메타(Meta)가 손목 밴드를 착용하고 손목이나 손가락의 작은 움직임만으로도 마우스 조작과 키보드 입력이 가능한 혁신적인 기술을 발표했습니다. 이 기술은 우리 몸이 만들어내는 아주 미세한 전기신호를 읽어내 컴퓨터와 소통하는 방식을 근본적으로 바꿀 잠재력을 가지고 있는데요. 손가락으로 허공이나 책상 위에 글씨를 쓰면 그대로 화면에 입력되는 미래가 현실로 다가온 것입니다.
이와 같은 기술이 어떻게 가능했을까요? 바로 사람의 근육이 움직일 때 발생하는 전기적 활동을 외부에서 읽는 ‘근전도(electromyography, EMG)’ 덕분입니다. 기존의 뇌-컴퓨터 인터페이스(BCI)는 뇌파를 읽기 위해 침습적인 수술이 필요하거나, 개인 맞춤형 시스템으로 보정해야 하는 한계가 있었습니다. 하지만 메타의 연구팀은 비침습적으로, 즉 피부 표면에서만 근육의 전기신호를 읽어내어 손가락이나 손목의 움직임을 정확히 포착할 수 있는 손목밴드 형태의 디바이스를 개발한 것입니다.
이번에 발표된 연구는 학술지 《네이처(Nature)》에 게재된 논문에서 확인할 수 있습니다. 이 논문은 인간과 컴퓨터 사이의 상호작용 방식을 획기적으로 개선할 수 있는 비침습성 신경운동 인터페이스(neuromotor interface)를 소개하고 있습니다. 논문에 따르면, 기존의 인터페이스 기술들은 물리적인 입력장치(마우스, 키보드)나 카메라 같은 외부 센서에 의존해왔지만, 이러한 방식들은 이동 중 사용이 어렵거나, 움직임이 가려질 경우 제대로 작동하지 않는 등의 제약이 있었습니다.
연구팀은 근육이 움직일 때 발생하는 공통의 전기 신호를 AI로 분석하고, 이를 이용해 범용적이면서도 정확하게 움직임을 인식할 수 있는 모델을 개발했습니다. 덕분에 손목밴드만 착용하면 누구나 복잡한 설정 과정 없이 간편하게 컴퓨터를 조작할 수 있게 되었습니다. 이는 신경외과 수술이나 개인 맞춤형 보정이 필요했던 기존의 인터페이스 방식에 비해 훨씬 실용적이고 보편적인 해결책을 제공하는 셈입니다.
이처럼 혁신적인 기술이 주목받는 이유는 기존의 인간-컴퓨터 인터페이스(HCI) 기술들이 가지고 있던 한계를 명확히 극복했기 때문입니다. 그렇다면 과거의 기술들이 갖고 있던 문제점과 이번 연구가 어떻게 이를 해결했는지 조금 더 구체적으로 살펴보겠습니다.
서론 (Introduction)
컴퓨팅의 발전과 함께 인간은 표현력이 풍부하고 직관적이며 보편적인 컴퓨터 입력 기술을 끊임없이 추구해 왔습니다. 키보드, 마우스, 터치스크린 등 다양한 양식이 개발되었지만, 이는 장치와의 물리적 상호작용을 필요로 하며, 특히 이동 중인 시나리오에서는 제약이 따릅니다. 카메라나 관성 센서를 사용하는 제스처 기반 시스템은 중간 장치 없이 상호작용할 수 있지만, 움직임이 가려지지 않은 경우에만 잘 작동하는 경향이 있습니다.
반면, 신체의 전기 신호와 직접 인터페이스하는 뇌-컴퓨터(BCI) 또는 신경운동 인터페이스는 인터페이스 문제를 해결할 잠재력을 지녔지만, 고대역폭 통신은 현재까지 개인 맞춤형 디코더를 사용하는 침습성 인터페이스에서만 시연되었습니다. 이러한 침습성 인터페이스는 신경외과 수술을 필요로 하며, 신경 신호를 디지털 입력으로 변환하는 모델은 특정 개인에게만 최적화되어 있습니다. 비침습적 접근 방식인 뇌전도(EEG) 기반 시스템은 범용성이 높으나, 긴 설정 시간과 낮은 신호 대 잡음비(SNR)로 인해 활용이 제한적이었습니다. 전반적으로 신호 대역폭, 인구 집단 간 일반화, 개인별 또는 세션별 보정 회피는 BCI 분야의 주요 기술적 난제로 남아 있습니다.
본 연구는 고성능이면서도 접근성을 갖춘 인터페이스를 구축하기 위해 근전도(EMG)를 통해 근육의 전기 신호를 읽어내는 비침습성 신경운동 인터페이스에 초점을 맞춥니다. 표면 근전도(sEMG)는 근육 내 신경 신호를 증폭하여 높은 SNR을 제공하며 실시간 단일-시행 제스처 디코딩을 가능하게 합니다. sEMG 신호의 특성은 컴퓨터 비전 기반 접근 방식의 문제점(예: 가려짐, 불충분한 조명, 미미한 움직임의 제스처)을 겪지 않아 HCI 애플리케이션에 자연스럽게 적용될 수 있습니다. 그러나 기존 sEMG 시스템, 특히 보철 제어 시스템은 자세에 따른 낮은 견고성, 비표준화된 데이터, 전극 변위, 세션 간 및 사용자 간 일반화 부족 등 광범위한 사용을 위한 여러 제약 사항을 가지고 있습니다. 최근 딥러닝 기술이 이러한 한계를 일부 해결했지만, 충분한 EMG 데이터의 부재와 낮은 표본 크기가 그 효과를 제한하는 것으로 알려져 있습니다.
본 연구는 sEMG가 인구 전반에 걸쳐 직관적이고 끊김 없는 컴퓨터 입력을 제공할 수 있다는 가설을 검증하기 위해, 손목에서 sEMG를 기록할 수 있는 견고한 비침습성 하드웨어(sEMG 연구 장치, sEMG-RD)를 개발했습니다. 손목은 인간이 주로 손을 사용하여 세상을 탐색하고, 손, 손목, 전완근의 sEMG 신호를 폭넓게 포착하며 사회적으로 수용 가능하다는 장점이 있습니다. 이 장치는 건식 전극, 다채널 기록 플랫폼으로, 단일 운동 단위 활동 전위(MUAP)를 추출할 수 있습니다. 수천 명의 참가자로부터 훈련 데이터를 수집하기 위한 확장 가능한 인프라와 자동화된 행동 안내 및 참가자 선택 시스템을 구축했습니다. 이를 통해 사람 간에 일반화되는 범용 sEMG 디코딩 모델을 개발했습니다.
이 모델은 개인별 훈련이나 보정 없이도 1차원 연속 탐색, 이산 제스처 감지, 필기 전사 등 다양한 컴퓨터 상호작용을 구동할 수 있음을 입증했습니다. 폐쇄 루프(온라인) 평가에서, 제스처 디코딩은 연속 탐색 작업에서 초당 0.66 타겟 획득, 이산 제스처 작업에서 초당 0.88 제스처 감지, 필기에서 분당 20.9 단어(WPM)의 성능을 달성했습니다. 또한 필기 모델의 디코딩 성능은 sEMG 디코딩 모델의 개인화를 통해 16% 추가 개선될 수 있음을 보여줍니다. 본 연구는 현재까지 알려진 신경운동 인터페이스 중 가장 높은 수준의 참가자 간 성능을 달성한 비침습적 고대역폭 인터페이스입니다.
