[Compression] Learned Image Compression with Dictionary-based Entropy Model (CVPR 2025) 리뷰
Image Compression
논문 제목
Learned Image Compression with Dictionary-based Entropy Model (CVPR 2025)
URL: https://arxiv.org/abs/2504.00496
Github : https://github.com/LabShuHangGU/DCAE
인용수 : 1회 (25.6.4 기준)
오랜만에 학습 기반 이미지 압축 논문 리뷰입니다.
프로젝트 마무리하면서 논문쓰고 현생에 치이다보니 논문 읽기를 소홀히한 것 같습니다..
다시 열심히 논문 읽어서 트렌드에 뒤쳐지지 않기 위해 노력 해보려합니다.
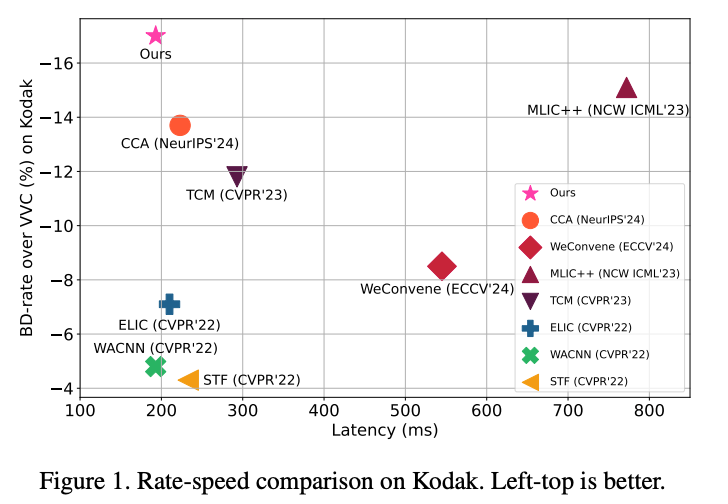
MLIC++ 이후에 많은 이미지 압축 모델이 나왔지만, 2023년 2024년에 나온 모델들은 생각보다 무거운게 문제였습니다.
벤치마킹으로는 향상 효과가 있더라도, 실사용에서의 지연시간이 문제로 작용합니다.
특히나 논문에 적힌 모델 추론 속도는 높은 확률로 A100 GPU로 추론을 해서 정작 제가 사용하는 하위 등급의 GPU에서는 더 오래걸린다는 것이 문제였습니다.
이 논문은 2022년도의 SOTA였던 ELIC, WACNN 같은 모델의 인코딩 디코딩 속도로 MLIC++를 뛰어넘는 성능을 보였습니다.
실제로 소스 코드를 돌려보았을 때도 MLIC++의 디코딩 속도 = DCAE 인코딩 + 디코딩 속도 일 정도로 빨랐습니다...!
Abstract
- 엔트로피 모델은 LIC에서 잠재표현의 확률 분포를 추정하여 이후의 엔트로피 부호화에 사용됨.
- 대부분의 기존 방법들은 Hyperprior와 Autoregressive 구조를 엔트로피 모델로 사용했음
- 하지만 이 방법은 잠재 표현의 내부 종속성만을 탐색하는 데 집중했으며, 학습 데이터로부터 prior를 추출하는 것의 중요성은 간과함.
- 본 논문에서는 Dictionary-based Cross Attention Entropy (DCAE) 모델이라는 새로운 엔트로피 모델을 제안.
- 이 모델은 학습 가능한 딕셔너리를 도입하여, 학습 데이터셋에서 자주 등장하는 전형적인 구조를 요약하고 이를 활용하여 엔트로피 모델을 강화한다고함.
Related Work
Dictionary Learning
Dictionary learning은 훈련 데이터셋으로부터의 prior 정보를 효과적으로 활용할 수 있는 능력 덕분에 image generation 및 image restoration 분야에서 강력한 가능성을 보여왔음.
