
지난번 1편에 이어서 Section 4의 Experiment 부터 Appendix까지도 살펴보도록 한다.
4. Experiment
본 논문에서는 DETR이 COCO 정량적 평가에서 Faster R-CNN과 견줄 만한 성능을 보인다는 것을 확인했다. 또한 아키텍처와 손실 함수에 대한 세밀한 ablation study를 수행하여 통찰력 있는 분석과 정성적 결과를 함께 제시한다. 마지막으로 DETR의 범용성과 확장 가능성을 입증하기 위해, 기본 DETR 모델에 최소한의 확장만을 추가로 학습시켜 panoptic segmentation 과제에서의 성과를 보여준다. 실험 재현을 위한 코드와 사전 학습된 모델은 GitHub에서 제공된다.
데이터셋 (Dataset)
본 논문에서는 COCO 2017 detection 및 panoptic segmentation 데이터셋 [24, 18]을 사용하여 실험을 진행하였으며, 이 데이터셋은 118k장의 학습 이미지와 5k장의 검증 이미지로 구성되어 있다. 각 이미지는 bounding box와 panoptic segmentation으로 라벨링되어 있다. 학습 세트에서는 이미지 당 평균 7개의 객체 인스턴스가 있으며, 동일 이미지 내에서 작은 것부터 큰 것까지 다양한 크기를 가지고 있고, 한 이미지에서 최대 63개의 인스턴스가 나타날 수 있다. (본 논문의 AP 평가지표는 bbox AP, 즉 여러 임계값에 대한 적분 메트릭(integral metric)을 나타냄)
Faster R-CNN과의 비교를 위해서는 마지막 학습 epoch에서의 검증 AP를 보고하며, ablation study를 위해서는 마지막 10개 epoch의 검증 결과에 대한 중앙값을 보고한다.
기술적 세부사항 (Technical details)
DETR 학습에는 AdamW [26]를 사용하며, transformer의 초기 학습률은 , 백본의 학습률은 , 가중치 감쇠(weight decay)는 로 설정하였다. 모든 transformer 가중치는 Xavier initialization [11]으로 초기화하고, 백본은 torchvision의 ImageNet 사전 학습된 ResNet 모델 [15]을 사용하며 BatchNorm 계층은 동결시켰다. 본 연구에서는 두 가지 백본인 ResNet-50과 ResNet-101에 대한 결과를 보고하며, 해당 모델들을 각각 DETR과 DETR-R101로 명명한다. [21]에 따라 백본의 마지막 단계에 dilation을 추가하고 이 단계의 첫 번째 컨볼루션에서 stride를 제거하여 특징 해상도를 높였다. 이러한 모델들은 각각 DETR-DC5와 DETR-DC5-R101 (dilated C5 stage)로 명명한다. 이 수정은 해상도를 2배 증가시켜 작은 객체에 대한 성능을 향상시키지만, 인코더의 self-attention에서 16배 더 높은 연산 비용을 발생시켜 전반적인 계산 비용을 2배 증가시킨다. 이 모델들과 Faster R-CNN의 전체 FLOPs 비교는 Table 1에 제시되어 있다.
Xavier initialization [11]
: 2010년 Xavier Glorot의 논문에서 제시된 신경망의 가중치를 초기화하는 기법으로, 순전파와 역전파 모두에서 활성화 함수와 그래디언트가 효과적으로 흐를 수 있도록 네트워크의 초기 가중치를 설정하는 것. 모든 층에서 활성화 함수의 분산이 동일하게 유지되도록 가중치를 초기화하여 그래디언트가 폭발하거나 소실되는 것을 방지
- Dilated convolution (팽창 컨볼루션)
: 커널의 연속적인 요소들 사이에 구멍(holes)을 삽입하여 커널을 확장하는 기법. 네트워크의 수용 영역(receptive field)을 지수적으로 증가시키면서 파라미터는 선형적으로 증가시켜, 파라미터 수를 늘리지 않고도 필터의 수용 영역을 확대하고 네트워크 계산 비용의 큰 증가 없이 더 넓은 맥락을 캡처할 수 있게 함
스케일 증강(scale augmentation)을 사용하여 입력 이미지의 가장 짧은 변이 최소 480, 최대 800 픽셀이면서 가장 긴 변은 최대 1333 픽셀이 되도록 크기를 조정한다 [50]. 인코더의 self-attention을 통한 전역적 관계 학습을 돕기 위해 학습 중에 무작위 크롭 증강(random crop augmentations)을 적용하여 성능을 약 1 AP 향상시켰다. 구체적으로, 학습 이미지는 0.5의 확률로 무작위 직사각형 패치로 잘린 후 다시 800-1333으로 크기가 조정된다. Transformer는 0.1의 기본 dropout으로 학습된다.
추론 시 일부 슬롯은 빈 클래스를 예측한다. AP 최적화를 위해 이러한 슬롯의 예측을 해당 신뢰도를 사용하여 두 번째로 높은 점수를 받은 클래스로 덮어쓴다. 이는 빈 슬롯을 걸러내는 것에 비해 AP를 2포인트 향상시킨다. 다른 학습 하이퍼파라미터는 A.4절에서 확인할 수 있다. Ablation 실험을 위해서는 300 epoch 학습 일정을 사용하며 200 epoch 후에 학습률을 10배 감소시킨다. 여기서 단일 epoch는 모든 학습 이미지를 한 번 순회하는 것을 의미한다. 기준 모델을 16개의 V100 GPU에서 300 epoch 동안 학습시키는 데는 3일이 소요되며, GPU 당 4개의 이미지를 사용한다 (따라서 총 배치 크기는 64이다). Faster R-CNN과의 비교를 위해 사용되는 더 긴 일정의 경우, 400 epoch 후에 학습률을 감소시키며 500 epoch 동안 학습시킨다. 이 일정은 더 짧은 일정에 비해 1.5 AP를 추가로 향상시킨다.