관련 연구 (Related Work)
본 연구는 인간-컴퓨터 상호작용(HCI)과 뇌-컴퓨터 인터페이스(BCI)의 교차점에 위치합니다. HCI 분야에서는 컴퓨터 비전, 관성 측정 장치(IMU), sEMG, 생체 음향 신호, 전기 임피던스 단층 촬영, 전자기 신호, 초음파 빔포밍 등 다양한 감지 양식에 머신러닝 기반 솔루션을 적용하여 제스처 입력을 발전시키는 데 중점을 두었습니다. 본 연구와 가장 직접적으로 관련된 선행 연구는 단종된 상용 sEMG Myo 암밴드를 사용하여 600명 이상의 참가자 데이터셋에서 제스처 감지 및 손목 움직임을 활용한 것입니다. 그러나 현재까지 sEMG 기반 접근 방식은 대부분 오프라인으로 작동하거나 세션 내 또는 참가자별 보정이 필요하여 실제 활용에 제약이 있었습니다.
본 연구의 비침습성 sEMG 연구는 BCI와 밀접한 관련이 있습니다. EEG 기반 BCI 시스템(특히 스펠러)은 분당 100-300비트의 인상적인 비트율을 달성할 수 있지만 (본 연구의 필기 디코더는 분당 528비트), 신호 품질, 해석, 표준화된 하드웨어 또는 소프트웨어 부족으로 인해 일반적으로 다른 BCI 양식보다 성능이 뒤처집니다. 이에 따라 소규모 모델과 비교적 소규모 데이터셋(<50명 사용자)에 초점이 맞춰져 왔습니다.
(참고) sEMG란? - sEMG는 표면 근전도 검사(Surface Electromyography)의 약자로, 근육의 전기적 활동을 피부 표면에서 측정하여 기록하는 검사입니다. 주로 근육의 움직임이나 상태를 분석하여 근육의 기능, 피로도, 신경계 문제 등을 파악하는데 사용됩니다.
피질내(intracortical) BCI는 더 높은 신호 대 잡음비를 제공하지만, 기록 및 세션 간 비정상성으로 인해 단일 참가자 연구로 제한되어 왔습니다. BCI 분야가 신경망 디코더로 전환되고 있지만, 여전히 제한된 데이터로 인한 보정 문제 해결에 중점을 두고 있습니다. sEMG 신호는 운동 단위 발화의 총합 활동에서 파생되므로, 본 연구에서 설명하는 sEMG 디코딩 방법이 피질내 BCI 시스템의 방법론 개발에 가이드 역할을 할 수 있습니다. 본 연구에서 시연된 대규모 접근 방식은 BrainGate, Neuralink와 같은 더 넓은 BCI 분야에 방향을 제시할 수 있습니다.
방법론 (Methodology)
1. 확장 가능한 sEMG 기록 플랫폼
본 연구는 범용 sEMG 디코딩 모델을 구축하기 위해 하드웨어 및 소프트웨어 플랫폼을 개발했습니다. Figure 1a에서 볼 수 있듯이, 참가자들은 손목에 sEMG 연구 장치(sEMG-RD)를 착용하고 컴퓨터 앞에서 다양한 손 및 손목 움직임을 수행하도록 안내받았습니다.
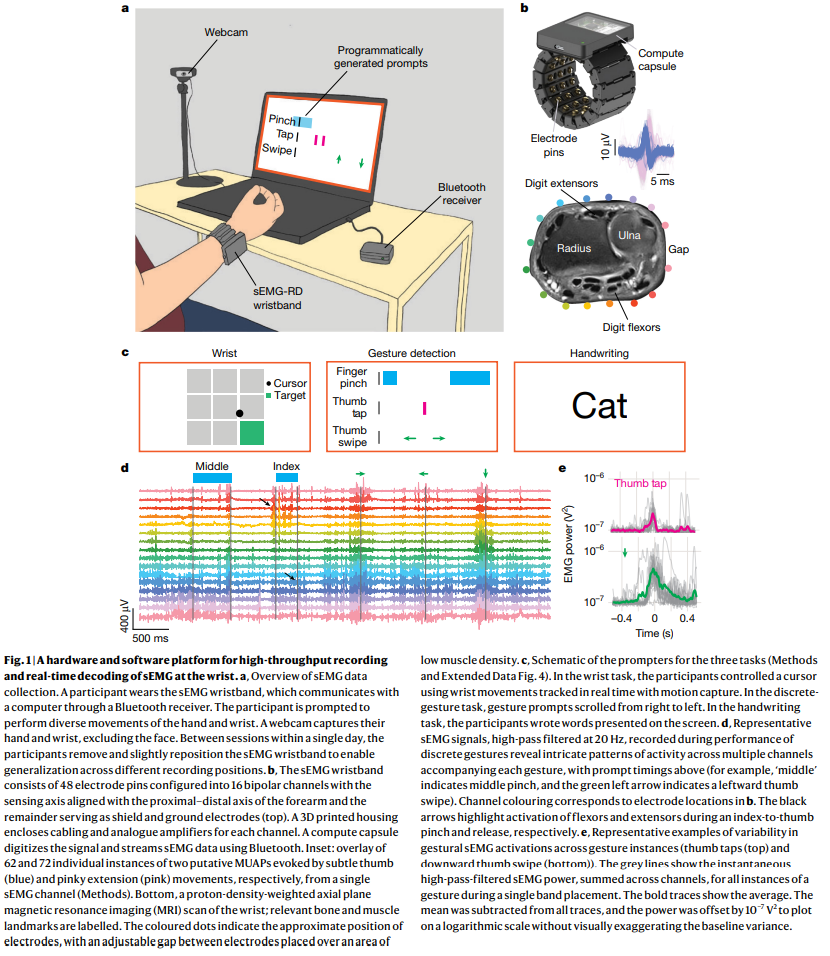
Fig. 1 | A hardware and software platform for high-throughput recording and real-time decoding of sEMG at the wrist
-
sEMG-RD 하드웨어: sEMG-RD는 건식 전극 방식의 다채널 기록 장치로, 2kHz의 높은 샘플링 속도와 2.46μVrms의 낮은 노이즈 특성을 가지며 일상적인 사용에 적합합니다. 이 장치는 4가지 다른 크기로 제작되어 다양한 손목 둘레를 수용합니다. 장치는 보안 블루투스 프로토콜을 통해 무선으로 스트리밍되며 4시간 이상의 배터리 수명을 제공합니다.
- Figure 1b는 sEMG-RD의 상세한 구조를 보여주며, 48개의 전극 핀으로 구성되며, 이 중 16개는 전완의 근위-원위 축과 정렬된 양극성 채널로 구성되고, 나머지는 차폐 및 접지 전극으로 사용됩니다. 이는 미세한 전기 전위를 기록하도록 최적화되었으며, 근육 밀도가 낮은 척골 부위에 전극 간 간격을 두어 조절 가능성을 확보했습니다.
-
데이터 수집 인프라: 수천 명의 참가자(작업에 따라 162명~6,627명)를 대상으로 인체 측정학적 및 인구 통계학적으로 다양하게 모집했습니다 (Extended Data Fig. 3 참조). 참가자들은 지배적인 손목에 sEMG 밴드를 착용하고 맞춤형 소프트웨어에 의해 세 가지 다른 작업을 수행하도록 안내받았습니다: 손목 제어, 이산 제스처 감지, 필기.
