[diffusion planner] DIFFUSION-BASED PLANNING FOR AUTONOMOUS DRIVING WITH FLEXIBLE GUIDANCE
diffusion planning
Introduction
rule based planning의 단점- 새로운 환경에 대한 적응력이 떨어짐
- 각 상황마다 규칙을 바꾸는 것은 과도한 engineering 노력이 필요함
learning based planning- 기대 효과: 학습 자원이 많아질수록 -> 성능이 선형적으로 증가할 가능성
- OOD에 대한 적응력이 좋지 못해서 -> rule-based refinement module을 필요로 하는데
- 이는 rule based planning 의 단점(=새로운 환경에 대한 적응력 낮음)을 그대로 이어받는다.
- 이미 학습된 모델은, specific needs를 만족시키기 위한 행동에 적응시키기 어렵다.
- diffusion
- diffusion 적용으로 인해 (
rule-based refinement 없이도) 훌륭한 trajectory quality를 도출함.
- diffusion 적용으로 인해 (
- 우리의 diffusion model
- trajectory score function의 gradient 를 학습
- score function diffusion 알고리즘을 기반으로 했음
- 우리의 학습 목표는 noisy data로부터 data distribution을 회복하는 것
- 아키텍쳐
- 같은 아키텍쳐 내에서, 주변 차량 prediction과 자차량 planning을 동시에 모델링
- guidance sampling을 통해
- 추가적인 loss function 없이도, 주변 차량의 미래 예측 궤적들과 충돌하지 않는 ego 미래 궤적을 선택할 수 있다.
- guidance sampling을 통해
- 같은 아키텍쳐 내에서, 주변 차량 prediction과 자차량 planning을 동시에 모델링
- classifier guidance
- 추가적인 학습이 필요 없는 유연한 방법. 미분가능한 classifier score을 도입하기만 하면 됩니다.
sub-optimal post-processing과는 다르게, 모델의 내재적 능력을 향상시키는 방법임
- 성능
- Diffusion Planner w guidance sampling +
w/o refinement- 기존 학습 기반 방법보다 좋았고,
- rule-based 방법과 필적했다.
- Diffusion Planner w guidance sampling +
w refinement- 모든 방법과 비교해서 성능이 더 좋았다.
- 더 부드러운 궤적을 생성했다.
- Diffusion Planner w guidance sampling +
2. Related work
- TODO: 필요할 때 공부할 것
3 . Preliminaries
3.2. diffusion model and guidance schemes
- diffusion 의 역과정을 ODE로 표현 가능.

- TODO: 위 사진 수식 전부 이해하기
4. Methodology
- (주변 차량 수)를 너무 많이 하면 성능이 떨어지더라.

input
- 자차 주변의 100m 반경에 있는 lane과 navigation information을 활용했음
- 각 데이터 타입은 model input의 통일된 차원을 위해 padding 되었다.
- 그리고, 불필요한 정보를 제거하기 위해, attention masking이 사용되었다.
navigation information (25, 20, 12)
- 목적지까지 가기 위해, 내가 미래에 이용가능한 모든 차선(1~n 차선들 중, 목적지에 가기 위해 내가 있어도 되는 차선들)들에 대한 정보 (직진만 해도 되는 상황이면 모든 차선 전부 가능.좌회전 하는 경우에서는 좌회전 차선만 가능)
- Nuplan 데이터셋에서는, 자차의 현재위치에서 목적지까지 가는데에 거쳐야할 road block(여러 차선들의 뭉치/섹션)들을 명시해 놓았음
- 이 road blocks 중, 아래 2가지 기준으로 필터링
- ego가 이미 지나친 blocks는 제외하고
- 100m 반경 내만 필터링
- 이렇게 필터링된 road blocks에 해당하는 모든 차선들 중, 25개를 input으로 넣습니다.
- 20: 점의 갯수
- 1개 차선을 점의 집합으로 표현하는데, 최대 20개로 표현한다.