- Table 1. COCO 검증 세트에서 ResNet-50 및 ResNet-101 백본을 사용한 Faster R-CNN과의 성능 비교. 상단 섹션은 Detectron2 [50]에서 제공하는 Faster R-CNN 모델의 결과이고, 중간 섹션은 GIOU [38], 학습 시 무작위 크롭 증강, 그리고 긴 9x 학습 스케줄을 적용한 Faster R-CNN 모델의 결과이다. DETR 모델들은 매우 정교하게 튜닝된 Faster R-CNN 베이스라인과 견줄 만한 성과를 달성했으며, 작은 객체에 대한 성능(APS)은 다소 낮지만 큰 객체에 대한 성능(APL)은 크게 향상되었다. FLOPS와 FPS 측정에는 torchscript 버전의 Faster R-CNN과 DETR 모델을 사용하였다. 이름에 R101이 포함되지 않은 결과는 ResNet-50에 해당한다.
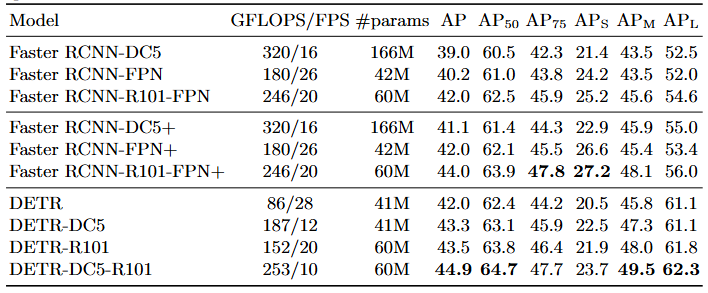
4.1. Comparison with Faster R-CNN
Transformer는 일반적으로 매우 긴 학습 스케줄과 dropout을 사용하여 Adam 또는 Adagrad 옵티마이저로 학습되며, DETR 역시 마찬가지이다. 반면 Faster R-CNN은 최소한의 데이터 증강과 함께 SGD로 학습되고, Adam이나 dropout을 성공적으로 적용한 사례는 알려져 있지 않다. 이러한 차이점에도 불구하고 Faster R-CNN 기준 모델을 더 강력하게 만들고자 하였다. DETR과 공정한 비교를 위해 상자 손실(box loss)에 generalized IoU [38]를 추가하고, 성능 향상에 효과적인 것으로 알려진 동일한 무작위 크롭 증강과 긴 학습 스케줄을 적용하였다 [13].
결과는 Table 1에 나타나 있다. Table 1의 상단 섹션은 3x 스케줄로 학습된 모델에 대한 Detectron2 Model Zoo [50]의 Faster R-CNN 결과를 보여준다.
Generalized IoU (GIoU) [38]
: IoU (Intersection over Union)는 예측된 바운딩 박스와 실제 정답 박스가 얼마나 잘 정렬되는지를 측정하는 지표로, 객체 탐지 알고리즘의 정확도를 평가하는 주요 메트릭. IoU 손실 함수의 문제점은 실제 정답과 예측 간에 겹치는 부분이 없을 때 IoU가 0이 되고, 그래디언트도 0이 된다는 것이다. IoU가 0일 때 손실은 1(1에서 0을 뺀 값)이 되어 상수가 되므로, 손실의 변화가 없어 그래디언트가 0이 되는데, 이는 학습 초기에 예측이 부정확할 때 자주 발생하는 상황이다. 이러한 문제점 해결을 위해, GIoU는 예측된 박스와 실제 정답 박스 사이의 교집합뿐만 아니라 두 박스를 모두 포함하는 둘러싸는 영역(enclosing area)도 고려한다. 교집합이 없는 경우에도 예측의 실제 정답에 대한 근접성을 더 유익하게 평가할 수 있으며, 실제로 YOLOv3, Faster R-CNN, Mask R-CNN 등에서 GIoU를 사용했을 때 더 나은 성능을 보였다.
Table 1의 중간 섹션은 동일한 모델이지만 9x 스케줄(109 epoch)과 앞서 설명한 개선 사항을 적용하여 학습한 결과로, 총 1-2 AP의 성능 향상을 보여준다.
Table 1의 마지막 섹션에서는 여러 DETR 모델의 결과를 제시한다. 파라미터 수를 비슷하게 맞추기 위해 6개의 인코더와 6개의 디코더 레이어, 너비 256, 8개의 어텐션 헤드를 가진 모델을 선택하였다. FPN을 사용한 Faster R-CNN과 마찬가지로 이 모델은 총 41.3M개의 파라미터를 가지며, 이 중 23.5M개는 ResNet-50에, 17.8M개는 transformer에 해당한다. Faster R-CNN과 DETR 모두 더 긴 학습을 통해 추가적인 성능 향상이 가능하지만, DETR이 동일한 파라미터 수로 Faster R-CNN과 경쟁할 수 있으며 COCO 검증 세트에서 42 AP를 달성할 수 있음을 확인하였다.
DETR이 이러한 성과를 달성하는 방식은 대형 객체에 대한 성능()을 크게 향상시키는 것(+7.8)이지만, 여전히 소형 객체 성능()에서는 상당히 뒤처진다(-5.5)는 점을 주목해야 한다. 동일한 파라미터 수와 유사한 FLOP 수를 가진 DETR-DC5는 더 높은 AP를 보이지만, 역시 AP_S에서는 크게 뒤처진다. ResNet-101 백본을 사용한 Faster R-CNN과 DETR도 비슷한 패턴을 보여준다.
4.2. Ablations
Transformer 디코더의 어텐션(attention) 메커니즘은 서로 다른 탐지 결과의 특징 표현 간 관계를 모델링하는 핵심 구성 요소이다. Ablation 분석에서는 아키텍처와 손실 함수의 각 구성 요소가 최종 성능에 미치는 영향을 탐구한다. 이 연구를 위해 6개의 인코더, 6개의 디코더 레이어 및 너비 256을 갖춘 ResNet-50 기반 DETR 모델을 선택하였다. 이 모델은 41.3M개의 파라미터를 가지며, 짧은 스케줄과 긴 스케줄에서 각각 40.6 AP와 42.0 AP를 달성하고, 동일한 백본을 가진 Faster R-CNN-FPN과 유사하게 28 FPS로 실행된다.
인코더 레이어 수 (Number of encoder layers)
인코더 레이어 수를 변경하여 전역적 이미지 수준 self-attention의 중요성을 평가하였다(Table 2).
- Table 2. 인코더 크기의 영향(Effect of encoder size). 각 행은 다양한 수의 인코더 레이어와 고정된 수의 디코더 레이어를 가진 모델에 해당한다. 성능은 인코더 레이어가 많아질수록 점진적으로 향상된다.
