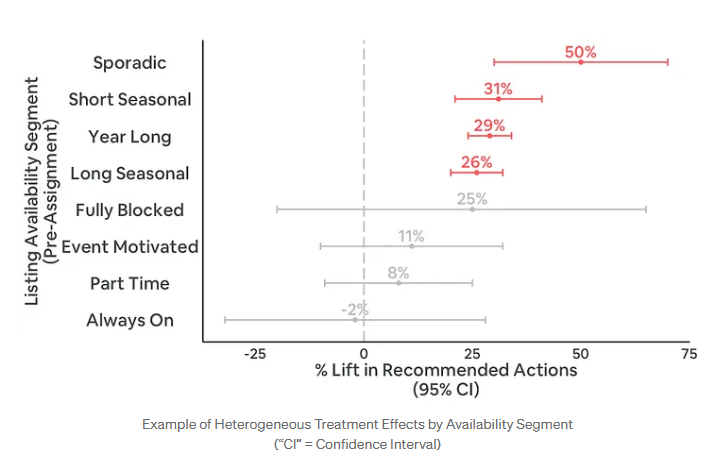
각 세그먼트 별로 '추천 행동'을 얼마나 사용했는지 결과 예시(그래프) 인데요. 이 결과는 에어비앤비가 생각한 것과 일치했어요. 예를 들어, 특정 경우에만 에어비앤비를 사용하거나, 드물게 사용하는 '호스트(파트타임 (Part Time), 이벤트 기반 (Event Motivated))' 는 인센티브를 제공받더라도 '추천 행동'을 따르는데 관심이 없을 수 있어요. '항상 열려있는(Always On) 호스트'도 이미 숙소를 관리하는 데 적극적이고 능동적이기 때문에 에어비앤비의 제안을 따르기보다는 자신만의 전략을 선호할 수 있습니다. '참여 수준이 중간 정도인 호스트(불규칙적 (Sporadic), 짧은 시즌성 (Short Seasonal), 연중 내내 (Year Long), 긴 시즌성 (Long Seasonal))'야 말로 성과를 높이고 인센티브를 받을 수 있는 활동에 관심이 많아 대상으로 적합합니다.
2.3.2. 세그먼트의 상관 관계
에어비앤비는 세그먼트 검증을 위해 각 세그먼트별로 주요 지표와의 상관 관계를 확인합니다. 예를 들어, '항상 열려있는(Always On) 호스트' 가 전문가에 의해 관리되는 경우가 많거나, '짧은 시즌성 (Short Seasonal) 호스트'가 스키나 해변 목적지에서 더 많이 나타날 가능성이 높다는 것을 확인합니다.
또한, '이벤트 기반 (Event Motivated) 호스트'가 주요 이벤트 기간에 접어들면서 증가하는 모습인지 관찰하며, 이는 이벤트 수요 증가에 반응하고 있는지 확인합니다.
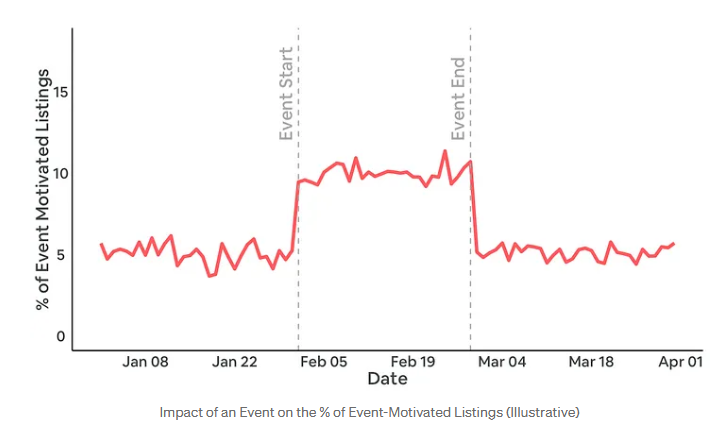
3. 사용자 경험(UX) 리서치
마지막으로, UX 연구 팀은 '호스트' 설문조사를 통해 정성적 페르소나를 만들고, 이를 클러스터와 비교하여 실제 행동과 일치하는지 확인합니다. 예를 들어, 주말 '이용 가능 비율' 높은 세그먼트가 주말 숙소 제공을 선호하는 '호스트'와 일치하는지 검증합니다.
2.4. 세그먼트 확장 및 상용화
세분화한 결과를 사용하기 위해선 모든 '호스트의 숙소'에 적용할 수 있어야합니다. 확장하고 상용화하기 위해 에어비앤비는 'Decision Tree Algorithm(결정 트리 알고리즘)'을 사용했습니다. 데이터를 나누는 규칙을 만들어서 빠르고 정확하게 분류할 수 있도록 하기 위해서인데요. 먼저 4가지 features(이용 가능 비율, 연속성비율, 하루 이상 예약 가능 날짜가 있는 분기 수, 최대 연속 예약 가능 월 수)를 사용하여 모델을 학습시키고, K-means 모델에서 얻은 클러스터 분류 결과를 출력값으로 사용합니다. 이후 모델이 각 클러스터를 정확하게 예측하는지 확인하기 위해 훈련 데이터 셋을 나눠 검증합니다.