- 12: 점 1개의 특징들 (아래와 같음)
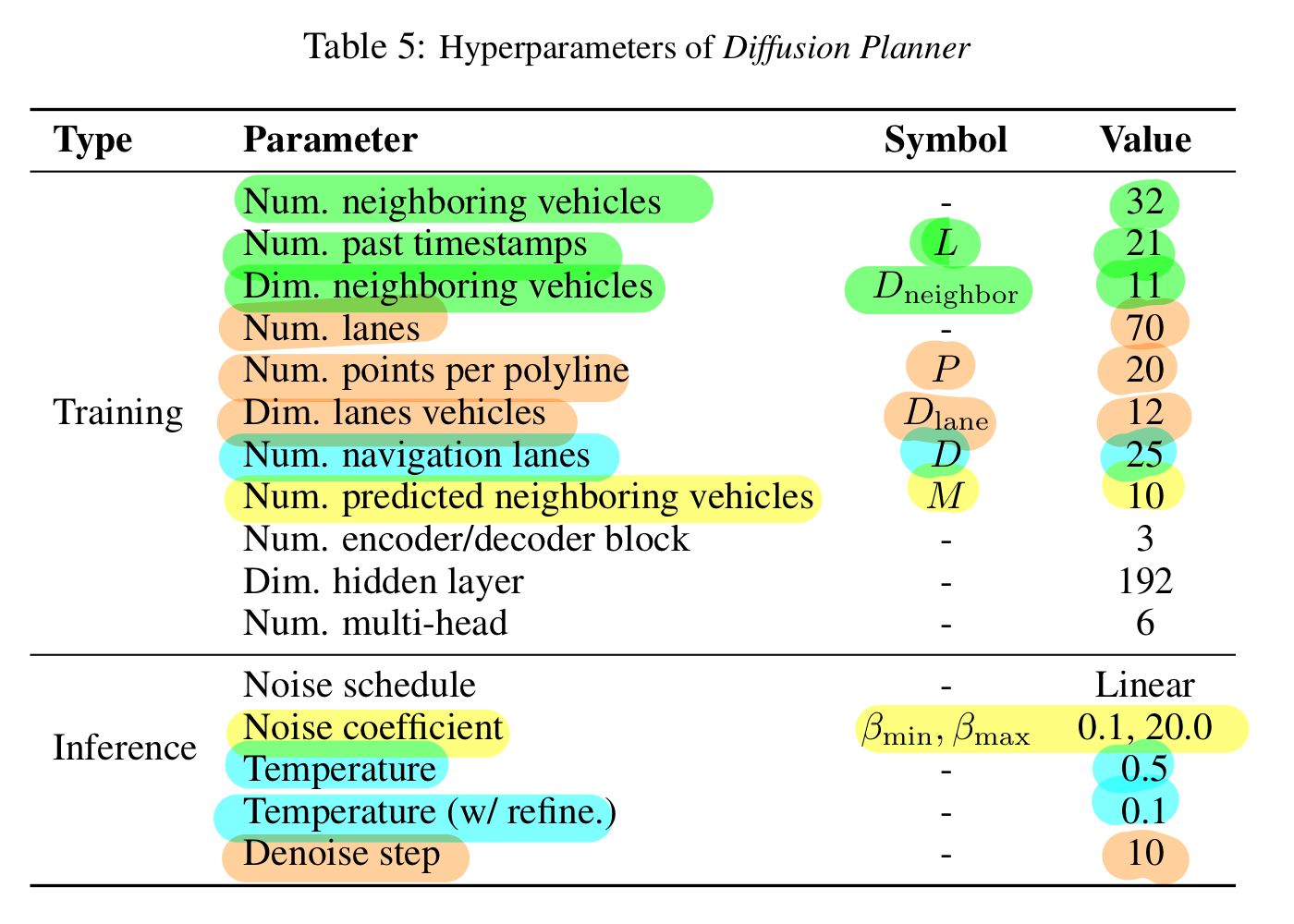
차원 범위 | 설명 | 세부 설명
0-1 | Polyline 좌표 (x, y)
해당 차선의 중앙선(중심선) 좌표를 나타냅니다. 각 포인트의 위치 정보로, (x, y) 값입니다.
2-3 | Polyline 벡터 (dx, dy)
인접한 포인트 간의 차이를 계산하여 얻은 벡터입니다. 즉, (다음 포인트 - 현재 포인트)로, 진행 방향 및 국소 변화량을 표현합니다. 마지막 포인트는 0으로 채워집니다.
4-5 | 왼쪽 경계까지의 벡터 (dx, dy)
해당 포인트에서 왼쪽 경계선까지의 차이 벡터입니다. 차선 중앙에서 왼쪽 경계까지의 오프셋을 나타냅니다.
6-7 | 오른쪽 경계까지의 벡터 (dx, dy)
해당 포인트에서 오른쪽 경계선까지의 차이 벡터입니다. 차선 중앙에서 오른쪽 경계까지의 오프셋을 나타냅니다.
8-11 | 교통 신호 원-핫 인코딩 (4차원)
해당 포인트의 차선 구간에 적용되는 교통 신호 상태를 원-핫 인코딩한 벡터입니다. 보통 [green, yellow, red, unknown] 등의 순서로 표현됩니다.
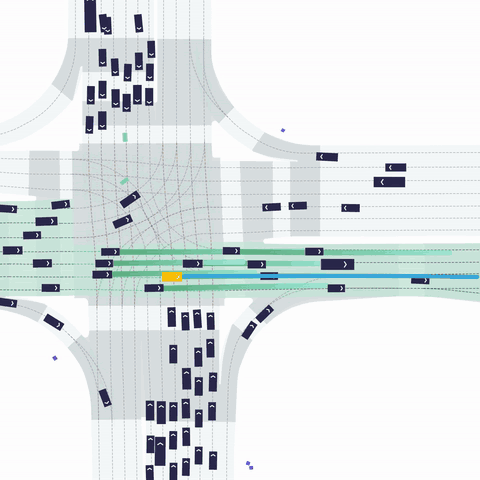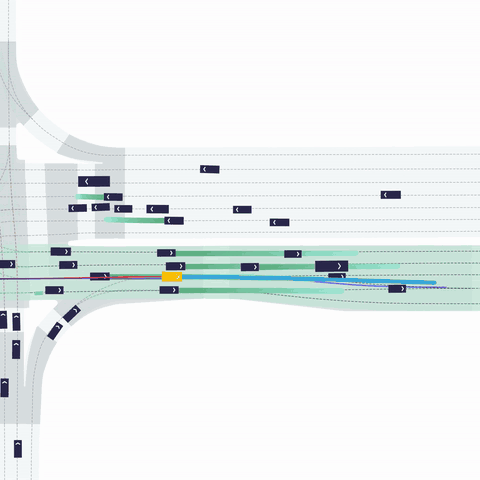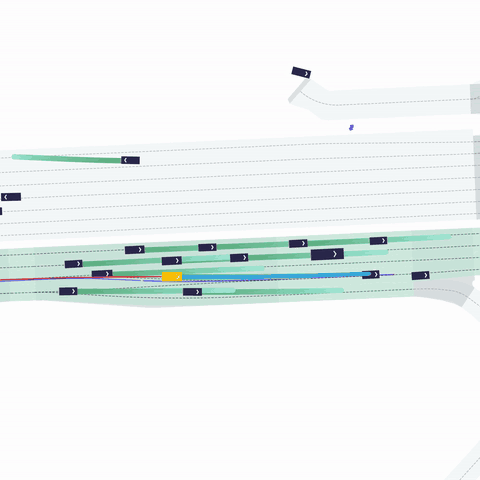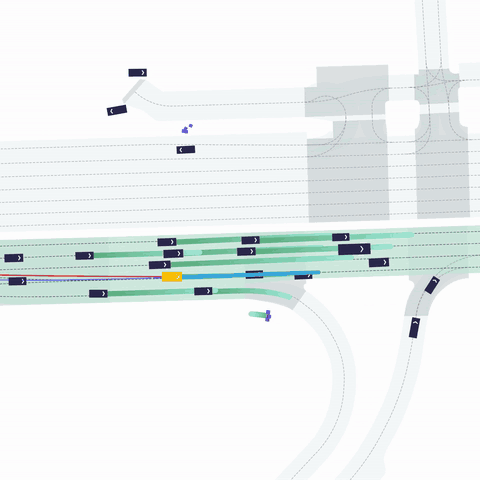
주변 agents 정보: (32, 21, 11)
- 최대 32개 차량
- 주변 agent의 과거 history 정보는 2초 이용했다. (0.1초 간격으로 과거 20개 점 + 현재 점)
- 각 점의 11개 정보
- [x, y, cos(yaw), sin(yaw), v_x, v_y, width, length, 1, 0 , 0]
- VEHICLE / PEDESTRIAN / BICYCLE 클래스 정보를 one-hot 으로 제공
Lanes 정보: (70, 20, 12)
- 자차 주변 100m에 있는 차선들 중, 70개를 가져옴.
- 20: 각 차선을 점들의 잡합으로 표현하는데, 최대 20개로 구성함
- 각 점의 (차원 12)
차원 범위 | 설명 | 세부 설명
0-1 | Polyline 좌표 (x, y)