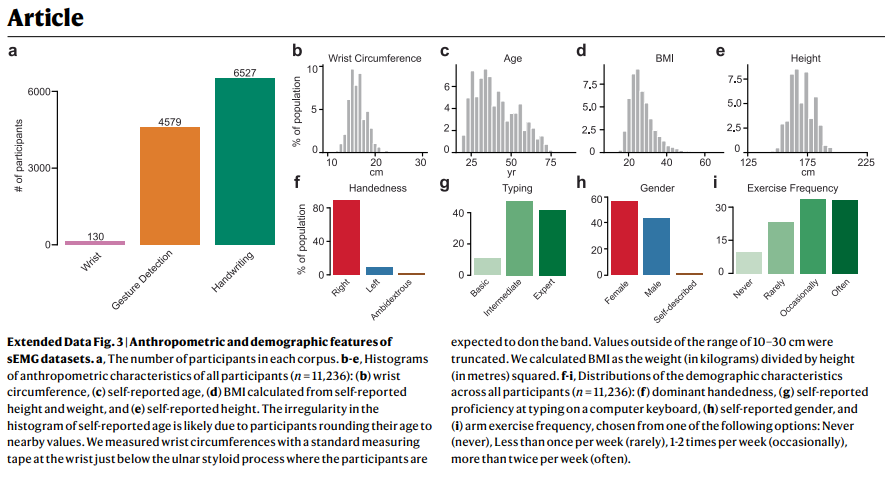
Extended Data Fig. 3 | Anthropometric and demographic features of sEMG datasets.
-
손목 제어: 참가자들은 모션 캡처로 실시간 추적되는 손목 각도에 따라 커서를 제어했습니다 (Extended Data Fig. 4a-c). 이는 개방 루프 및 폐쇄 루프 설정에서 굴곡-신전 손목 각도를 예측하도록 훈련되었습니다.
-
이산 제스처 감지: 참가자들은 무작위 순서와 제스처 간 간격으로 9가지 고유한 제스처를 수행하도록 지시받았습니다 (Extended Data Fig. 4d-e).
-
필기: 참가자들은 가상의 필기구를 쥐고 있는 것처럼 손가락을 모으고 제시된 텍스트를 "필기"했습니다 (Extended Data Fig. 4f-g). Figure 1c는 이 세 가지 작업의 프롬프터 스키마를 요약하여 보여줍니다.
-
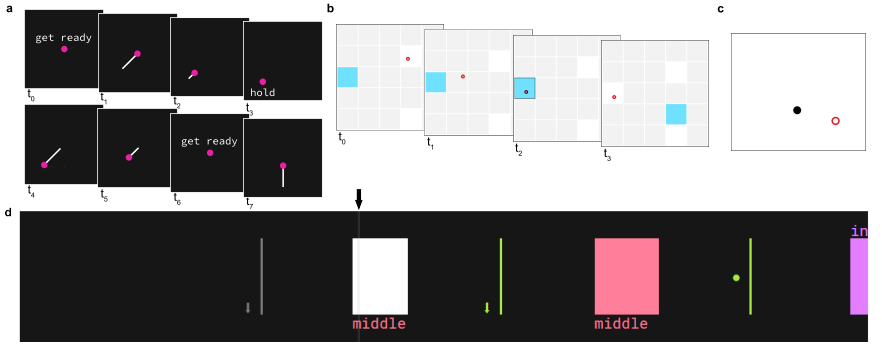
Extended Data Fig. 4 | Examples of prompting used to collect training data for the three tasks. a
- 데이터 처리 시스템: sEMG 활동과 안내 소프트웨어의 라벨 타임스탬프를 실시간 처리 엔진을 사용하여 기록했습니다. 이 엔진은 기록 및 모델 추론 중 온라인-오프라인 불일치(shift)를 줄이기 위해 설계되었습니다. 참가자의 반응 시간이나 순응도로 인해 발생할 수 있는 실제 제스처 시간과의 정확한 정렬을 위해 사후(post hoc) 제스처 이벤트 시간을 추론하는 시간 정렬 알고리즘을 개발했습니다.
- Figure 1d는 이산 제스처 수행 중의 원시 sEMG 트레이스를 보여주며, 복잡한 활동 패턴이 각 제스처에 수반됨을 나타냅니다. 또한 Figure 1e는 단일 세션 내에서도 제스처 인스턴스 간 sEMG 활성화의 변동성을 보여줍니다.
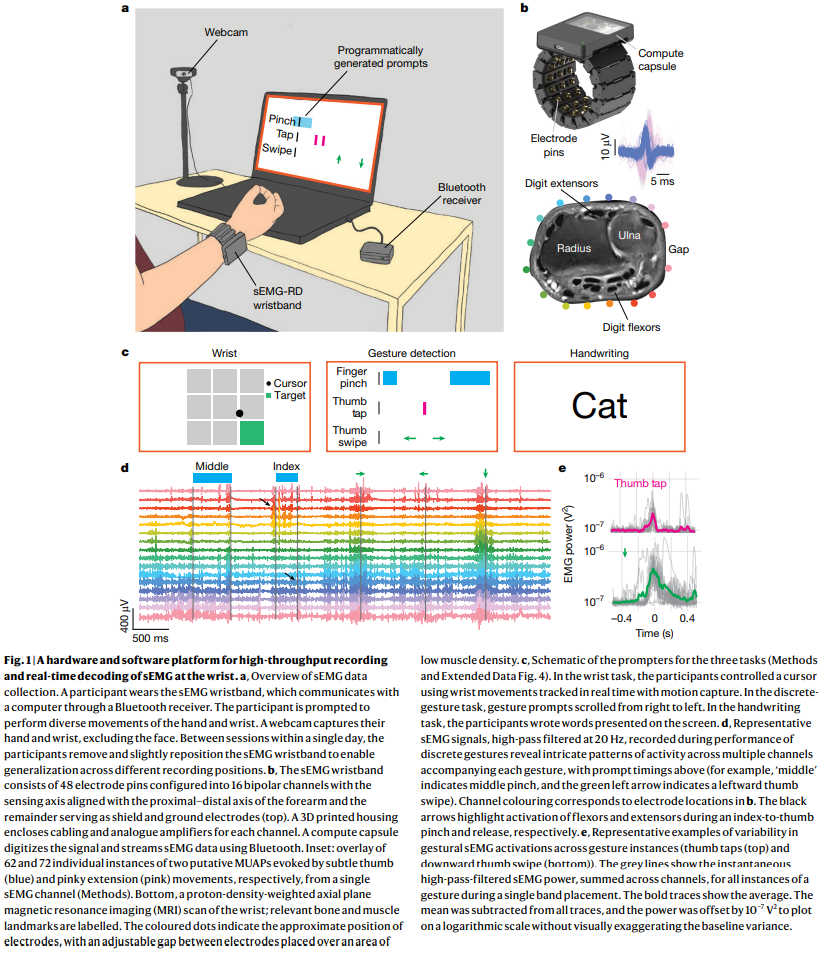
Fig. 1 | A hardware and software platform for high-throughput recording and real-time decoding of sEMG at the wrist
2. sEMG 전처리 (sEMG Preprocessing)
- 추정된 운동 단위 활동 전위(Putative MUAP) 파형 추정: 미세한 근육 수축에 의해 유도된 MUAP의 시공간 파형을 분석했습니다. Extended Data Fig. 2는 이 MUAP 추출 및 검증 과정을 상세히 설명합니다. sEMG 트레이스를 2차 Savitzky-Golay 미분 필터(폭 2.5ms)로 전처리한 후, 검출된 피크를 중심으로 20ms 길이의 창을 사용하여 MUAP를 추출했습니다.