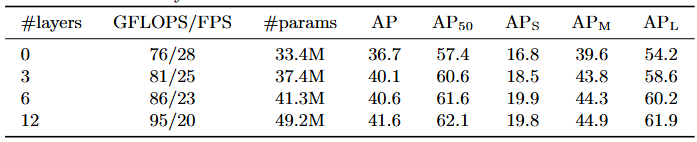
인코더 레이어가 없으면 전체 AP가 3.9포인트 하락하며, 대형 객체에서는 6.0 AP라는 더 큰 하락폭을 보인다. 인코더가 전역적 장면 추론(global scene reasoning)을 통해 객체를 분리하는 데 중요한 역할을 한다고 판단된다. Figure 3에서는 학습된 모델의 마지막 인코더 레이어의 어텐션 맵을 이미지의 몇몇 지점을 중심으로 시각화하였다. 인코더는 이미 인스턴스를 분리하는 것으로 보이며, 이는 디코더의 객체 추출 및 지역화를 단순화할 가능성이 높다.
- Figure 3. 특정 참조점(reference points)에 대한 Encoder self-attention. 인코더는 개별 인스턴스를 분리할 수 있다. 예측은 검증 세트 이미지에 대해 베이스라인 DETR 모델로 수행되었다.

디코더 레이어 수 (Number of decoder layers)
각 디코딩 레이어 이후에 보조 손실(auxiliary losses)을 적용하므로(섹션 3.2 참조), 예측 FFN은 설계상 모든 디코더 레이어의 출력에서 객체를 예측하도록 학습된다. 디코딩의 각 단계에서 예측되는 객체들을 평가하여 각 디코더 레이어의 중요성을 분석하였다(Figure 4). AP와 AP50 모두 모든 레이어를 거치면서 향상되어, 첫 번째 레이어와 마지막 레이어 사이에서 총 +8.2/9.5 AP라는 매우 상당한 개선을 보였다.
- Figure 4. 각 디코더 레이어 이후의 AP 및 AP50 성능. 단일 장기 스케줄 베이스라인 모델이 평가된다. DETR은 설계상 NMS가 필요하지 않으며, 이는 이 그림으로 검증된다. NMS는 최종 레이어에서 참 양성(TP) 예측을 제거하여 AP를 낮추지만, 첫 번째 레이어에서는 통신이 없기 때문에 이중 예측을 제거하여 AP를 향상시키고, AP50를 약간 향상시킨다.
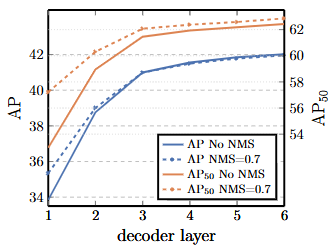
집합 기반 손실(set-based loss) 덕분에 DETR은 설계상 NMS를 필요로 하지 않는다. 이를 검증하기 위해 각 디코더의 출력에 대해 기본 파라미터 [50]를 사용하여 표준 NMS 절차를 실행하였다. NMS는 첫 번째 디코더의 예측에 대한 성능을 향상시킨다. 이는 단일 디코딩 레이어의 transformer는 출력 요소들 간의 교차 상관 관계(cross-correlations)를 계산할 수 없어 동일한 객체에 대해 여러 예측을 하기 쉽다는 사실로 설명할 수 있다. 두 번째 및 후속 레이어에서는 활성화(activations)에 대한 self-attention 메커니즘이 모델로 하여금 중복 예측을 억제하도록 한다. NMS가 가져오는 개선 효과는 깊이가 증가함에 따라 감소하는 것을 관찰할 수 있다. 마지막 레이어들에서는 NMS가 실제 참 양성 예측(true positive predictions)을 잘못 제거하면서 AP에서 약간의 손실이 관찰된다.
인코더 attention을 시각화하는 것과 유사하게, Figure 6에서 디코더 attention을 시각화하고 각 예측된 객체에 대한 attention 맵을 다른 색상으로 표시하였다. 디코더 attention이 상당히 지역적(local)이라는 것을 관찰할 수 있는데, 이는 주로 머리나 다리와 같은 객체의 말단에 주의를 기울인다는 것을 의미한다. 인코더가 전역 attention(global attention)을 통해 인스턴스를 분리한 후에는, 디코더가 클래스와 객체 경계를 추출하기 위해 말단에만 주의를 기울이면 된다고 판단된다.
- Figure 6. 예측된 모든 객체에 대한 디코더 attention 시각화 (이미지는 COCO val set에서 가져옴). 예측은 DETR-DC5 모델로 수행되었다. Attention score는 객체별로 다른 색상으로 표시되어 있다. 디코더는 일반적으로 다리나 머리와 같은 객체의 말단에 attending 한다.

FFN의 중요성 (Importance of FFN)
Transformer 내부의 FFN은 1×1 컨볼루션 레이어로 볼 수 있으며, 이는 인코더를 attention 증강 컨볼루션 네트워크 [3]와 유사하게 만든다. FFN을 완전히 제거하고 transformer 레이어에 attention만 남겨두는 실험을 진행하였다. 네트워크 파라미터 수를 41.3M에서 28.7M으로 줄이고 transformer에 10.8M만 남김으로써 성능이 2.3 AP 하락했으며, 따라서 좋은 결과를 얻기 위해서는 FFN이 중요하다고 결론지었다.
위치 인코딩의 중요성 (Importance of positional encodings)
이 모델에는 공간적 위치 인코딩(spatial positional encodings)과 출력 위치 인코딩(output positional encodings, 즉 object queries)의 두 종류의 위치 인코딩이 있다. 고정된 인코딩과 학습된 인코딩의 다양한 조합으로 실험하였으며, 결과는 Table 3에서 확인할 수 있다. 출력 위치 인코딩은 필수적이며 제거할 수 없으므로, 디코더 입력에서 한 번 전달하거나 모든 디코더 attention 레이어의 쿼리에 추가하는 방식으로 실험하였다.