해당 차선의 중앙선(중심선) 좌표를 나타냅니다. 각 포인트의 위치 정보로, (x, y) 값입니다.
2-3 | Polyline 벡터 (dx, dy)
인접한 포인트 간의 차이를 계산하여 얻은 벡터입니다. 즉, (다음 포인트 - 현재 포인트)로, 진행 방향 및 국소 변화량을 표현합니다. 마지막 포인트는 0으로 채워집니다.
4-5 | 왼쪽 경계까지의 벡터 (dx, dy)
해당 포인트에서 왼쪽 경계선까지의 차이 벡터입니다. 차선 중앙에서 왼쪽 경계까지의 오프셋을 나타냅니다.
6-7 | 오른쪽 경계까지의 벡터 (dx, dy)
해당 포인트에서 오른쪽 경계선까지의 차이 벡터입니다. 차선 중앙에서 오른쪽 경계까지의 오프셋을 나타냅니다.
8-11 | 교통 신호 원-핫 인코딩 (4차원)
해당 포인트의 차선 구간에 적용되는 교통 신호 상태를 원-핫 인코딩한 벡터입니다. 보통 [green, yellow, red, unknown] 등의 순서로 표현됩니다.

- 의 정보에는 속도 제한 정보는 넣지 않았는데, 그 이유는 아래와 같다.
- For target speed setting, we masked all lane speed limit information to prevent it from influencing the model’s planning,
- ensuring that speed adjustments are made solely through guidance.
- As a result, the model exhibited a lower speed without guidance.
- For target speed setting, we masked all lane speed limit information to prevent it from influencing the model’s planning,
Static Obj 정보: (5, 10)
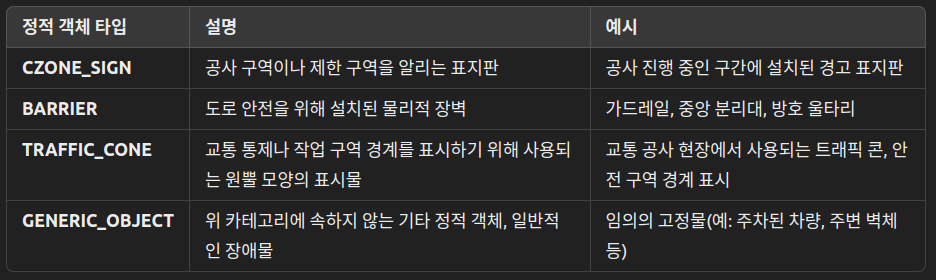
- 특정 유형(CZONE_SIGN, BARRIER, TRAFFIC_CONE, GENERIC_OBJECT)만 필터링 → 2) 에고 기준 거리순 정렬 → 3) 가장 가까운 ≤5 개 선택
- “10”은 각 객체를 표현하기 위해 등 총 10개의 특징을 사용한다는 뜻.
output
- 미래 8초의 자차/주변 차량 궤적을 10Hz로 생성 (0.1초마다 궤적을 생성. 즉 80개 점을 생성한다.)