학습 기반 이미지 압축에서는 K-means++ 알고리즘에서 얻은 non-learnable 딕셔너리를 처음으로 활용하여 엔트로피 모델을 개선한 사례가 있고, 글로벌 내부 종속성을 포착하기 위해
전송이 필요한 8개의 learnable tokens을 활용한 케이스가 있었음.
하지만 이 토큰들은 이미지 자체에서 파생되었고, 토큰 수가 제한적이고 부호화 및 복호화 시 전송이 필요하다는 점 때문에 엔트로피 모델을 개선하는 능력에 한계가 있었음.
본 논문에서는 Dictionary-based Cross Attention Entropy 모델을 제안하였으며 공유 가능한 학습형 네트워크 파라미터들을 딕셔너리로 활용하여 인코딩 및 디코딩 과정에서 외부 종속성을 포착함.
이를 통해 보다 정확한 분포 추정을 수행할 수 있다고 함.
Method
Formulation
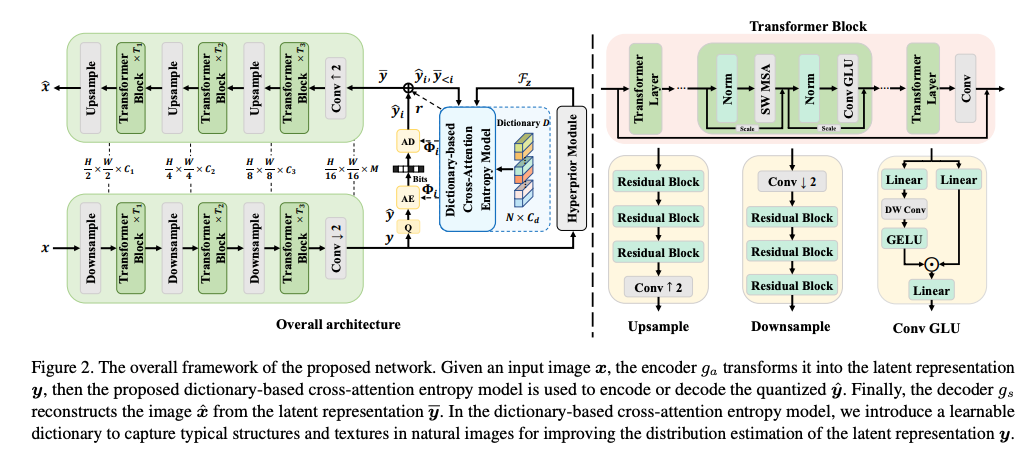
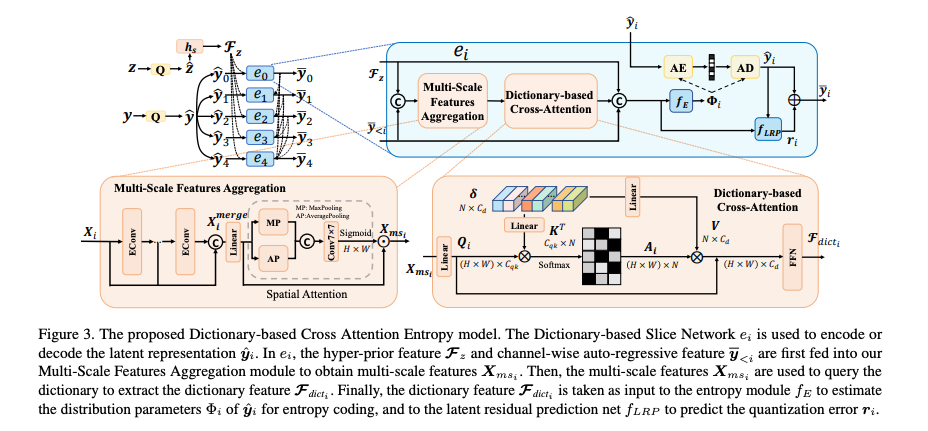
위 이미지는 DCAE 프레임워크의 전반적인 구조이다.