- Table 3. 다양한 위치 인코딩에 대한 결과를 베이스라인(마지막 행)과 비교. 베이스라인은 인코더와 디코더의 모든 attention 레이어에 고정된 sine 위치 인코딩을 전달한다. 학습된 임베딩은 모든 레이어 간에 공유된다. 공간적 위치 인코딩을 사용하지 않으면 AP가 크게 하락한다. 흥미롭게도 디코더에서만 전달하면 AP가 약간만 하락한다. 이 모든 모델은 학습된 출력 위치 인코딩을 사용한다.
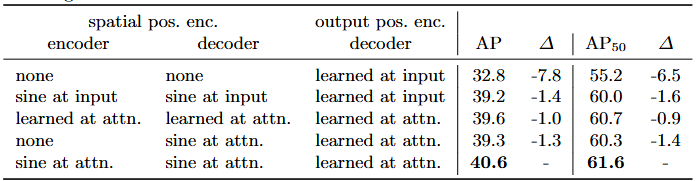
첫 번째 실험에서는 공간적 위치 인코딩을 완전히 제거하고 출력 위치 인코딩을 입력에 전달했는데, 흥미롭게도 모델은 여전히 32 AP 이상을 달성했지만 베이스라인에 비해 7.8 AP를 잃었다. 그 다음, 원래 Transformer [47]에서처럼 고정된 sine 공간적 위치 인코딩과 출력 인코딩을 입력에서 한 번 전달했고, 이것이 위치 인코딩을 attention에 직접 전달하는 것에 비해 1.4 AP 하락으로 이어진다는 것을 발견했다. 학습된 공간적 인코딩을 attention에 전달했을 때 비슷한 결과를 얻었다. 놀랍게도 인코더에서 어떠한 공간적 인코딩도 전달하지 않는 것이 단지 1.3 AP의 미미한 하락으로만 이어진다는 것을 발견했다.
인코딩을 attention에 전달할 때, 이들은 모든 레이어에 걸쳐 공유되며, 출력 인코딩(object queries)은 항상 학습된다. 이러한 ablation 연구를 고려할 때, Transformer의 구성 요소들, 즉 인코더의 전역 self-attention, FFN, 다중 디코더 레이어, 그리고 위치 인코딩이 모두 최종 객체 탐지 성능에 상당히 기여한다고 결론지었다.
손실에 대한 Ablation study (Loss ablations)
매칭 비용과 손실의 각 구성 요소의 중요성을 평가하기 위해 여러 모델을 학습시키며 이들을 켜고 끄는 실험을 진행하였다. 손실에는 분류 손실, ℓ1 경계 상자 거리 손실, 그리고 GIoU [38] 손실의 세 가지 구성 요소가 있다. 분류 손실은 학습에 필수적이므로 끌 수 없어서, 경계 상자 거리 손실이 없는 모델과 GIoU 손실이 없는 모델을 학습시키고, 세 가지 손실 모두로 학습된 베이스라인과 비교하였다. 결과는 Table 4에 제시되어 있다.
- Table 4. 손실 구성 요소가 AP에 미치는 영향. ℓ1 손실과 GIoU 손실을 끈 두 개의 모델을 학습시켰으며, ℓ1 자체만으로는 좋지 않은 결과를 보이지만 GIoU와 결합했을 때 과 을 향상시키는 것을 관찰하였다. 베이스라인(마지막 행)은 두 손실을 모두 결합한다

GIoU 손실 자체만으로도 모델 성능의 대부분을 차지하며, 결합된 손실을 사용한 베이스라인에 비해 단 0.7 AP만 잃는다. GIoU 없이 ℓ1을 사용하는 것은 좋지 않은 결과를 보여준다. 동일한 가중치를 사용한 다른 손실들의 단순한 ablation만을 연구했지만, 이들을 결합하는 다른 방법들은 다른 결과를 달성할 수도 있다.
4.3 Analysis
디코더 출력 슬롯 분석 (Decoder output slot analysis)
Figure 7에서는 COCO 2017 검증 세트의 모든 이미지에 대해 다른 슬롯에 의해 예측된 상자들을 시각화하였다. DETR은 각 쿼리 슬롯에 대해 다른 전문화를 학습한다. 각 슬롯은 다른 영역과 상자 크기에 초점을 맞추는 여러 작동 모드를 갖는 것을 관찰하였다. 특히 모든 슬롯은 이미지 전체 크기의 상자를 예측하는 모드를 가지고 있다(플롯 중앙에 정렬된 빨간 점으로 보임). 이것이 COCO의 객체 분포와 관련이 있다고 추정된다.
- Figure 7. DETR 디코더의 총 N=100개 예측 슬롯 중 20개에 대해 COCO 2017 검증 세트의 모든 이미지에 대한 모든 상자 예측 시각화. 각 상자 예측은 각 이미지 크기로 정규화된 1×1 정사각형 내 중심 좌표를 갖는 점으로 표현된다. 점들은 색상으로 구분되어 녹색은 작은 상자, 빨간색은 큰 가로 상자, 파란색은 큰 세로 상자에 해당한다. 각 슬롯이 여러 작동 모드를 가지고 특정 영역과 상자 크기에 전문화되는 것을 학습함을 관찰하였다. 거의 모든 슬롯이 COCO 데이터셋에서 흔한, 이미지 전체 너비의 큰 상자를 예측하는 모드를 가지고 있음을 주목하였다.

보지 못한 인스턴스 수에 대한 일반화 (Generalization to unseen numbers of instances)
COCO의 일부 클래스는 동일 이미지 내에 동일 클래스의 많은 인스턴스로 잘 표현되지 않는다. 예를 들어, 학습 세트에는 13마리 이상의 기린이 있는 이미지가 없다. DETR의 일반화 능력을 검증하기 위해 합성 이미지를 생성하였다(Figure 5 참조). 이 모델은 분포에서 명확히 벗어난 이미지에서 24마리의 기린을 모두 찾을 수 있다. 이 실험은 각 객체 쿼리에 강한 클래스 전문화가 없다는 것을 확인해 준다.
- Figure 5. 희귀 클래스에 대한 분포 외 일반화(Out of distribution generalization). 학습 세트에는 13마리 이상의 기린이 있는 이미지가 없음에도 불구하고, DETR은 동일한 클래스의 24개 이상의 인스턴스로 일반화하는 데 어려움이 없다.