- inference frequency는 20Hz 입니다. (A6000GPU에서 20Hz)
네트워크 아키텍쳐
-
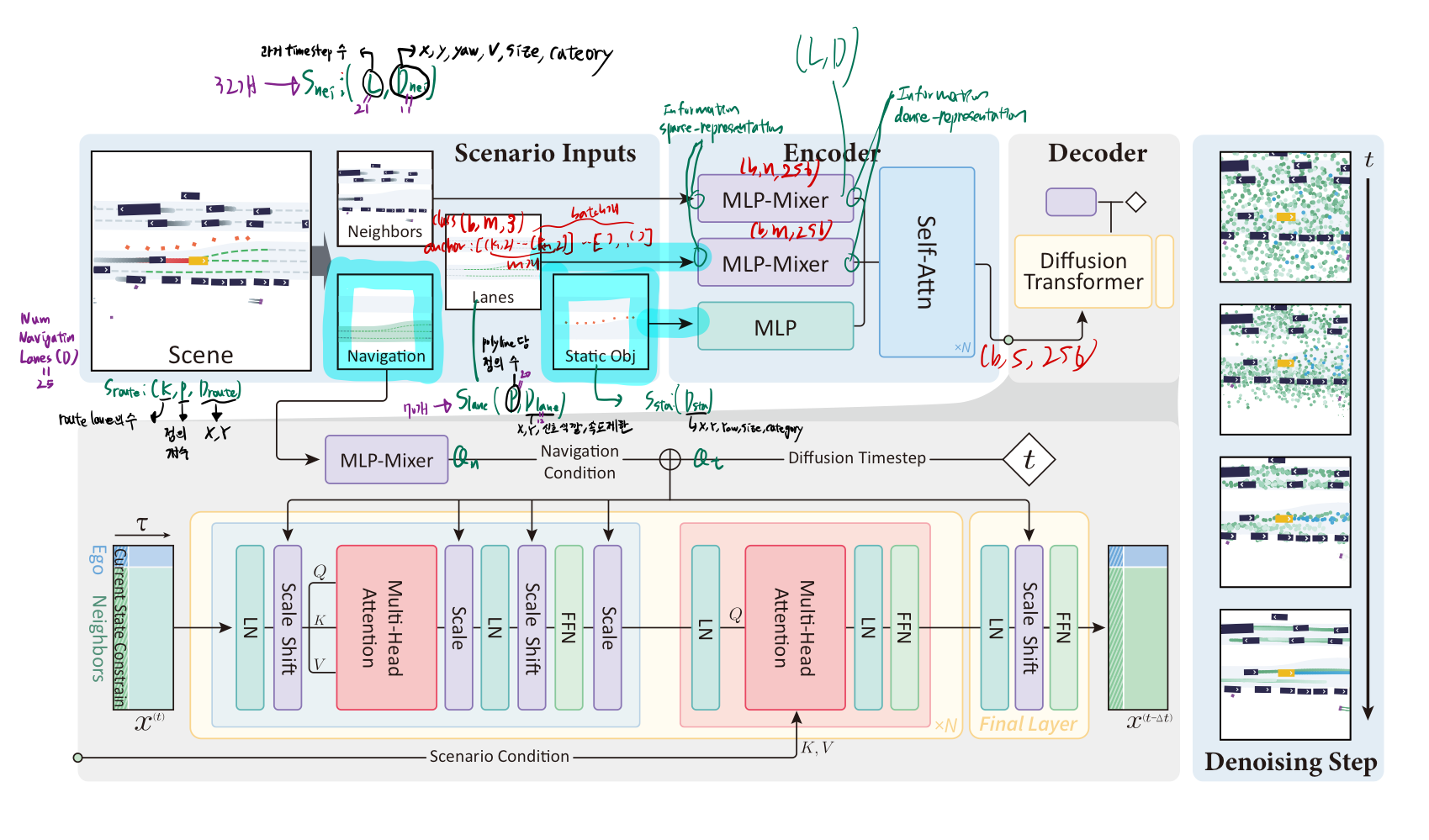
-
주변 차량 정보와 차선 정보, navigation information에 대해서 MLP-Mixer 을 사용했음
- 여러 mixing layers를 통과시킨 후에, 우리는 최종 output의 vector 차원에 대해 pooling을 적용했습니다.
- MLP-Mixer을 사용한 이유 (내 생각)
- 추론 속도 빨라짐!
- 계산 복잡도가 입력 토큰 수에 대해 선형적으로 증가함 (
추론 속도 감소!)- 반면, transformer은 제곱 복잡도를 지님
- 모든 연산이 MLP이므로 GPU에서 매우 빠르게 병렬화될 수 있다.
- 계산 복잡도가 입력 토큰 수에 대해 선형적으로 증가함 (
- 파라미터 수가 적음! (같은 성능을 내는 기준에서 비교했을 때)
- 추론 속도 빨라짐!