LIC는 인코딩 단계에서 입력 이미지 가 주어지면 인코더는 이를 잠재표현 로 변환한다.
변환 후 엔트로피 모델은 잠재표현 에 대한 분포 파라미터 를 추정하여 엔트로피 부호화에 사용된다. 보통 는 아래와 같이 양자화 됨.
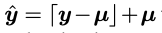
⌈𝑦−𝜇⌉는 추정된 분포 파라미터 Φ에 기반하여 무손실로 비트스트림에 부호화된다.
디코딩 단계에서는 비트스트림으로 부터 를 복원한 뒤 디코더는 양자화된 잠재표현으로부터 이미지를 복원함.
이 과정에서 엔트로피 모델은 부호화 길이를 결정하기 때문에 가장 중요한 역할 중 하나를 수행함. 대부분의 기존 엔트로피 모델은 Hyperprior 구조와 Channel-wise Autoregressive 구조를 따른다.
하이퍼프라이어 구조에서는, 잠재 표현 𝑦 내의 내부 공간 종속성을 포착하기 위해 부가 정보
가 먼저 도입된다. 이후에 하이퍼프라이어 디코더는 를 잠재 피쳐 로 매핑하고, 이는 잠재표현 의 분포 를 추정하는데 사용된다.
에 조건화 된 상태에서 잠재표현 y는 아래 수식으로 joint-gaussian distribution으로 모델링됨.
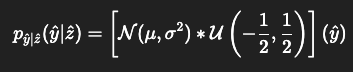
Channel-wise Autoregressive에서는 y를 채널 차원 방향으로 여러 개의 균등한 슬라이스로 나뉜다. 이 슬라이스들은 순차적으로 부호화 및 복호화되면서 이미 복호화된 이전 슬라이스들은 다음 슬라이스의 부호화 또는 복호화를 보조하는 데 사용함. 이는 슬라이스들 간의 유사성 때문에 이렇게 사용한다고함.
하이퍼프라이어 피쳐 와 디코딩 된 슬라이스 는 엔트로피 모듈 에 입력되어 의 분포 파라미터 (평균, 스케일)를 추정함.
그리고 양자화에 의해 발생하는 정보 손실을 보완하기 위해 ,,는 에 입력값으로 사용되어서 잔차 를 예측함.

학습 기반 이미지 압축 모델을 학습할 땐 라그랑지 승수 기반의 rate-distortion 최적화가 손실 함수로 사용됨.
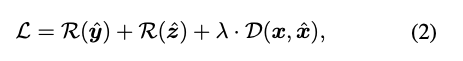
Dictionary-based Cross Attention Entropy Model
기존 방법들은 잠재 표현 𝑦의 확률 분포를 추정하기위해 하이퍼프라이어와 오토리그레션(AR) 프레임워크를 사용함.
이 두 가지 방식은 본질적으로 잠재 표현 internal dependencies을 이용하여 확률 분포를 모델링함.
그러나 두 방식 모두 natural images에서 흔히 나타나는 패턴과 텍스처를 엔트로피 추정을 위한 prior information으로 명시적으로 활용하진 않음.
본 논문의 목표는 인코더와 디코더 간에 공유되는 딕셔너리를 통해 전형적인 텍스처를 보존하는 것이라고 함. 잠재 표현의 분포를 추정할 때 부분적인 정보를 기반으로 딕셔너리에 저장된 완전한 정보를 querying 함으로써 더 정확하게 잠재 표현을 모델링할 수 있다함.
이를 달성하기 위해 Dictionary-based Cross Attention Entropy Model (DCAE)을 제안했음.
DCAE에서 제안하는 두 모듈은 아래와 같다.
1. Multi-Scale Features Aggregation (MSFA)
2. Dictionary-based Cross Attention (DCA)
먼저 MSFA는 다중 수용영역의 피처들을 활용하여 다양한 스케일에서 텍스처를 포착함.