4.4 DETR for panoptic segmentation
Panoptic segmentation [19]은 최근 컴퓨터 비전 커뮤니티에서 많은 주목을 받았다. Faster R-CNN [37]을 Mask R-CNN [14]으로 확장하는 것과 유사하게, DETR은 디코더 출력 위에 마스크 헤드(mask head)를 추가하여 자연스럽게 확장될 수 있다. 이 섹션에서는 이러한 헤드가 stuff와 thing 클래스를 통합된 방식으로 처리하여 panoptic segmentation [19]을 생성하는 데 사용될 수 있음을 보여준다.
80개의 thing 카테고리에 더해 53개의 stuff 카테고리를 가진 COCO 데이터셋의 panoptic 주석에 대해 실험을 수행하였다. 동일한 방법을 사용하여 COCO에서 stuff와 thing 클래스 모두에 대한 상자를 예측하도록 DETR을 학습시켰다. Hungarian matching은 상자 간의 거리를 사용하여 계산되므로, 학습이 가능하려면 상자 예측이 필요하다. 또한 예측된 각 상자에 대해 이진 마스크(binary mask)를 예측하는 마스크 헤드를 추가하였다(Figure 8 참조). 이것은 각 객체에 대한 transformer 디코더의 출력을 입력으로 받아, 인코더의 출력에 대해 이 임베딩의 multi-head(M개의 헤드) attention 점수를 계산하여, 작은 해상도에서 객체당 M개의 attention 히트맵을 생성한다. 최종 예측을 만들고 해상도를 높이기 위해 FPN과 유사한 아키텍처가 사용된다. 아키텍처는 보충 자료에서 더 자세히 설명한다. 마스크의 최종 해상도는 stride 4를 가지며, 각 마스크는 DICE/F-1 손실 [28]과 Focal 손실 [23]을 사용하여 독립적으로 감독된다.
- Figure 8. Panoptic head의 구조. 탐지된 각 객체에 대해 이진 마스크(binary mask)가 병렬로 생성된 다음, 픽셀 단위 argmax를 사용하여 마스크가 병합된다.
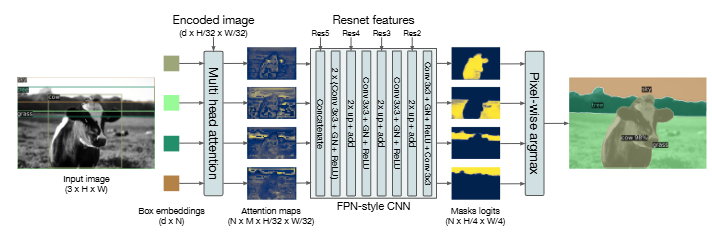
마스크 헤드는 공동으로 학습되거나, 또는 DETR을 상자에 대해서만 학습시킨 다음 모든 가중치를 고정하고 마스크 헤드만 25 epoch 동안 학습시키는 2단계 프로세스로 학습될 수 있다. 실험적으로 이 두 접근 방식은 비슷한 결과를 제공하며, 후자의 방법이 총 wall-clock 학습 시간을 단축시키므로 이 방법을 사용하여 결과를 보고한다.
최종 panoptic segmentation을 예측하기 위해 각 픽셀에서 마스크 점수에 대해 argmax를 사용하고, 결과 마스크에 해당하는 카테고리를 할당한다. 이 절차는 최종 마스크들이 겹치지 않도록 보장하므로, DETR은 서로 다른 마스크를 정렬하는 데 자주 사용되는 휴리스틱 [19]을 필요로 하지 않는다.
학습 세부사항 (Training details)
COCO 데이터셋에서 stuff와 thing 클래스 주변의 상자를 예측하기 위해 경계 상자 탐지 방법에 따라 DETR, DETR-DC5, DETR-R101 모델을 학습시켰다. 새로운 마스크 헤드는 25 epoch 동안 학습된다(자세한 내용은 보충 자료 참조). 추론 중에는 먼저 신뢰도가 85% 미만인 탐지를 걸러낸 다음, 픽셀별 argmax를 계산하여 각 픽셀이 어떤 마스크에 속하는지 결정한다. 그런 다음 동일한 stuff 카테고리의 다른 마스크 예측을 하나로 합치고, 빈 것(4픽셀 미만)을 걸러낸다.
주요 결과 (Main results)
정성적 결과는 다음 Figure 9에 나와 있다.
- Figure 9. DETR-R101에 의해 생성된 panoptic segmentation에 대한 정성적 결과. DETR은 thing과 stuff에 대해 통합된 방식으로 정렬된 마스크 예측을 생성한다.
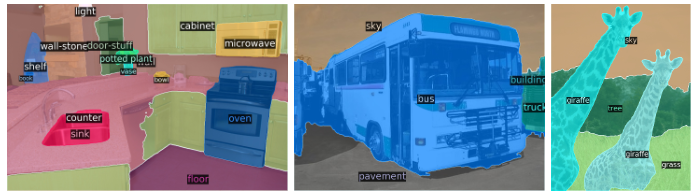
Table 5에서 본 논문은 통합된 panoptic segmentation 접근 방식을 thing과 stuff를 다르게 처리하는 여러 기존 방법들과 비교한다. Panoptic Quality (PQ)와 thing(PQth) 및 stuff(PQst)에 대한 분석 결과를 보고한다. 또한, (우리의 경우, 픽셀별 argmax를 취하기 전) panoptic 후처리 이전에 (thing 클래스에 대해 계산된) 마스크 AP도 보고한다. 본 논문은 DETR이 COCO-val 2017에 대해 발표된 결과뿐만 아니라, (공정한 비교를 위해 DETR과 동일한 데이터 증강으로 학습된) 강력한 PanopticFPN 기준 모델보다도 뛰어난 성능을 보임을 보여준다.
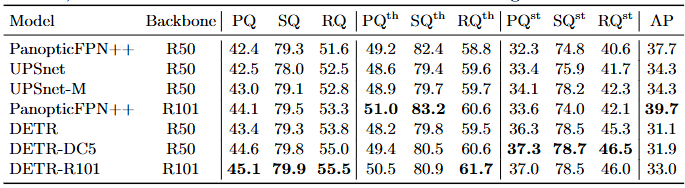
- Table 5. COCO val 데이터셋에서 최신 기법인 UPSNet [51] 및 Panoptic FPN [18]과의 비교. 공정한 비교를 위해 DETR과 동일한 데이터 증강으로 18x 스케줄에서 PanopticFPN을 재학습시켰다. UPSNet은 1x 스케줄을 사용하며, UPSNet-M은 다중 스케일 테스트 시간 증강을 사용한 버전이다.