- MLP-Mixer을 사용했을 때의 위험성 (내 생각)
- 에이전트 간 상호작용이 매우 동적인 상황에서는 attention 연산이 효과적
- 차량 별로, 더 집중해야하는 agent가 다를 수 있음 -> attention 연산이 효과적
-
비교 항목 MLP-Mixer Transformer 목적/역할 희박한 벡터·폴리라인을 **간단하게 “농축”**해서 요약 벡터로 만들기 좋음 토큰들 사이의 세밀한 관계를 선택적으로 강조하며 모델링하기 좋음 표현력의 성격 규칙적으로 토큰/채널을 섞어 평균·요약하는 느낌 → 전역 요약에 유리 내용에 따라 어떤 토큰을 더 볼지 고르는 방식 → 미세한 상호작용에 유리 계산·메모리 보통 토큰 수에 거의 선형으로 늘어 비교적 가벼움 토큰 수가 커지면 비용 급증(상호참조 맵이 커짐) 길이 가변성 보통 고정 길이/패딩 전제로 쓰기 쉬움 가변 길이(이웃 수, 폴리라인 포인트 수 등) 자연 처리 용이 입력 설계 난이도 좌표·타입 등 기본 피처만으로 설계 단순 위치/관계 표현(예: 상대 위치, 세그먼트 연결성 등) 설계가 필요해 튜닝 부담 큼 전역 조건(예: AdaLN)로 쓰기 Mixer 출력이 전역 벡터로 바로 쓰기 쉬움 시퀀스 출력이라 풀링/추가 모듈로 전역 벡터를 만들어야 함 학습 안정성/하이퍼 구성 간단, 하이퍼 적어 안정적인 편 선택지 많아 하이퍼 파라미터·마스킹 설계가 복잡 해석/디버깅 구조 단순(원인 추적은 쉬움)이나 상호참조 시각화는 제한적 어떤 토큰을 봤는지 시각화(주의 맵) 가능 → 해석에 유리 잘 맞는 상황 - 리소스/지연 제약이 큼
- 전역 요약만 있어도 충분함
- route를 전역 가이드로만 쓸 때- 복잡한 상호작용이 핵심
- 가변 토큰 수가 많음
- 세밀한 구간/분기 강조가 필요잠재 제약 강한 요약으로 순서·연결 정보 일부 손실 가능 계산·메모리 무거워지기 쉬움, 프런트·백 모두 트랜스포머면 중복 복잡도 증가 이 논문 관점의 결론 프런트엔드엔 Mixer로 “희박→조밀” 요약, 백엔드(본체 DiT)에서 상호작용·생성 처리 → 단순·효율로 충분 프런트까지 트랜스포머로 바꾸면 **표현력·유연성↑**이나 비용·설계 복잡도↑ -
navigation information 은 (timestep 정보와 합쳐진 후),
adaptive layer norm block에 적용되었습니다. -
우리는 좀 더 통합되고 단순화된 아키텍쳐를 사용했습니다.
- diffusion transformer 기반으로 했다고 함
- 사용 이유
- transformer -> scalaiblity 가 좋다.
- adaLN-Zero
- 가장 계산 효율적이면서도 높은 성능 (실험으로 입증)
- Adaptive Layer Norm (adaLN) ??
- 조건 정보를 이용해 표준 Layer Norm의 스케일 및 시프트 파라미터를 동적으로 결정
- adaLN-Zero ??
- adaLN의 변형으로, residual 연결 전에 스케일링 파라미터를 0으로 초기화하여 학습 초기 identity function을 보장, 안정적인 학습을 도모
- adaLN에
Navigation Information과timestep만 주입하는 이유?- “전 층의 피처 전체에 전역적으로 영향을 주는” 신호임
- “모든 채널에 걸쳐 전역적으로 영향을 주는” 형태가 더 적합
- adaLN은 모델 내부 Feature를 전역적으로(채널 단위) 스케일 조절하여,
- 시점별/조건별 “강도, 스케일”을 조정
- “전 층의 피처 전체에 전역적으로 영향을 주는” 신호임
- 사용 이유
- diffusion transformer 기반으로 했다고 함
4.1. Task redefinition
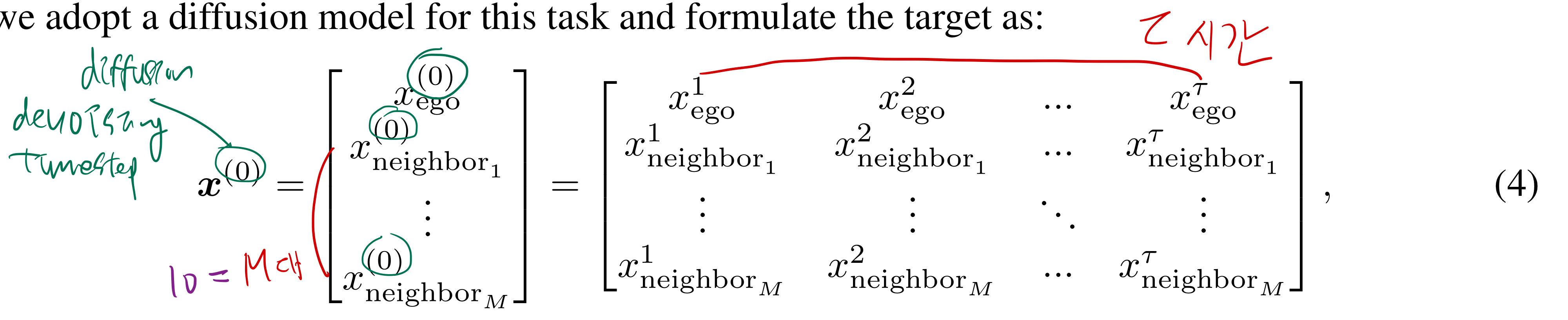
- future state
- coordiantes + sin(yaw) + cos(yaw)
- 위 state 정의만으로도, LQR controller에 충분합니다.
- 하지만, 자차의 속도와 가속도 정보가 제외되었는데, 다음 연구에서는 넣으면 좋을 것 같습니다.
4.2. Diffusion Planner
Vehicle Information Integration
- 위 future state 에, current state 를 추가 함.