이 추출한 피쳐를 DCA모듈의 입력값으로 사용하고, DCA는 학습 가능한 네트워크 파라미터로 구성된 딕셔너리 𝐷를 사용하고,제공된 부분 텍스처 정보를 사용하여 딕셔너리 내의 완전한 정보를 크로스 어텐션 방식으로 동적으로 조회함.
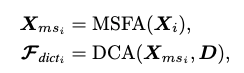
기존 이미지 압축 방식은 Dictionary 정보를 명시적으로 사용하지 않았으나, 제안 방법에서는 를 엔트로피 모듈에 입력하여 가우시안 분포 파라미터(평균, 스케일)를 추정함.
또한 위 세 변수는 LRP에 입력되어 양자화 오차 를 예측함.
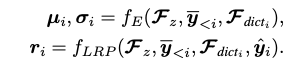
Multi-Scale Features Aggregation Module
MFSA는 feature map으로부터 다중 스케일의 텍스처들을 포착하는 데 사용된다. 이는 딕셔너리에 저장된 prior information를 보다 정확히 querying 할 수 있게 한다.
구조는 다양한 컨볼루션 층에서 추출한 피처맵을 활용하여 다중 스케일 텍스처 추출을 진행함.
shallow 층에서 추출한 피처맵은 수용영역이 작기 때문에 fine texture를 포착할 수 있고, deep한 층은 더 넓은 스케일의 텍스처를 포착할 수 있음.
그리고 효율적인 연산을 위해 DWConv과 Linear층으로 구성했다고함.
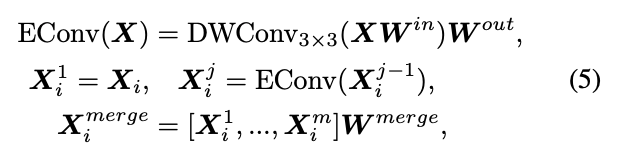
보다 정밀한 querying을 위해 spatial attention을 사용하여 공간 위치에 대해 동적으로 가중치를 부여했다고함.
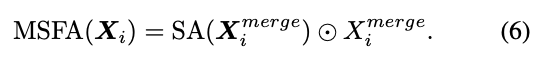
Dictionary-based Cross Attention Module
학습 가능한 네트워크 파라미터를 사용하여 자연 이미지에서 발견되는 공통적인 텍스처를 보존하는 공유 딕셔너리 𝐷를 구성함. 이 딕셔너리는 초기에 [N, C_d ]크기 텐서로 초기화되고, 여기서 N는 딕셔너리 항목 수이고 는 피처 차원 수임.
학습 과정 중에, 이 딕셔너리는 점차 전형적인 구조들을 잘 표현하도록 학습되며 이는 전통적인 딕셔너리 학습 기법에서 이미지 패치 딕셔너리를 학습하는 것과 유사하다고함.
또한, 해당 딕셔너리는 인코더와 디코더가 동시에 공유하기 때문에 전송을 위한 추가적인 비트레이트는 필요하지 않는 것이 장점이라고 한다.
이 다음에는 자연 이미지에 존재하는 사전 정보를 포착하기 위해 부분적인 텍스처 정보를 포함한 피처들을 사용하여 학습 가능한 딕셔너리를 크로스 어텐션 방식으로 조회함.
다중 스케일 피처 를 사용하여 쿼리 토큰을 생성하고 딕셔너리 D를 사용하여 K,V를 생성함.
여기서 K는 쿼리와의 유사도 계산하는데 사용하고, V는 딕셔너리에 저장된 텍스처 정보를 의미함. 수식으로 표기하면 아래와 같음
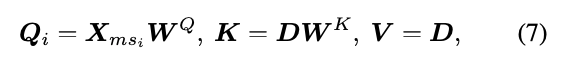
그 다음에 cross-attention해서 딕셔너리 피쳐를 계산함.
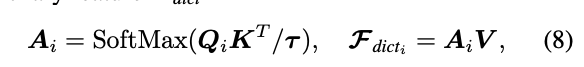
여기서 는 쿼리와 키의 내적 범위를 조정하는 학습 가능한 스케일링 파라미터임.