새로운 모델은 간단하고 이해하기 쉬운 if-else 형태의 규칙을 제공하여, 각 숙소를 클러스터로 분류할 수 있게 해줍니다. 결정 트리 구조를 활용하여, 모델의 논리를 SQL 쿼리로 변환하는 작업을 수행하는데, 결정 트리의 'IF' 조건을 'CASE WHEN' 문으로 바꿉니다. 이렇게 만들어진 SQL쿼리를 데이터웨어하우스에 통합하여, 이 모델을 실질적으로 사용할 수 있도록 구현합니다!
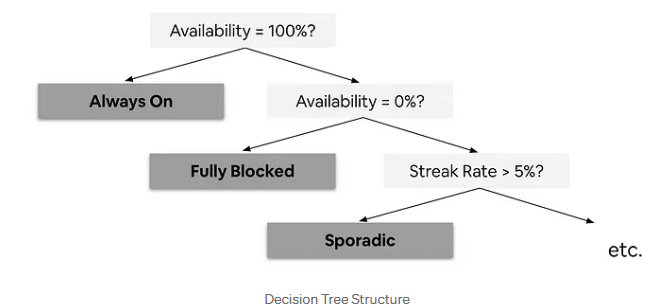
2.5. 에어비앤비와 그 외의 분야에서의 활용
에어비앤비에서는 다양한 팀들이 이 세그먼트를 활용하고 있습니다. 예를 들어, 제품 팀은 전략 수립과 A/B 테스트에서 다양한 결과를 분석하는 데 사용하고, 마케팅 팀은 타겟 메시징을 위해, UX 연구 팀은 '호스트'의 동기를 이해하는데 도움을 받습니다.
에어비앤비에서 활용하는 사례를 소개합니다.
- 즉시 예약(숙소 예약시 호스트 승인 없이 즉시 예약을 확정할 수 있는 옵션) 기능 활성화
'이벤트 기반 (Event Motivated) 호스트'는 가끔식 자신의 거주지를 등록하며, 게스트 선별을 수동으로 선호하는 경향이 있습니다. 이런 호스트들이 즉시 예약 기능을 더 활용할 수 있도록 하려면 "특정 평점 이상의 게스트만 허용" 하는 옵션을 추가하는 것이 효과적일 수 있습니다. 이 기능을 통해 호스트가 통제권을 유지하면서도 예약 효율성을 높일 수 있기 때문입니다. - 가끔 설정을 수정하는 설정 조정자와 자주 설정을 최적화 하는 호스트 구별
숙소 이용 가능 비율 데이터를 기반으로 처음 시작한 이 세그먼트를 방법론을 '호스트' 활동 데이터에도 적용을 했습니다. 에어비앤비는 '호스트 참여' 이루어진 날(예: 가격 조정, 정책 업데이트, 숙소 설명 수정)에 초점을 맞춰 두 번째 세분화를 만들었습니다. 이를 통해, 가끔 설정을 조정하는 '설정 조정자(Settings Tinkerers)'와, 자주 설정을 최적화하는 '설정 최적화자(Settings Optimizers)'를 구별할 수 있게 되었습니다.
에어비앤비는 시간 기반 참여를 하는 다른 산업에의 적용 아이디어도 함께 제안합니다.
- 소셜 미디어: 가끔씩만 활동하는 사용자(수동적인 사용자) vs 콘텐츠를 자주 제작하는 사용자(능동적인 사용자)
- 차량 공유 서비스: 피크 시간대에만 운전하는 드라이버 vs 풀타임으로 운전하는 드라이버
- 스트리밍 서비스: 밤에만 스트리밍하는 사용자 vs 지속적으로 스트리밍하는 사용자
- 이커머스: 세일/휴일에만 쇼핑하는 사람들 vs 연중 내내 쇼핑하는 사람들
🙌 3. 정리하며
에어비앤비의 글에서, 시간 기반 참여가 중요한 비즈니스에서 어떻게 적합한 지표를 선정하고, 그 지표로 설명할 수 없는 부분은 어떻게 다른 지표로 보완하는지에 대한 부분이 특히 재밌었습니다. 저희 서비스 역시 시간 기반 참여가 매우 중요한 서비스라, 우리 서비스에서 어떻게 활용할 수 있을지 아이디어도 얻을 수 있었구요.
뿐 만아니라 세그먼트를 어떻게 상용화했는지 과정도 흥미로웠는데요. 단순히 세그먼트를 나누는 것만으로 끝나는 것이 아니라, 그 세그먼트를 실제로 활용하기 위해 어떻게 단순화하고 데이터에 반영했는지 알 수 있어 도움이 많이 됐습니다.
오늘은 좋은 글을 소개했지만, 저도 나중에 이런 글을 꼭 쓰고 싶다는 마음이 드네요. 여러분도 이 글을 통해 서비스에 반영할 수 있는 아이디어를 얻으셨길 바랍니다!