- 논문에 따르면, current state 를 추가하는 것이 planning 능력에 향상을 주었다.
Historical Status and Lane Information
- 주변 차량들의 과거 status와 lane information은 vector을 이용해서 표현된다.
4.3 Planning behavior alignment via classifier guidance
- Diffusion Posterior Sampling 기법을 활용해서, (2022년 9월 논문, 674회 인용)
- classifier 추가 학습 없이
- 기 학습된 model(, 식 (5))을 이용하여 guidance energy를 근사할 수 있다.
Collision avoidance
- 목적: 자차와 주변 차량 간 충돌을 방지하기 위해, 자차의 궤적에 guidance
- 자차 미래 예측 궤적와 주변 차량 미래 예측 궤적간의 signed 거리 (매 timestamp마다 계산함)
- 만약 차량들의 bounding box가
- 겹치면 -> 우리는 최소 separation distance를 사용
- 그렇지 않으면 -> 가장 가까운 점들과의 거리를 계산

Target Speed Maintenance
최고/최저 목표 속도와생성된 Trajectory의 평균 속도의 차이를 계산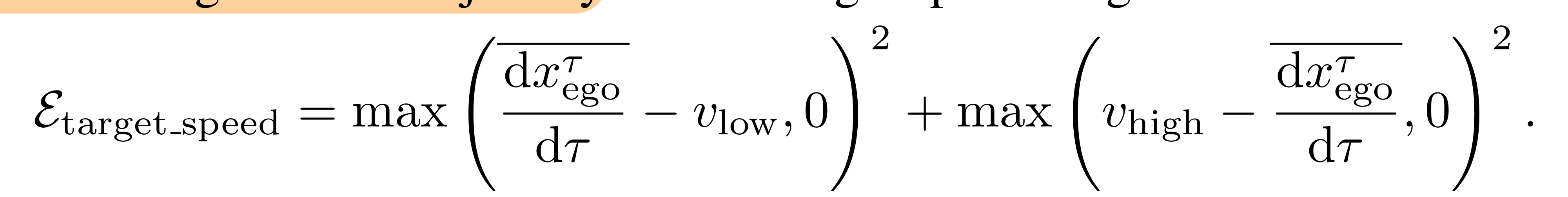
Comfort
- 여러 jerk를 고려함. 그 중
longitudinal jerk를 예시로 들자면,- 각 포인트(with 바로 옆 포인트)의 comfort 가 threshold를 넘으면 패널티를 주는 방식
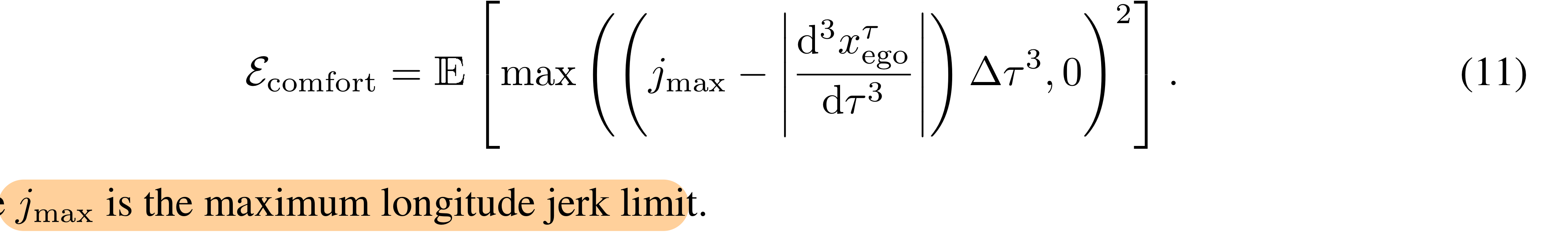
Staying within Drivable Area
- Euclidean Signed Distance Field with 병렬 연산 을 활용해서 미분 가능한 cost map을 구축한다.
- 자차가 치선을 넘었는지를 계산할 수 있게 해준다.
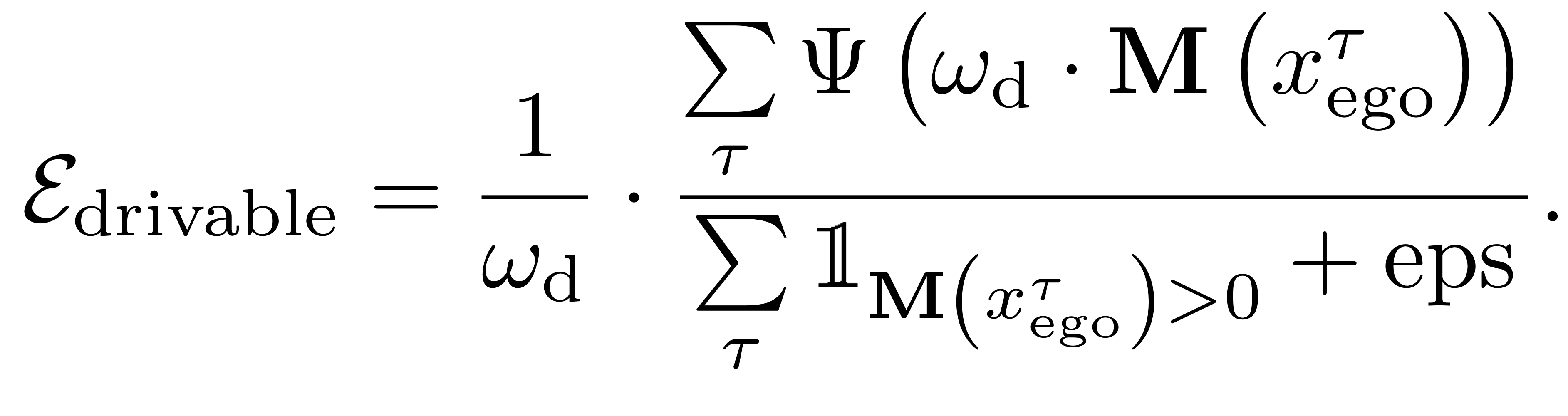
guidnace energy function 설계하는 팁들 소개
- 위에서 소개한 guidance들은 최적이 아닐 수 있다.