Extended Data Fig. 2 | Extraction and validation of putative MUAPs.
-
다변량 전력 주파수(MPF) 특징: 손목 및 필기 디코더는 원시 sEMG에서 추출된 MPF 특징을 사용합니다. sEMG는 노이즈 표준편차를 1.0으로 정규화하기 위해 로 재조정되었습니다. 그 후 움직임 아티팩트를 제거하기 위해 40Hz 고역통과 필터(4차 버터워스)를 적용했습니다. sEMG 샘플의 롤링 창과 40 샘플(20ms)의 스트라이드(stride)를 사용하여 교차 스펙트럼 밀도(cross-spectral density)의 제곱 크기를 추출했습니다. 이를 6개의 주파수 빈(0-62.5, 62.5-125, 125-250, 250-375, 375-687.5, 687.5-1,000Hz)으로 묶고, 각 빈의 합의 절대값의 제곱을 취했습니다. 그 결과 50Hz의 출력 주파수로 40개 샘플마다 업데이트되는 6개의 대칭적이고 양의 정부호 16x16 정사각형 행렬이 생성되었습니다. 각 행렬에 로그 행렬 연산을 적용하고, 대각선 및 처음 세 개의 비대각선 성분(밴드가 원형임을 고려하여 행렬 가장자리에서 롤오버됨)을 보존하여 각 행렬에 대해 반-벡터화한 후 6개의 주파수 빈에 걸쳐 연결하여 각 80ms 창에 대해 384() 차원 벡터를 생성했습니다.
-
이산 제스처 시간 정렬: 안내된 제스처 실행의 대략적인 타이밍만 주어졌으므로, 레이블을 신호와 보다 정확하게 정렬하기 위한 알고리즘을 개발했습니다. 이산 제스처의 타이밍 불확실성이 겹치는 경우를 처리하기 위해, MPF 특징의 생성 모델에 따라 관찰된 데이터를 가장 잘 설명하는 제스처 타이밍 시퀀스를 탐색했습니다.
-
생성 모델은 개 제스처 인스턴스의 합으로 정의됩니다:
여기서 는 시간 경과에 따른 특징, 는 제스처 인스턴스 에 대한 원형 시공간 파형(제스처 템플릿), 는 해당 이벤트 시간, 는 노이즈 항입니다. 이 모델은 탄도적(ballistic) 제스처 실행 및 전력 기반 특징에 유효합니다.
-
최적화 문제는 다음과 같습니다:
이를 빔 탐색(beam search) 알고리즘을 통해 수치적으로 최적화했습니다.
-
마지막으로, 표준화를 위해 세션 템플릿과 글로벌 템플릿 간의 최대 상관 시간으로 전체 타임스탬프를 재중심화했습니다.
-
3. 범용 sEMG 디코더 모델링 (Generic sEMG Decoder Modelling)
세 가지 HCI 작업(손목 각도 예측, 이산 동작 인식, 필기 전사)은 서로 관련되면서도 구별되는 시계열 모델링 및 인식 작업입니다. 본 연구는 딥러닝 접근 방식을 사용하며, 음성 인식(ASR) 분야의 기술을 sEMG 도메인에 맞게 수정했습니다.
-
손목 디코더 아키텍처: MPF 특징을 입력으로 받습니다. 회전 불변 모듈(512개 은닉 유닛을 가진 완전 연결(FC) 계층, LeakyReLU 활성화 함수)을 통과하며, 이는 sEMG 채널을 이산적으로 +1, 0, -1 채널로 회전시켜 평균을 취함으로써 구현됩니다. 이후 512개 은닉 유닛을 가진 두 개의 LSTM 계층, LeakyReLU 활성화, 최종 1D 출력을 생성하는 선형 계층을 거칩니다. L1 손실 함수를 사용하고 Adam 옵티마이저로 300 에포크 동안 훈련했습니다.
-
이산 제스처 디코더 아키텍처: 재조정 및 고역통과 필터링된 sEMG 신호를 입력으로 받습니다. 아키텍처는 1D 컨볼루션 계층(2kHz에서 200Hz로 다운샘플링), 드롭아웃 계층(0.1), 레이어 정규화 계층, 세 개의 LSTM 계층(각각 0.1 드롭아웃), 두 번째 레이어 정규화 계층, 마지막으로 9가지 제스처의 확률을 예측하는 시그모이드 비선형성을 갖는 선형 읽기 계층으로 구성됩니다. Adam 옵티마이저와 경사 클리핑(gradient clipping)을 사용했으며, 다중 레이블 이진 교차 엔트로피 손실로 훈련했습니다.
-
필기 디코더 아키텍처: MPF 특징을 입력으로 받습니다. 손목 디코더와 유사하게 회전 불변 모듈을 통과합니다. 그 후 15개의 컨포머(Conformer) 계층으로 구성된 아키텍처를 거칩니다. 각 컨포머 계층은 4개의 어텐션 헤드와 크기 8의 시간-컨볼루션 커널을 포함합니다. 스트리밍 방식을 위해 수정된 컨포머 아키텍처를 사용했으며, 자기-어텐션은 현재 시간 단계 바로 이전의 고정된 국소 창에만 적용됩니다. 컨포머 블록의 출력은 채널 전반에 걸쳐 평균 풀링된 후 문자 사전에 해당하는 크기로 투영하는 선형 계층을 거치고, 그 위에 소프트맥스 함수가 적용됩니다.
CTC(Connectionist Temporal Classification) 손실 함수를 사용하여 모델을 훈련했으며, FastEmit 정규화 기술을 통합하여 스트리밍 지연 시간을 줄였습니다. AdamW 옵티마이저를 사용하고 코사인 어닐링(cosine annealing) 학습률 스케줄을 적용했습니다.
4. 개인화 모델링 (Personalized Modelling)
범용 모델의 성능을 특정 개인에 맞춰 개선하기 위해 필기 모델의 개인화를 연구했습니다. 범용 모델 훈련 데이터에 포함되지 않은 40명의 참가자를 대상으로, 해당 참가자의 추가적인 지도 학습 데이터(1, 2, 5, 10, 20분 예산)를 사용하여 범용 모델의 모든 매개변수를 미세 조정(fine-tuning)했습니다.
옵티마이제이션은 범용 훈련과 유사하게 진행되었으나, 웜업 없는 코사인 어닐링 학습률 스케줄을 사용하고, 학습률은 사전 훈련 참가자 수에 따라 조정되었습니다: . 가중치 감쇠(weight decay)는 사용하지 않았고, 300 에포크 동안 조기 종료 없이 미세 조정했습니다.
실험 (Experiments)
1. 단일 참가자 모델 일반화 (Single-participant models do not generalize)
단일 참가자 모델의 일반화 능력을 평가하기 위해, 이산 제스처 분류 작업에 대해 최소 5개 세션의 데이터를 수집한 100명의 참가자를 대상으로 실험했습니다. 각 참가자에 대해 1개 세션을 평가용으로 제외하고, 나머지 세션(2, 3 또는 4개)으로 모델을 훈련했습니다. 오프라인 평가 지표로는 거짓 음성률(False-Negative Rate, FNR)을 사용했습니다.