Network Architecture
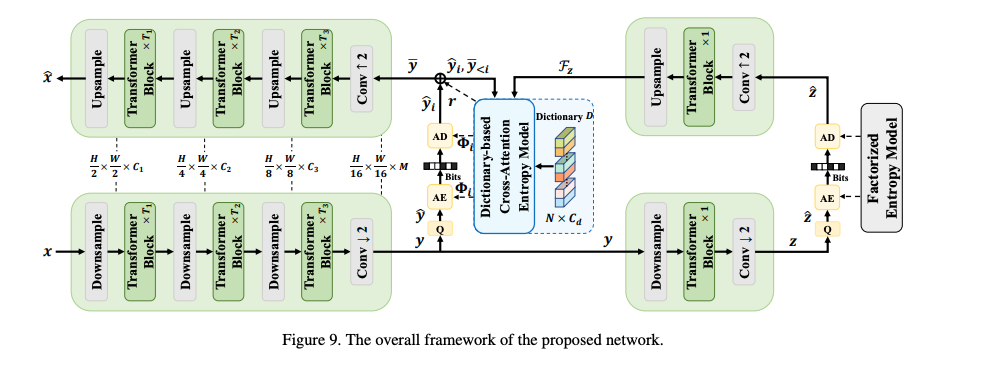
DCAE 모델의 구조는 Formulation 섹션에 첨부되어있습니다.
기본적인 다운샘플링/업샘플링 모듈 다음에 Swin Transformer 블록을 적용하여 비선형 변환을 수행하고 압축된 잠재 표현을 추출함.
각 기본 다운샘플링/업샘플링 모듈은 스트라이드 합성곱 또는 전치 합성곱(TConv)과 여러 개의 연속된 잔차 블록으로 구성되며 local context 정보를 추출한다.
Swin Transformer 블록은 long-range dependency을 포착하여 non-local 정보를 공급함.
또한 Transformer의 비선형 변환 능력을 더욱 강화하기 위해 Transformer 모델의 깊이를 확장하는 ResScale을 사용하고, Convolutional Relative Position Encoding을 채택했음.
이전 방법들은 인코더-디코더의 서로 다른 단계에서 동일한 수의 채널과 모듈을 사용한다.
그러나 고해상도 피처를 연산하는 것은 전체 모델 속도를 저하시킴.
보다 효율적인 구조 설계를 달성하기 위해 서로 다른 단계에서 채널 수와 모듈 수를 다르게 설정하고, 연산을 해상도가 더 낮은 단계로 이동시켜 인코딩과 디코딩 속도를 향상시켰다고함.
Experiments
Experimental Settings
Training Details
전반적인 실험 설정은 WACNN을 기반으로 설정했다고하며 데이터셋은 Open-Image 데이터셋 30만장을 256x256으로 랜덤 크롭해서 학습했다고함.
배치 사이즈는 16, 옵티마이저는 Adam, 손실함수는 MSE 사용했다고함.
다양한 압축률 실험을 위해 Kodak 벤치마킹에 주로사용하는 여섯개의 람다 값을 동일하게 사용했음.
Implementation Details
제안 모델에서는 128개의 딕셔너리 항목과 640 채널을 갖는 학습 가능한 딕셔너리(learnable dictionary)를 사용함. 그리고 우리는 Transformer Block 내에서의 Transformer 계층 수를 다음과 같이 스케일별로 설정 .
하이퍼프라이어 모듈에서는 Transformer 계층 수를 1개로 설정.
피처 차원(채널 수)은 스케일에 따라 다음과 같이 설정함 .