Smooth and continuous gradients
안전한 궤적들의 생성을 용이하게 하기 위해 필요
Gradient sparsity
- 특정한 상황들에서만 gradients가 생성되는 guidance function이 바람직
- 예: trajectory points가 potential collisions에 도달했을 경우부터 gradients를 준다.
Indirect guidance for higher-order state derivatives
- 고차 상태 미분 값(속도/가속도/각속도) 에 대해서는, position이나 heading을 통한 비간접적인 guidance를 주는것이 더 선호된다.
- 예를 들어, 궤적 속도를 제어하고 싶으면, 궤적 length를 guide 해라.
Consistent gradient magnitude
- 다른 조건에서도 근사적으로 일정하게 유지되는 gradient의 크기를 보장하는 것이 좋다.
- 쉽게 말해서,
다양한 cost function의 gradient 크기가 비슷한게 좋다. - 예: cost에 기여하는 많은 points 에 대해 평균 값을 취한다던지
4.4. Practical Implementation for closed-loop planning
Training Details
- 8 NVIDIA A100 80GB GPU를 사용했습니다.
- 2048 batch size 로 500 epoch 돌렸습니다.
- 5 epoch warmup phase (lr을 천천히 올리는 단계)
Datasets
- NuPlan dataset 에서 100만 시나리오를 가져와서 training set으로 썼다.
Data augmentation
- OOD issue를 완화하기 위해, data augmentation이 큰 도움이 됨 (planning에서 짱 많이 쓰는 기법임)
- 학습 전에, 우리는
자차의 current state에 random noise를 추가합니다. (x, y, theta, speed, accel)- 우리는 speed가 항상 0 보다 큰 조건 내에서 noising 합니다.
- TODO: 아래 말이 무슨 말일까? (공부해보자.)
- 물리적으로 말이 되는 transition을 생성하기 위해, interpolation을 적용합니다.
- model이 noise에 강인해지고, ground-truth 궤적으로 돌아가게 만들기 위해
- 구체적으로는, 5차 다항식 interpolation을 적용합니다. (ground truth trajectory를 대체합니다.)
- 물리적으로 말이 되는 transition을 생성하기 위해, interpolation을 적용합니다.
- 그 후, 우리는 데이터를 global coordinate -> ego-centric coordinate로 변경합니다.
- 학습 전에, 우리는
Normalization
- longitudinal과 lateral 거리 사이의 큰 차이가 있으므로, 우리는
z-score normalization을 도입합니다.- data distribution의 평균이 0이 될 수 있도록
- 이 방법은 학습 과정의 안정성을 향상시킵니다.
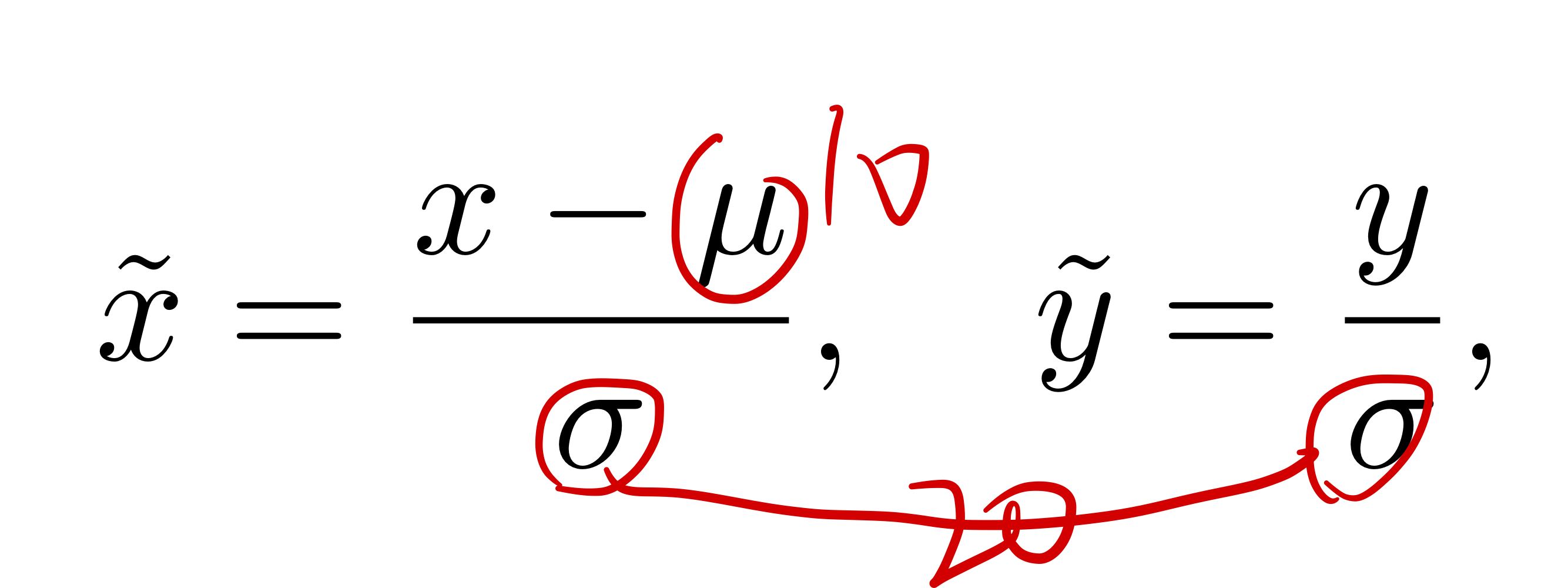
Inference Details
- DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps , 22년, 1237회 인용
- 위 논문의 방법(DPM-Solver++ 라고도 함)을 이용해서 faster sampling을 달성함
- variance-preserving noise schedule를 적용함
- ()
- ,
- IS CONDITIONAL GENERATIVE MODELING ALL YOU NEED FOR DECISION-MAKING?