결과적으로, 동일 참가자 내 세션 간 일반화는 훈련 데이터가 많아질수록 크게 개선되었지만 (Figure 2c), 다른 참가자에게 훈련된 모델을 적용하는 참가자 간 일반화는 여전히 성능이 좋지 않았으며 훈련 데이터 증가에 따른 이득이 미미했습니다 (Figure 2d).
이는 세션 간보다 사람 간의 도메인 변화가 훨씬 크다는 것을 시사합니다. 이러한 사람 간 및 세션 간 sEMG의 현저한 변동성은 Figure 2a에서 시각적으로 확인됩니다. 참가자 98%는 자신의 데이터로 훈련된 모델이 다른 모든 단일 참가자 모델보다 우수했습니다 (Extended Data Fig. 5b). 참가자 쌍 간 평균 모델 전송 FNR의 t-SNE 임베딩은 명확한 참가자 클러스터가 없음을 보여주었습니다 (Figure 2b 및 Extended Data Fig. 5c).
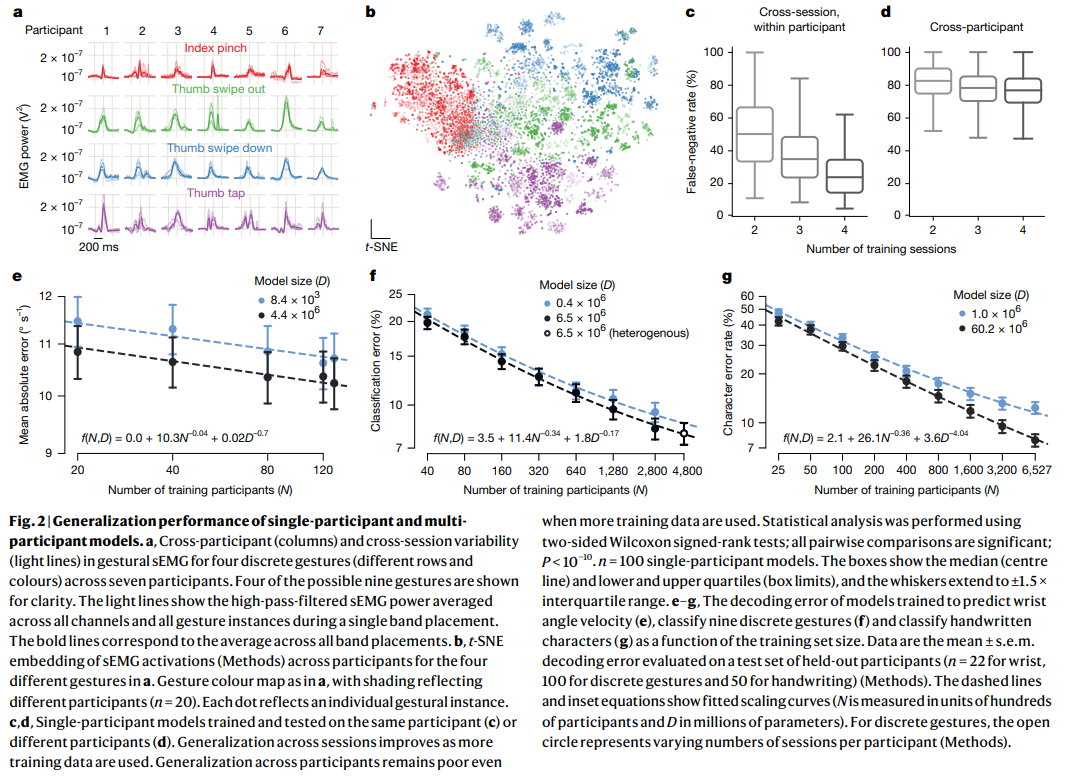
Fig. 2 | Generalization performance of single-participant and multiparticipant models
2. 범용 모델의 오프라인 평가 (Offline evaluation of generic models)
각 작업별로 수백에서 수천 명의 데이터 수집 참가자로부터 데이터를 수집하여 범용 모델을 훈련했습니다.
사용된 신경망 아키텍처는 다음과 같습니다:
- 손목 작업: 다변량 전력 주파수(MPF) 특징 및 LSTM 계층.
- 이산 제스처 작업: 1D 컨볼루션 계층 후 LSTM 계층.
- 필기 작업: MPF 특징 및 Conformer.
훈련 참가자 수에 따른 모델의 오프라인 디코딩 성능을 분석한 결과, 모든 작업에서 훈련 코퍼스에 참가자 수가 증가함에 따라 성능이 꾸준히 향상되었습니다 (Figure 2e-g). 이는 다른 도메인과 일관되게 매개변수와 데이터 양의 함수로서 지수 법칙(power law) 스케일링을 따랐습니다. 가장 큰 모델은 유망한 오프라인 성능을 보였습니다. MPF 특징이 RMS 전력 특징보다 손목 디코더 성능을 향상시킴이 Extended Data Fig. 6에 제시됩니다.
3. 범용 모델의 온라인 평가 (Online evaluation of generic models)
범용 sEMG 디코딩 모델의 폐쇄 루프(온라인) 성능은 컴퓨터 인터페이스로서의 실현 가능성을 확인하는 중요한 평가입니다. 각 작업에 대해 해당 sEMG 디코더 사용 경험이 없는 신규 참가자(손목: 17명, 이산 제스처: 24명, 필기: 20명)를 대상으로 평가를 수행했습니다. Figure 3a-c는 이 세 가지 폐쇄 루프 작업의 스키마를 보여줍니다. Extended Data Fig. 7은 실제 작업 스크린샷을 제공합니다.
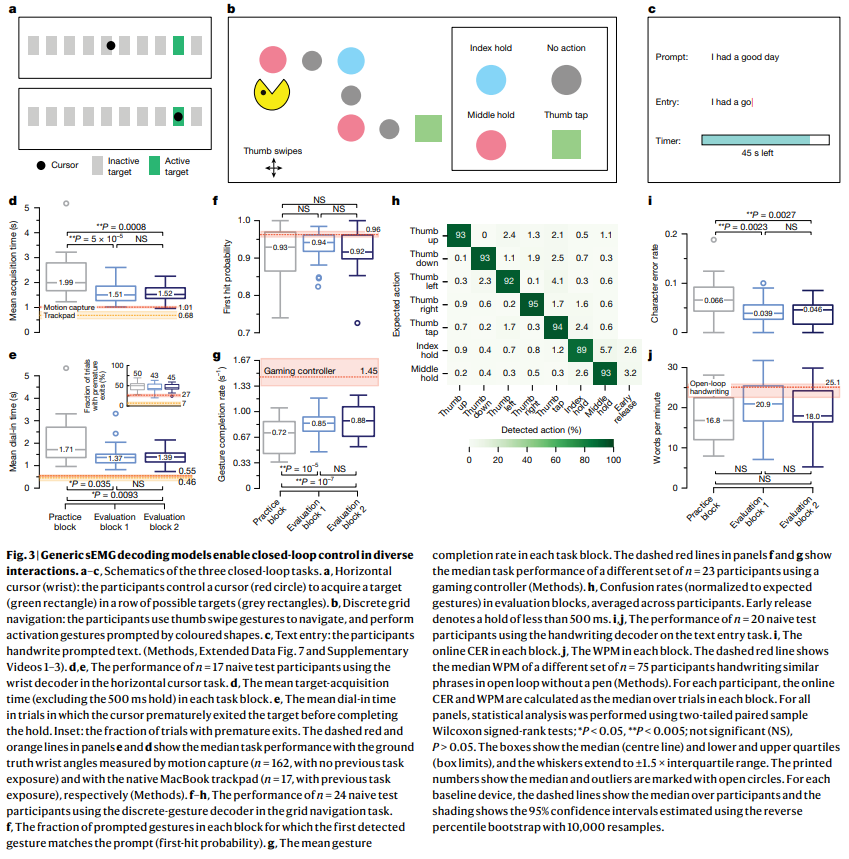
Fig. 3 | Generic sEMG decoding models enable closed-loop control in diverse interactions.