결과 분석은 DETR이 특히 stuff 클래스에서 우세하다는 것을 보여주며, 본 논문은 인코더 어텐션에 의해 허용된 전역적 추론이 이 결과의 핵심 요소라고 가정한다. thing 클래스의 경우, 마스크 AP 계산에서 기준 모델에 비해 최대 8 mAP의 심각한 격차에도 불구하고 DETR은 경쟁력 있는 PQth를 얻는다. 본 논문은 또한 COCO 데이터셋의 테스트 세트에서 우리의 방법을 평가했고, 46 PQ를 얻었다. 본 논문의 접근 방식이 향후 완전 통합된 panoptic segmentation 모델 탐구에 영감을 주기를 희망한다.
5. Conclusion
본 논문은 직접적인 집합 예측(direct set prediction)을 위해 transformer와 이분 매칭 손실(bipartite matching loss)에 기반한 객체 탐지 시스템의 새로운 설계인 DETR을 제시하였다. 이 접근 방식은 까다로운 COCO 데이터셋에서 최적화된 Faster R-CNN 기준 모델과 견줄 만한 결과를 달성한다.
DETR은 구현이 간단하고, 경쟁력 있는 결과와 함께 panoptic segmentation으로 쉽게 확장될 수 있는 유연한 아키텍처를 가지고 있다. 또한 self-attention에 의해 수행되는 전역 정보 처리 덕분에 Faster R-CNN보다 대형 객체에서 훨씬 더 나은 성능을 달성한다. 탐지기를 위한 이 새로운 설계는 특히 소형 객체에 대한 학습, 최적화 및 성능과 관련하여 새로운 과제들을 동반한다. 현재의 탐지기들은 유사한 문제에 대처하기 위해 수년간의 개선이 필요했으며, 향후 연구가 DETR에 대해 이러한 문제들을 성공적으로 해결할 것으로 기대한다.
Appendix
A.1 Preliminaries: Multi-head attention layer
본 논문의 모델은 Transformer 아키텍처를 기반으로 하므로, 완전성을 위해 여기서 사용하는 attention 메커니즘의 일반적인 형태를 다시 설명한다. Attention 메커니즘은 [47]을 따르며, 위치 인코딩의 세부사항(수식 8 참조)은 [7]을 따른다.
- Multi-head
차원 d를 가진 M개의 헤드로 구성된 multi-head attention의 일반적인 형태는 다음과 같은 시그니처를 가진 함수이다 (을 사용하고, 행렬/텐서 크기를 밑줄로 표시):
여기서 는 길이 인 쿼리 시퀀스, 는 길이 인 키-값 시퀀스(설명의 단순성을 위해 동일한 채널 수 ), 쿼리, 키, 값 임베딩을 계산하는 가중치 텐서, 은 투영 행렬이다. 출력은 쿼리 시퀀스와 동일한 크기이다.세부사항을 제공하기 전에 용어를 정의하면, multi-head self-attention (mh-s-attn)은 인 특별한 경우이다:
Multi-head attention은 개의 단일 attention 헤드를 연결한 후 로 투영한 것이다. 일반적으로 [47]에서는 잔차 연결(residual connections), dropout, layer normalization을 사용한다. 즉, 이고 를 attention 헤드들의 연결(concatenation)이라고 하면:
여기서 [;]는 채널 축에서의 연결을 나타낸다.
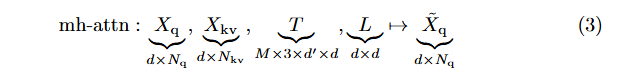
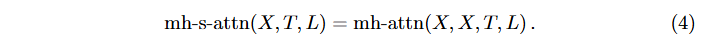
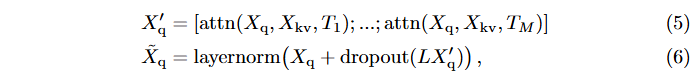
- Single head
가중치 텐서 를 가진 attention 헤드 는 추가적인 위치 인코딩 에 의존한다. 쿼리와 키 위치 인코딩을 추가한 후 쿼리, 키, 값 임베딩을 계산하는 것으로 시작한다 [7]:
여기서 는 , , 의 연결이다. Attention 가중치 는 쿼리와 키 간의 내적에 softmax를 적용하여 계산되며, 이를 통해 쿼리 시퀀스의 각 요소가 키-값 시퀀스의 모든 요소에 주의를 기울이게 된다 (는 쿼리 인덱스, 는 키-값 인덱스):
여기서 위치 인코딩은 학습되거나 고정될 수 있지만, 주어진 쿼리/키-값 시퀀스에 대해 모든 attention 레이어에서 공유되므로, attention의 매개변수로 명시적으로 표기하지 않는다. 인코더와 디코더를 설명할 때 정확한 값에 대한 더 자세한 내용을 제공한다. 최종 출력은 attention 가중치로 가중된 값들의 집계이다: i번째 행은 로 계산된다.
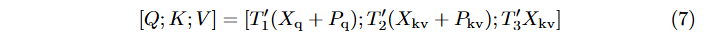
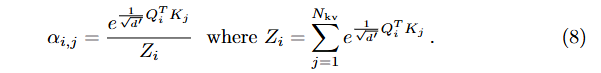
- Feed-forward network (FFN) 레이어
원래 transformer는 multi-head attention과 FFN 레이어 [47]를 번갈아 사용하는데, 이는 효과적으로 multilayer 1×1 컨볼루션으로 본 논문의 경우 개의 입력과 출력 채널을 가진다. 여기서 사용하는 FFN은 ReLU 활성화 함수를 가진 두 층의 1×1 컨볼루션으로 구성된다. Equation 6과 유사하게 두 층 이후에 잔차 연결/dropout/layernorm도 포함된다.