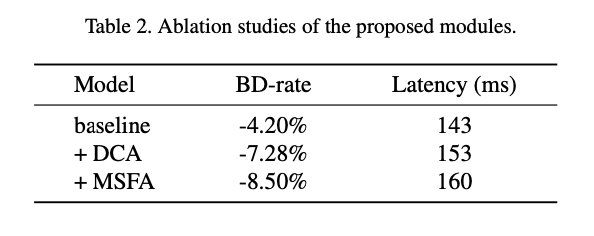
Ablation Studies
제안한 Dictionary-based Cross-Attention Entropy (DCAE) 모델의 유효성을 검증하기 위한 Ablation 실험에서는 더 작은 모델을 사용하며 Transformer 계층 수를 다음과 같이 설정함 (.
제안한 방법들의 유효성을 보여주기 위해 모든 모듈을 제거한 상태에서 baseline을 구성하고 이후 모듈을 하나씩 추가하며 성능 향상을 확인했다고함.
또한 딕셔너리 크기에 따른 영향을 분석한 결과는 아래와 같다.
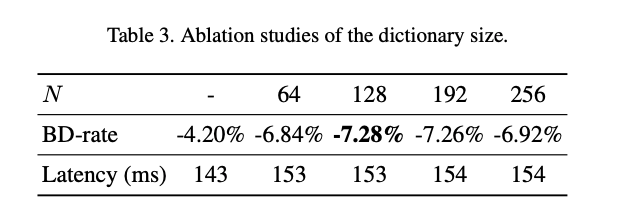
딕셔너리 크기가 128까지 키웠을 경우 성능이 개선되었으나 이 이상부터는 정체되어서 성능향상이 없다고함.
MSFA 모듈 내의 합성곱 층 수를 m=0∼4로 바꾸며 성능 영향을 실험한 결과는 아래와 같다.
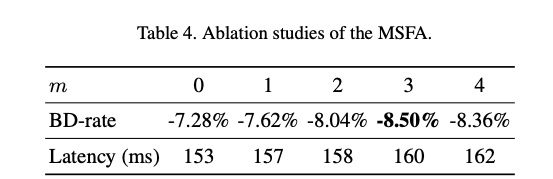
m= 3일 때 가장 좋은 성능을 보이며 그 이상 증가시켜도 추가적인 향상은 없음.