-
손목 제어: 1차원 커서를 연속적으로 제어하여 목표를 획득하는 작업.
- 성능 지표: 목표 획득 시간(Time to Target Acquisition), 재진입 시간(Dial-in Time).
- 결과: 참가자들은 연습 블록에서 평가 블록으로 가면서 두 지표 모두에서 개선을 보였습니다 (Figure 3d,e). Extended Data Fig. 8a는 Fitts's law 처리량(throughput)을 사용하여 이 작업을 추가로 평가한 결과입니다. 대부분의 참가자는 커서가 의도한 방향으로 >80% 움직였다고 주관적으로 보고했습니다 (Extended Data Fig. 8e).
-
이산 제스처: 그리드를 탐색하고 특정 동작(손가락 꼬집기, 엄지 스와이프)을 수행하는 작업.
- 성능 지표: 첫 번째 감지된 제스처가 안내된 제스처와 일치하는 확률(First Hit Probability), 제스처 완료율(Gesture Completion Rate), 혼동 행렬(Confusion Matrix).
- 결과: 모든 참가자가 스와이프 제스처로 탐색하고 활성화 제스처를 수행하여 작업을 완료할 수 있었습니다. 학습 효과가 관찰되었으며, 첫 번째 감지된 제스처가 일치하는 확률과 제스처 완료율 모두 개선되었습니다 (Figure 3f,g). 혼동 행렬은 모델 디코딩 오류와 행동 오류의 조합을 반영합니다 (Figure 3h).
-
필기 전사: 안내된 구문을 필기하여 화면에 시각화하는 작업.
- 성능 지표: 온라인 문자 오류율(Character Error Rate, CER), 텍스트 입력 속도(Words Per Minute, WPM).
- 결과: 참가자들은 연습을 통해 디코더로 정확하게 필기하는 데 효과적인 움직임을 발견할 수 있었고, CER 및 WPM 모두 개선되었습니다 (Figure 3i,j).
4. 범용 sEMG 디코더와 베이스라인 비교 (Comparison to HCI baselines)
각 상호작용에 대해 sEMG 디코딩에 의존하지 않는 베이스라인 인터페이스와 성능을 비교했습니다.
-
1차원 연속 제어: sEMG 손목 디코더(1.51초)는 MacBook 트랙패드(0.68초) 및 모션 캡처 기반 손목 제어(0.96초)보다 획득 시간이 길었습니다.
-
이산 그리드 탐색: sEMG 이산 제스처 디코더(초당 0.88 완료)는 Nintendo Joy-Con 게임 컨트롤러(초당 1.45 완료)보다 제스처 완료율이 낮았습니다 (Extended Data Fig. 8b-d 참조).
-
안내된 텍스트 입력: sEMG 필기 디코더(20.9WPM)는 펜 없이 표면에 필기하는 경우(25.1WPM)보다 속도가 느렸습니다(모바일폰 키보드 36WPM).
sEMG 디코더는 이러한 베이스라인 장치에 비해 개선의 여지가 있지만, 손을 방해하는 장치나 외부 계측 없이 각 작업을 안정적으로 완료할 수 있을 만큼 충분히 성능이 우수합니다. 온라인 평가 참가자의 인구통계학적 특성은 Extended Data Fig. 8f-i에 제시됩니다.
5. 이산 제스처 모델 학습 표현 분석 (Representations learned by the discrete-gesture model)
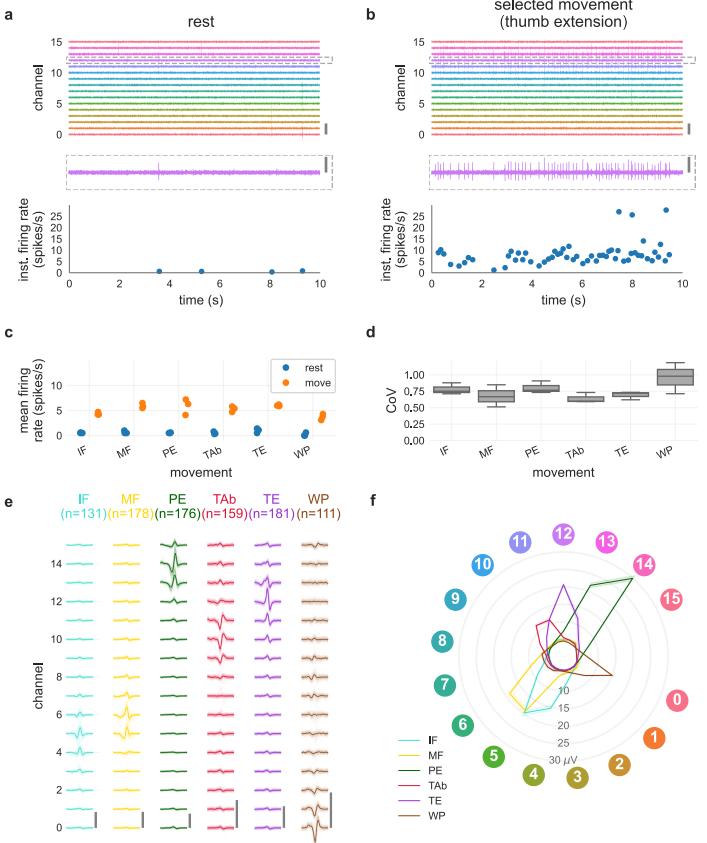
이산 제스처 디코더의 중간 계층에서 학습된 표현을 시각화하여 범용 sEMG 디코더의 작동 방식을 이해했습니다. 네트워크 아키텍처는 1D 컨볼루션 계층, 3개의 LSTM 계층, 최종 분류 계층으로 구성됩니다 (Figure 4a).