A.2 Losses
완전성을 위해 우리 접근법에서 사용된 손실 함수들을 자세히 제시한다. 모든 손실은 배치 내 객체 수로 정규화된다. 분산 학습의 경우 추가적인 주의가 필요하다: 각 GPU가 하위 배치를 받기 때문에, 일반적으로 하위 배치들이 GPU 간에 균형을 이루지 않으므로 로컬 배치의 객체 수로 정규화하는 것만으로는 충분하지 않다. 대신 모든 하위 배치의 총 객체 수로 정규화하는 것이 중요하다.
- Box loss
[41,36]과 유사하게, 손실에서 Intersection over Union(IoU)의 소프트 버전을 b̂에 대한 ℓ1 손실과 함께 사용한다:
여기서 , 는 하이퍼파라미터이고 는 일반화된 IoU [38]이다:
는 "면적"을 의미하고, 상자 좌표의 합집합과 교집합은 상자 자체의 줄임말로 사용된다. 합집합이나 교집합의 면적은 와 의 선형 함수의 min/max로 계산되며, 이는 확률적 그래디언트에 대해 손실을 충분히 안정적으로 만든다. 를 포함하는 가장 큰 상자를 의미한다 (와 관련된 면적들도 상자 좌표의 선형 함수의 min/max를 기반으로 계산됨).
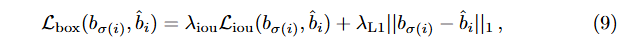
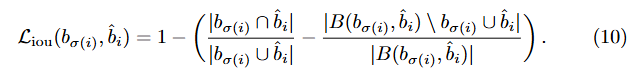
- DICE/F-1 loss [28]
DICE 계수는 Intersection over Union과 밀접한 관련이 있다. 를 모델의 원시 마스크 로짓 예측이라 하고, 을 이진 목표 마스크라고 하면, 손실은 다음과 같이 정의된다:
여기서 는 시그모이드 함수이다. 이 손실은 객체 수로 정규화된다.
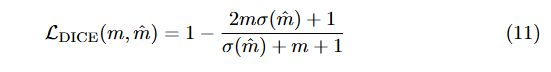
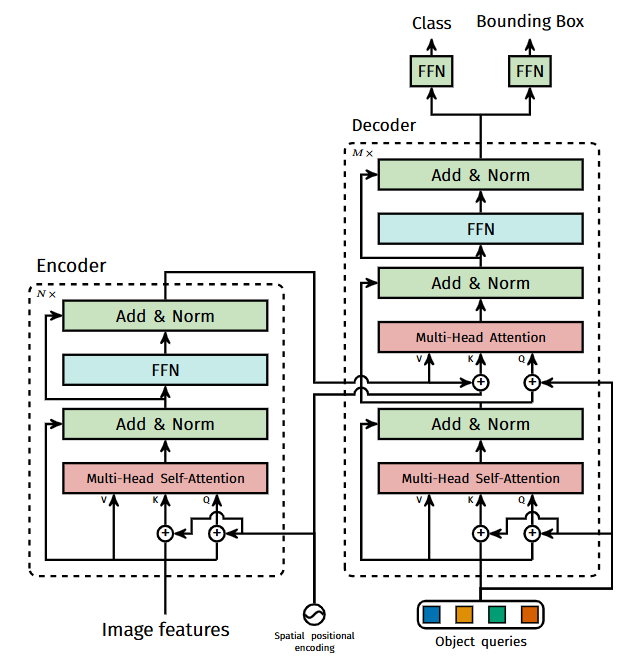
A.3 Detailed architecture
모든 attention 레이어에서 위치 인코딩이 전달되는 DETR에서 사용된 transformer의 세부 설명은 Figure 10에 제시되어 있다. CNN 백본의 이미지 특징은 모든 multi-head self-attention 레이어에서 쿼리와 키에 추가되는 공간적 위치 인코딩과 함께 transformer 인코더를 통과한다. 그 다음, 디코더는 쿼리(초기에 0으로 설정), 출력 위치 인코딩(object queries), 그리고 인코더 메모리를 받아서 multiple multi-head self-attention과 디코더-인코더 attention을 통해 최종 예측된 클래스 라벨과 바운딩 박스 집합을 생성한다. 첫 번째 디코더 레이어의 첫 번째 self-attention 레이어는 생략할 수 있다.
- Figure 10. Architecture of DETR’s transformer. 구조에 대한 자세한 정보는 A.3 참조.
- Computational complexity
인코더의 모든 self-attention은 복잡도를 가진다: 는 단일 쿼리/키/값 임베딩을 계산하는 비용이고 (그리고 ), 는 하나의 헤드에 대한 attention 가중치를 계산하는 비용이다. 다른 계산들은 무시할 수 있다. 디코더에서 각 self-attention은 이고, 인코더와 디코더 간의 cross-attention은 인데, 실제로 이므로 인코더보다 훨씬 낮다.
- FLOPS computation
Faster R-CNN의 FLOPS는 이미지 내 제안(proposal) 수에 의존하므로, COCO 2017 검증 세트의 첫 100개 이미지에 대한 평균 FLOPS 수를 보고한다. Detectron2 [50]의 flop count operators 도구로 FLOPS를 계산한다. Detectron2 모델에는 수정 없이 사용하고, DETR 모델에는 배치 행렬 곱셈()을 고려하도록 확장한다.
A.4 Training hyperparameters
개선된 가중치 감쇠 처리를 포함한 AdamW [26]를 사용하여 DETR을 학습시키며, 가중치 감쇠는 로 설정한다. 또한 최대 그래디언트 노름을 0.1로 하는 그래디언트 클리핑을 적용한다. 백본과 transformer는 약간 다르게 처리되며, 이제 둘 다에 대한 세부사항을 논의한다.