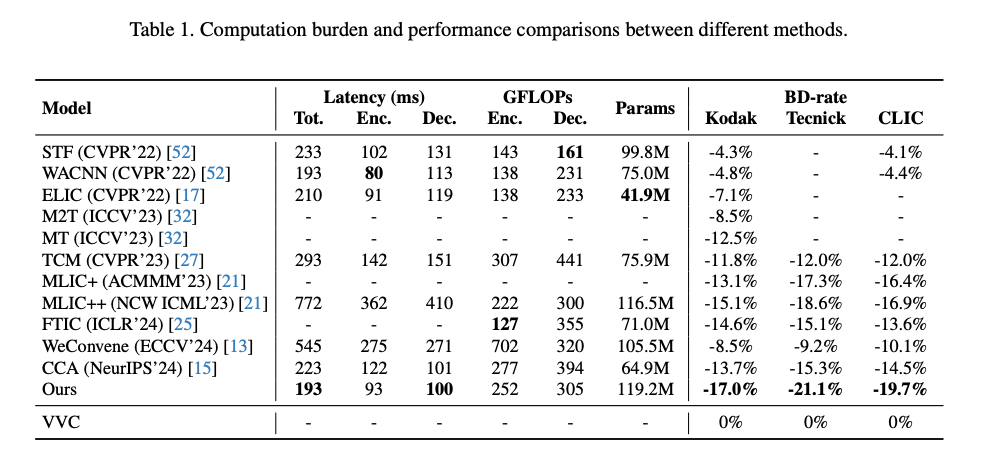
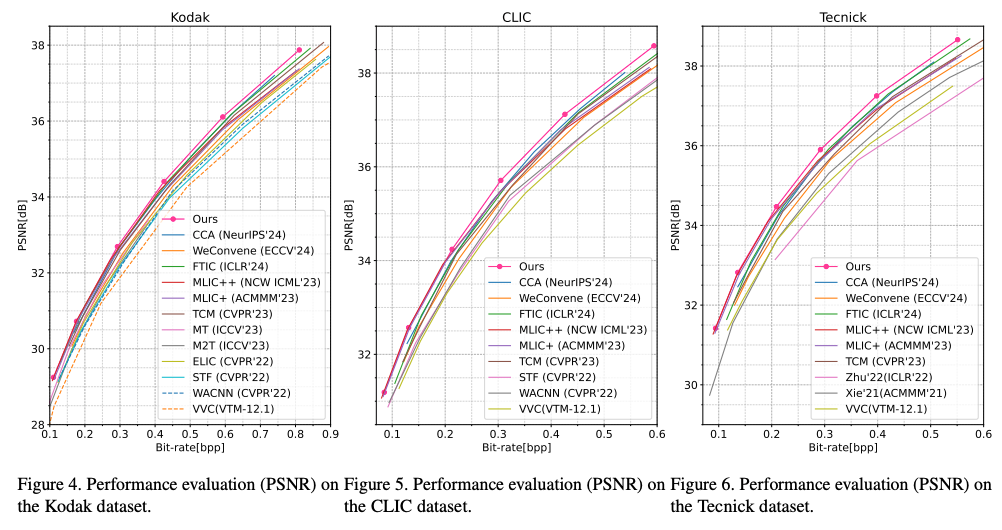
Comparisons with State-of-the-Art Methods
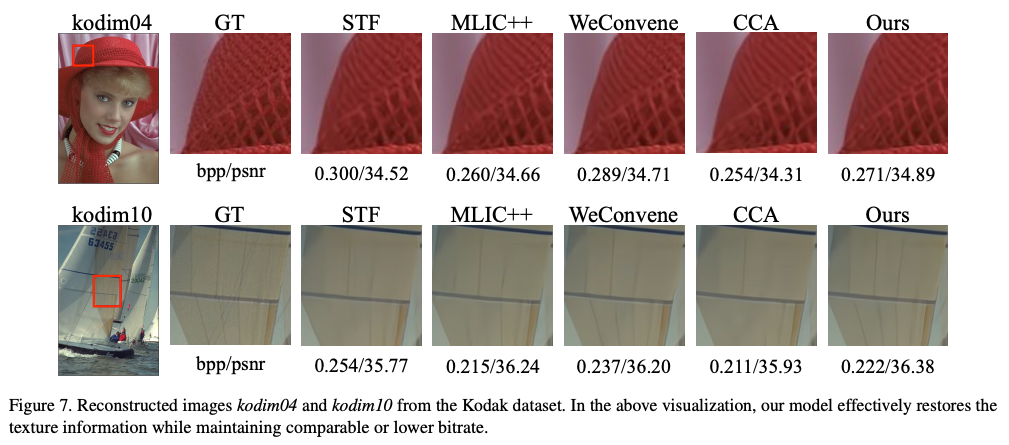
BD-Rate는 VVC (VTM-12.1)을 기준으로 계산되었다고함.
현재 최고 BD-rate 성능을 기록하고 있는 MLIC++와 비교해도 DCAE는 세 가지 데이터셋 전체에서 더 우수한 성능을 보임.
특히, Kodak 데이터셋 기준으로 MLIC++의 추론 시간은 DCAE의 거의 네 배에 달한다고함.
시각적인 결과로 보아도 이미지 세부 정보를 유지하는 데 있어 우수함을 입증함.
Conclusion
- 본 논문에서는 학습 데이터로부터의 사전 정보를 명시적으로 포착하기 위해 새로운 딕셔너리 기반 크로스 어텐션 엔트로피(DCAE) 모델을 제안함.
- 제안된 엔트로피 모델은 자연 이미지에서의 전형적인 구조 및 텍스처를 요약하기 위해
학습 가능한 네트워크 파라미터를 사용하며 이를 통해 엔트로피 모델을 개선함.