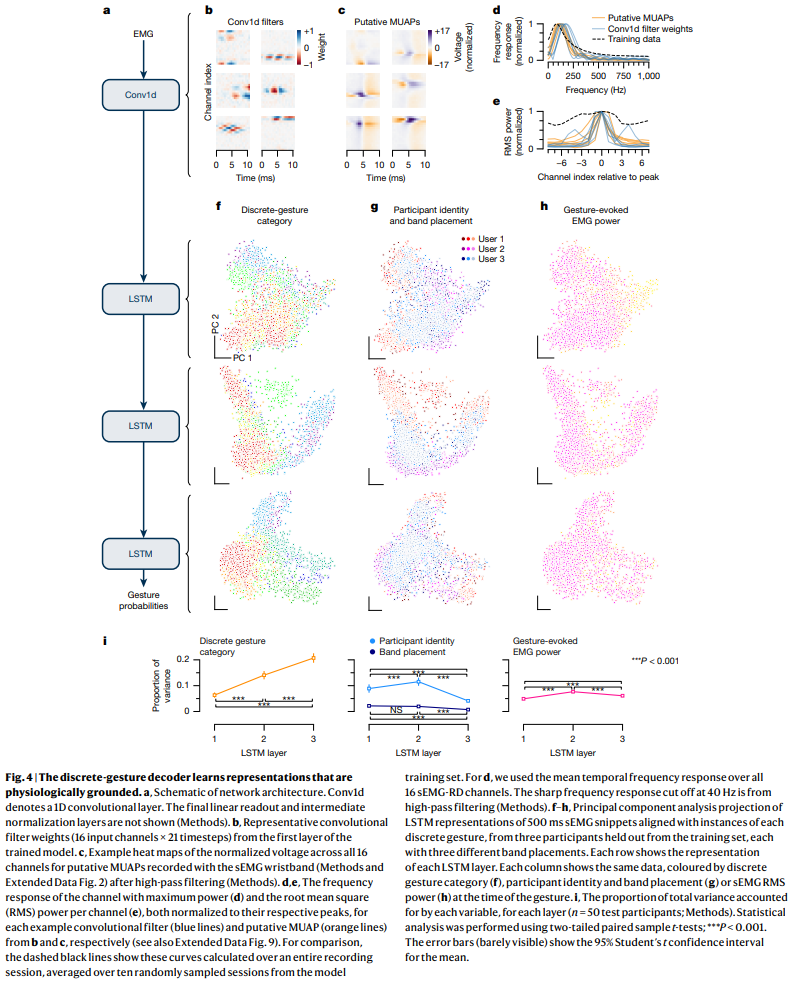
Fig. 4 | The discrete-gesture decoder learns representations that are physiologically grounded
-
컨볼루션 필터: 시공간 필터를 시각화한 결과 (Figure 4b), 이는 운동 단위 활동 전위(MUAP)의 통계적 특성을 포괄하는 대략적인 기저(basis set)를 형성하는 것으로 보입니다 (Figure 4c-e). Extended Data Fig. 9는 컨볼루션 필터와 MUAP 간의 유사성을 더 자세히 보여줍니다.
-
LSTM 표현: LSTM 은닉 단위 활동을 분석한 결과, 네트워크의 깊이가 깊어질수록 제스처 카테고리가 더욱 분리 가능해지는 경향을 보였습니다 (Figure 4f). 각 제스처의 표현은 더욱 밀접하게 클러스터링되었고, 참가자 식별, 밴드 배치, 제스처 유도 sEMG 전력과 같은 불필요한 변수(nuisance variables)에 대한 민감도는 줄어들거나 동일하게 유지되었습니다 (Figure 4g,h). 네트워크 깊이가 증가함에 따라 각 계층 표현의 분산 중 제스처 카테고리가 차지하는 비율이 증가했습니다 (Figure 4i). 요약하자면, 이 네트워크는 sEMG 표현을 불필요한 변수에 대해 더욱 불변하게 형성함으로써 작업을 학습합니다.
6. 필기 모델 개인화 (Personalizing handwriting models improves performance)
범용 모델을 개인화하면 특정 개인의 성능을 향상시킬 수 있음을 입증했습니다. 40명의 비포함 참가자 데이터셋을 사용하여 범용 모델의 매개변수를 추가 지도 데이터로 미세 조정했습니다. Figure 5a는 이 개인화 과정을 시각적으로 보여줍니다.
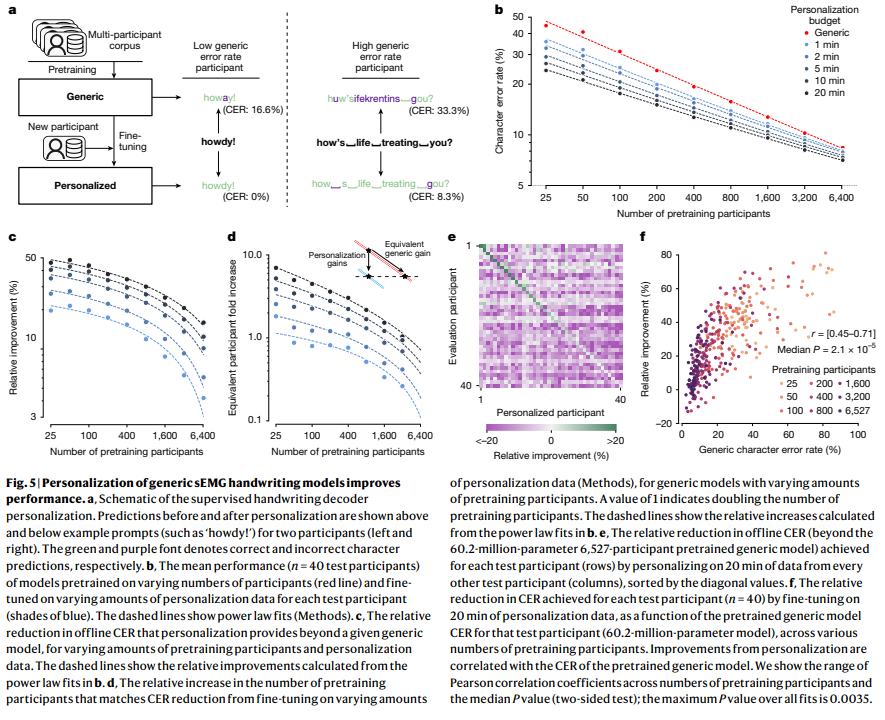
Fig. 5 | Personalization of generic sEMG handwriting models improves performance.
-
성능 개선: 미세 조정은 모든 추가 데이터 양과 모든 사전 훈련 참가자 수에 대해 평균 오프라인 CER을 개선했습니다 (Figure 5b). 6,400명의 참가자로 훈련된 범용 모델의 경우에도 20분의 개인화 데이터만으로 중앙값 성능이 16% 향상되었습니다 (Figure 5c).
-
수확 체감(Diminishing Returns): 개인화 데이터가 많을수록 사용자별 평균 CER이 더 감소했지만, 범용 모델이 더 많은 참가자 데이터로 사전 훈련될수록 개인화로 인한 절대 및 상대적 CER 개선은 감소하여 수확 체감 현상을 보였습니다 (Figure 5c).
-
코퍼스 확장 효과: 개인화는 목표 참가자의 CER을 감소시키기 위한 범용 코퍼스 크기 확장과 유사한 대안을 제공합니다 (Figure 5d). 예를 들어, 25명의 참가자로 사전 훈련된 모델의 경우 20분의 개인화 데이터는 다른 참가자로부터 14,000분(원래 코퍼스의 7배)의 추가 데이터로 범용 모델을 훈련하는 것과 동등한 효과를 보였습니다.
-
전이 학습(Transfer Learning): 개인화는 목표 참가자의 성능을 향상시켰지만, 다른 참가자에게는 전이되지 않고 오히려 성능에 부정적인 영향을 미치는 경우가 많았습니다 (Figure 5e).
-
취약 사용자 개선: 개인화는 모든 범용 모델에서 특히 성능이 낮은 참가자의 성능을 불균형적으로 개선했습니다 (Figure 5f). 조기 종료(early stopping)를 통한 개인화의 회귀 완화는 Extended Data Fig. 10에 제시됩니다.
고찰 (Discussion)
본 연구는 새로운 사용자를 위한 다양한 컴퓨터 상호작용을 가능하게 하는, 착용/탈착이 용이한 손목 기반 신경운동 인터페이스를 소개합니다. 확장 가능한 데이터 수집 프레임워크를 개발하고 다양한 참가자로부터 대규모 훈련 코퍼스를 수집했습니다 (Figure 1 참조). 지도 딥러닝을 사용하여 BCI 및 sEMG 시스템의 오랜 일반화 문제를 극복하는 범용 sEMG 모델을 생성했습니다 (Figure 2 참조).