-
Backbone
ImageNet 사전 학습된 백본 ResNet-50을 Torchvision에서 가져와서 마지막 분류 레이어를 제거한다. 객체 탐지에서 널리 채택된 관행에 따라 백본 배치 정규화 가중치와 통계량은 학습 중에 고정된다. 의 학습률을 사용하여 백본을 미세 조정한다. 백본 학습률을 네트워크의 나머지 부분보다 약 한 자릿수 작게 하는 것이 학습을 안정화하는 데 중요하며, 특히 처음 몇 epoch에서 그렇다는 것을 관찰했다. -
Transformer
의 학습률로 transformer를 학습시킨다. 층 정규화 이전에 모든 multi-head attention과 FFN 이후에 0.1의 가산적 dropout을 적용한다. 가중치는 Xavier initialization으로 무작위로 초기화된다. -
Losses
바운딩 박스 회귀에 대해 각각 , 가중치를 가진 과 GIoU 손실의 선형 결합을 사용한다. 모든 모델은 개의 디코더 쿼리 슬롯으로 학습되었다. -
Baseline
강화된 Faster-RCNN+ 베이스라인은 바운딩 박스 회귀에 대해 표준 손실과 함께 GIoU [38] 손실을 사용한다. 손실에 대한 최적의 가중치를 찾기 위해 격자 탐색을 수행했으며, 최종 모델은 박스 및 제안 회귀 작업에 대해 각각 20과 1의 가중치를 가진 GIoU 손실만 사용한다. 베이스라인에는 DETR에서 사용된 것과 동일한 데이터 증강을 채택하고 9× 스케줄(약 109 epoch)로 학습시킨다. 다른 모든 설정은 Detectron2 모델 zoo [50]의 동일한 모델과 동일하다. -
Spatial positional encoding
인코더 활성화는 이미지 특징의 해당 공간적 위치와 연관된다. 우리 모델에서는 이러한 공간적 위치를 나타내기 위해 고정된 절대 인코딩을 사용한다. 원래 Transformer [47] 인코딩을 2D case [31]로 일반화한 것을 채택한다. 구체적으로, 각 임베딩의 두 공간적 좌표 모두에 대해 서로 다른 주파수를 가진 개의 사인 및 코사인 함수를 독립적으로 사용한다. 그 다음 이들을 연결하여 최종 채널 위치 인코딩을 얻는다.
A.5 Additional results
DETR-R101 모델의 panoptic 예측에 대한 몇 가지 추가적인 정성적 결과가 Figure 11에 제시되어 있다.
- Figure 11. Panoptic 예측 비교. 왼쪽부터 오른쪽으로 : 정답(Ground truth), ResNet 101을 사용한 PanopticFPN, ResNet 101을 사용한 DETR 순서
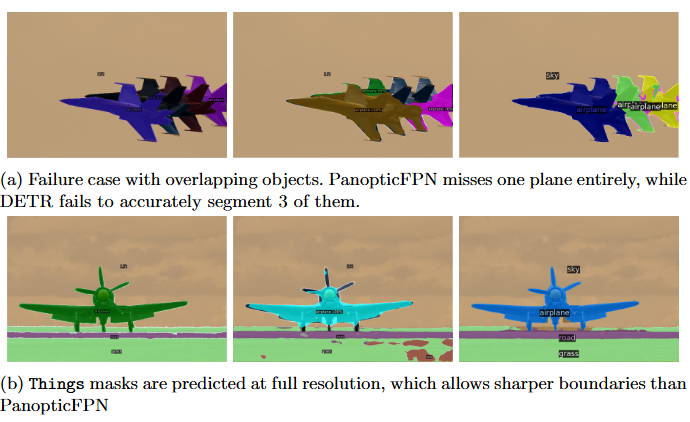
- 인스턴스 수 증가 (Increasing the number of instances)
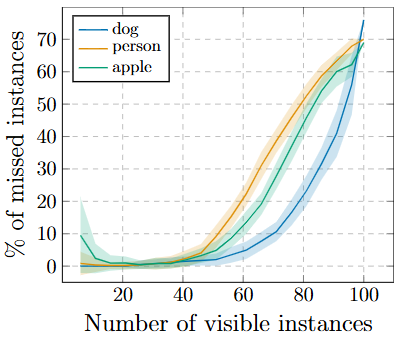
설계상 DETR은 가지고 있는 쿼리 슬롯보다 많은 객체를 예측할 수 없다. 즉, 우리 실험에서는 100개이다. 이 섹션에서는 이 한계에 접근할 때 DETR의 행동을 분석한다. 주어진 클래스의 정규 정사각형 이미지를 선택하고, 이를 10×10 격자에서 반복한 다음, 모델이 놓친 인스턴스의 비율을 계산한다. 100개 미만의 인스턴스로 모델을 테스트하기 위해 일부 셀을 무작위로 마스킹한다. 이는 표시되는 개수에 관계없이 객체의 절대 크기가 동일하도록 보장한다. 마스킹의 무작위성을 고려하여 서로 다른 마스크로 실험을 100번 반복한다. 결과는 Figure 12에 제시되어 있다.
클래스 간에 유사한 행동을 보이며, 50개까지 표시될 때는 모델이 모든 인스턴스를 탐지하지만, 그 후부터는 포화되기 시작하여 점점 더 많은 인스턴스를 놓친다. 특히 이미지에 100개의 인스턴스가 모두 포함될 때, 모델은 평균적으로 30개만 탐지하는데, 이는 모두 탐지되는 50개의 인스턴스만 포함된 이미지보다 적다. 모델의 이러한 직관에 반하는 행동은 이미지와 탐지가 학습 분포와 크게 다르기 때문일 가능성이 높다.
- Figure 12. 이미지에 존재하는 인스턴스 수에 따라 DETR이 놓친 다양한 클래스의 인스턴스 수 분석. 평균과 표준편차를 보고한다. 인스턴스 수가 100개에 가까워질수록 DETR은 포화되기 시작하여 점점 더 많은 객체를 놓친다.
A.6 PyTorch inference code
접근법의 단순성을 보여주기 위해 PyTorch 및 Torchvision 라이브러리를 사용한 추론 코드를 Listing 1에 포함한다. 이 코드는 Python 3.6+, PyTorch 1.4, Torchvision 0.5에서 실행된다. 배치 처리를 지원하지 않으므로 추론 또는 GPU당 하나의 이미지로 을 사용한 학습에만 적합하다. 또한 명확성을 위해 이 코드는 인코더에서 고정된 위치 인코딩 대신 학습된 위치 인코딩을 사용하고, 위치 인코딩은 각 transformer 레이어가 아닌 입력에만 추가된다.
- Listing 1. DETR PyTorch 추론 코드. 명확성을 위해 인코더에서 고정된 위치 인코딩 대신 학습된 위치 인코딩을 사용하고, 위치 인코딩은 각 transformer 레이어가 아닌 입력에만 추가된다.