, 22년, 375회 인용이라, 안봐도 될 것 같음- 위 논문의 방법을 이용해서 low-temperature(deterministic) sampling을 구현함
- denoising 과정의 안정성을 향상시키기 위해
- 위 논문의 방법을 이용해서 low-temperature(deterministic) sampling을 구현함
- refinement module이 없을 때
- high-temperature의 model output을 바로 쓰는 것이 => 고품질의 trajectories를 생성하는데 용이하다는 것을 발견
- refinement module이 있을 때
- lower-temperature이 더 안정적인 궤적들을 생성하는데에 도움이 된다는 것을 발견
- refinement module이 더 정확한 판단을 하는데에 도움이 된다고 함
Baseline Setup
- For IDM and UrbanDriver, we use the official nuPlan code, with the UrbanDriver checkpoint sourced from the PDM codebase, which also provides the checkpoints for PDM-Hybrid and PDM-Open. For PlanTF and PLUTO, we use the checkpoints from their respective official codebases. In the case of PLUTO w/o refine, we skip the post-processing code and rerun the simulation without retraining.
5. Experiments
5.0. 시작
Evaluation Setups
- 직접 만든 데이터셋
- 배달 차량으로 모은 데이터셋임
- 우리 모델은 nuPlan으로 학습했는데, 이 데이터셋에서도 성능 좋았음 (좋은 transfoerability)
- To further validate the algorithm’s performance across diverse driving scenarios and with vehicles exhibiting different driving behaviors, we collected 200 hours of real-world data using a delivery vehicle from Haomo.AI. Unlike nuPlan, the delivery vehicle demonstrates more conservative planning behavior and operates in bike lanes, which involve dense human-vehicle interactions and unique traffic reg- ulations. The collected data were integrated into the nuPlan framework
- 더 궁금하면 Appendix D를 참고해라.
Baselines
non-diffusion baselines
- 아래 3그룹으로 나눔
- Rule-based, Learning-based, Hybrid
- Hybrid: 학습 기반 모델의 outputs를 추가적으로 정제
- Rule-based, Learning-based, Hybrid
- learning-based baseline과 본 논문 알고리즘에 Generalizing Motion Planners with Mixture of Experts for Autonomous Driving 혹은 (논문) 의 refinement module을 적용했다.
- model outputs에 offset을 주고, 모든 trajectories에 점수를 매긴다. Parting with Misconceptions about Learning-based Vehicle Motion Planning 참고
- refinement module 추가하니, 사람 성능도 뛰어넘었다고 함
- baseline 어떤거 있는지 보고싶으면 논문의 7 page 참조해라.
- diffusion기반 baseline
- Generalizing Motion Planners with Mixture of Experts for Autonomous Driving 혹은 (논문)
- PDM like refinement module 도 함게 사용했다고 함
- Generalizing Motion Planners with Mixture of Experts for Autonomous Driving 혹은 (논문)
diffusion baselines
- 궁금하면 부록 B.1. 찾아봐라.
5.2. Ablation Studies
- Rethinking Imitation-based Planner for Autonomous Driving 에서는
state dropout decoder라는걸 써서,- 자차의 속도./가속도/각속도 정보를 안썼더니,
- 성능이 더 planning 성능이 더 좋았다고 합니다.
- 그래서, 우리 논문도 안썼습니다.
논문의 한계와 future work
scenario inputs
- 우리의 논문은
- vector화 된 map 정보 + 주변 agent들에 대한 detection 결과에 의존했음
- E2E와 비교했을 때, 우리의 방법은
- 정보 손실이 일어날 수 있음
- data processing 모듈이 추가적으로 필요함
Lateral Flexibility
- learning-based method는 큰 lateral movement가 필요할 때, 유연성에서 문제를 겪음
- 대조적으로, rule-based 방법은 이 문제에서 비교적 성능이 좋음. 그 이유는 그들은 reference trajectory를 이용하기 때문임
- 원인 중 하나: 데이터셋 문제임
- nuPlan 데이터셋 대부분이 직진 시나리오임
- 해결방안
- lateral movement가 많은 데이터셋 사용하기
- 강화학습 쓰기
- 차선 변경 행동을 하는데 도움이 되는 guidance 메커니즘 개발하기 등등
- 다른 문제로, 우리는 네트워크 output으로 planned trajectories를 출력하고 있는데, brake나 throttle로 출력하면 성능이 더 올라갈 것이다.