그 결과, sEMG 디코더는 세션 또는 참가자별 데이터나 보정 없이도 폐쇄 루프 평가에서 연속 제어, 이산 입력, 텍스트 입력을 가능하게 했습니다 (Figure 3 참조). 이산 제스처 신경망 디코더의 중간 표현 분석은 밴드 배치 및 행동 스타일과 관련된 불필요한 매개변수를 분리하는 능력을 보여주었습니다 (Figure 4 참조). 마지막으로, 추가적인 개인화 데이터를 통해 필기 디코딩 성능이 향상됨을 입증했습니다 (Figure 5 참조). 이 연구는 비침습성 생체 신호를 사용하여 범용 상호작용 모델을 구축하기 위한 프레임워크를 정의합니다.
이미지 Reference 자료
- Figure 1: "확장 가능한 sEMG 기록 플랫폼" 섹션에서 하드웨어 개요, 데이터 수집 방식, sEMG 신호 패턴과 함께 소개됩니다.
- Figure 2: "단일 참가자 모델 일반화"에서 일반화의 어려움을, "범용 모델의 오프라인 평가"에서 대규모 데이터 기반 성능 향상 및 스케일링 법칙과 함께 소개됩니다.
- Figure 3: "범용 모델의 온라인 평가"에서 세 가지 주요 작업의 폐쇄 루프 성능을 시연하는 부분에서 소개됩니다.
- Figure 4: "이산 제스처 모델 학습 표현 분석"에서 모델의 내부 작동 방식, 특히 컨볼루션 필터와 LSTM 표현의 생리학적 기반 및 불필요 변수 불변성 학습과 함께 소개됩니다.
- Figure 5: "필기 모델 개인화"에서 개인화의 효과, 수확 체감, 그리고 범용 코퍼스 확장과의 관계를 설명하는 부분에서 소개됩니다.
HCI 베이스라인과의 비교에서, 본 sEMG 디코더는 기존의 입력 방식(MacBook 트랙패드, 모션 캡처, Joy-Con 컨트롤러, 펜 없는 필기)에 비해 절대적인 성능은 낮았습니다. 그러나 이러한 베이스라인 인터페이스는 항상 사용 가능한 sEMG 손목 밴드와 같은 역할을 할 수 없으며, 번거로운 장비나 물리적 표면을 필요로 합니다. 따라서 지속적인 가용성이 중요한 온-더-고(on-the-go) 시나리오에서는 현재 디코더 성능의 감소가 수용 가능할 수 있습니다. 향후 사용자 숙련도 증가, 모델 개선(개인화 포함), 후처리, 우수한 센싱을 위한 하드웨어 혁신을 통해 sEMG 디코딩의 추가 개선이 기대됩니다.
결론 (Conclusion)
본 논문은 근육으로부터 직접 의도된 운동 신호를 감지하는 sEMG 디코더를 개발하여 새롭고 접근성 높은 컴퓨터 상호작용의 가능성을 열었습니다.
핵심 기여점은 다음과 같습니다:
-
범용 비침습성 인터페이스: 착용이 용이한 sEMG 손목 밴드와 수천 명의 참가자로부터 훈련 데이터를 수집하는 확장 가능한 인프라를 개발했습니다 (Figure 1). 이를 통해 개인 간 일반화되는 범용 sEMG 디코딩 모델을 구축하여 고대역폭 신경운동 인터페이스의 새로운 기준을 제시했습니다.
-
고성능 상호작용: 테스트 사용자들은 폐쇄 루프 환경에서 연속 탐색 작업에서 초당 0.66 타겟 획득, 이산 제스처 작업에서 초당 0.88 제스처 감지, 필기에서 분당 20.9 단어의 뛰어난 성능을 시연했습니다 (Figure 3). 이는 신경운동 인터페이스가 달성한 가장 높은 수준의 참가자 간 성능으로 알려져 있습니다.
-
모델 일반화 및 표현 학습: 단일 참가자 모델이 세션 간 및 사용자 간에 잘 일반화되지 않는 문제를 확인하고, 대규모 데이터셋을 활용한 범용 모델이 이러한 일반화 문제를 해결함을 보여주었습니다 (Figure 2). 또한, 이산 제스처 디코더의 중간 표현 분석을 통해 모델이 밴드 배치 및 행동 스타일과 같은 방해 요인에 불변하도록 sEMG 표현을 점진적으로 형성함을 밝혔습니다 (Figure 4).
-
개인화의 효과: 범용 sEMG 디코딩 모델의 개인화가 필기 모델의 디코딩 성능을 16%까지 추가로 향상시킬 수 있음을 입증했습니다 (Figure 5). 이는 개인화가 이미 고성능인 범용 모델에 대해서도 점진적 이득을 제공하며, 특히 범용 모델로 성능이 좋지 않은 사용자들에게 상당한 상대적 성능 개선을 제공하여 '롱테일' 문제를 효과적으로 해결할 수 있음을 시사합니다.
향후 방향:
본 sEMG 디코더는 의도된 제스처의 힘과 같이 기존 카메라나 조이스틱으로는 관찰하기 어려운 신호를 직접 감지함으로써 새로운 상호작용 방식을 가능하게 합니다. 1자유도 연속 제어를 시연했지만, 여러 자유도의 동시 제어도 추가적인 생체모방적 매핑(예: 손목의 척골/요골 편위 추가)을 통해 달성 가능할 것으로 예상됩니다. 또한, MUAP와 같은 미세한 신호를 감지하는 sEMG의 민감성은 최소한의 노력으로 제어할 수 있는 기능을 제공하여 다양한 운동 능력이나 인체공학적 요구 사항을 가진 사람들에게 잠재적으로 큰 영향을 미칠 수 있습니다. '제스처 공간'이 아닌 '신경운동 신호 공간'에서의 상호작용 탐색은 새로운 형태의 제어를 가능하게 할 수 있습니다.
연구 플랫폼으로서 sEMG-RD와 관련 소프트웨어 도구는 신경 피드백이 운동 단위 활동에 미치는 영향, 새로운 운동 기술 학습, 운동 단위 제어의 한계 및 메커니즘을 연구하는 데 활용될 수 있습니다. 임상 환경에서는 특정 움직임 수행이 아닌 최소한의 근육 활동만 요구하는 상호작용 설계가 이동성 감소, 근육 약화 또는 신체 부위가 없는 사람들을 위한 실행 가능한 상호작용 방안을 제공하고 효과적인 폐쇄 루프 신경 재활 패러다임 개발을 가능하게 할 수 있습니다. 비록 건장한 참가자들을 대상으로 훈련된 범용 모델이 임상 집단에 일반화될 수 있을지는 불분명하지만, 초기 연구는 유망한 결과를 보여줍니다.
개인화는 범용 모델이 해부학적, 생리학적, 행동적 차이로 인해 충분히 잘 작동하지 않는 사용자들에게 선택적으로 적용될 수 있습니다. 이러한 모든 새로운 애플리케이션은 미래 sEMG 장치의 감지 성능 지속 개선, 운동 장애가 있는 인구 집단을 포괄하는 더욱 다양한 데이터셋, 그리고 IMU 또는 생체 신호와 같은 다른 손목 기록 신호와의 잠재적 결합을 통해 촉진될 것입니다.
읽어주셔서 감사합니다 :)
